首页
关于
Search
1
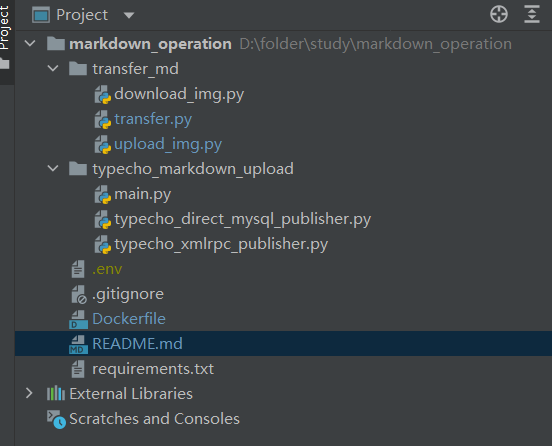
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
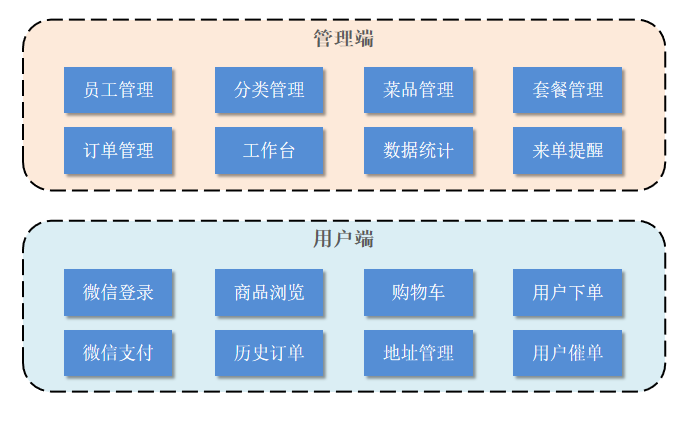
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
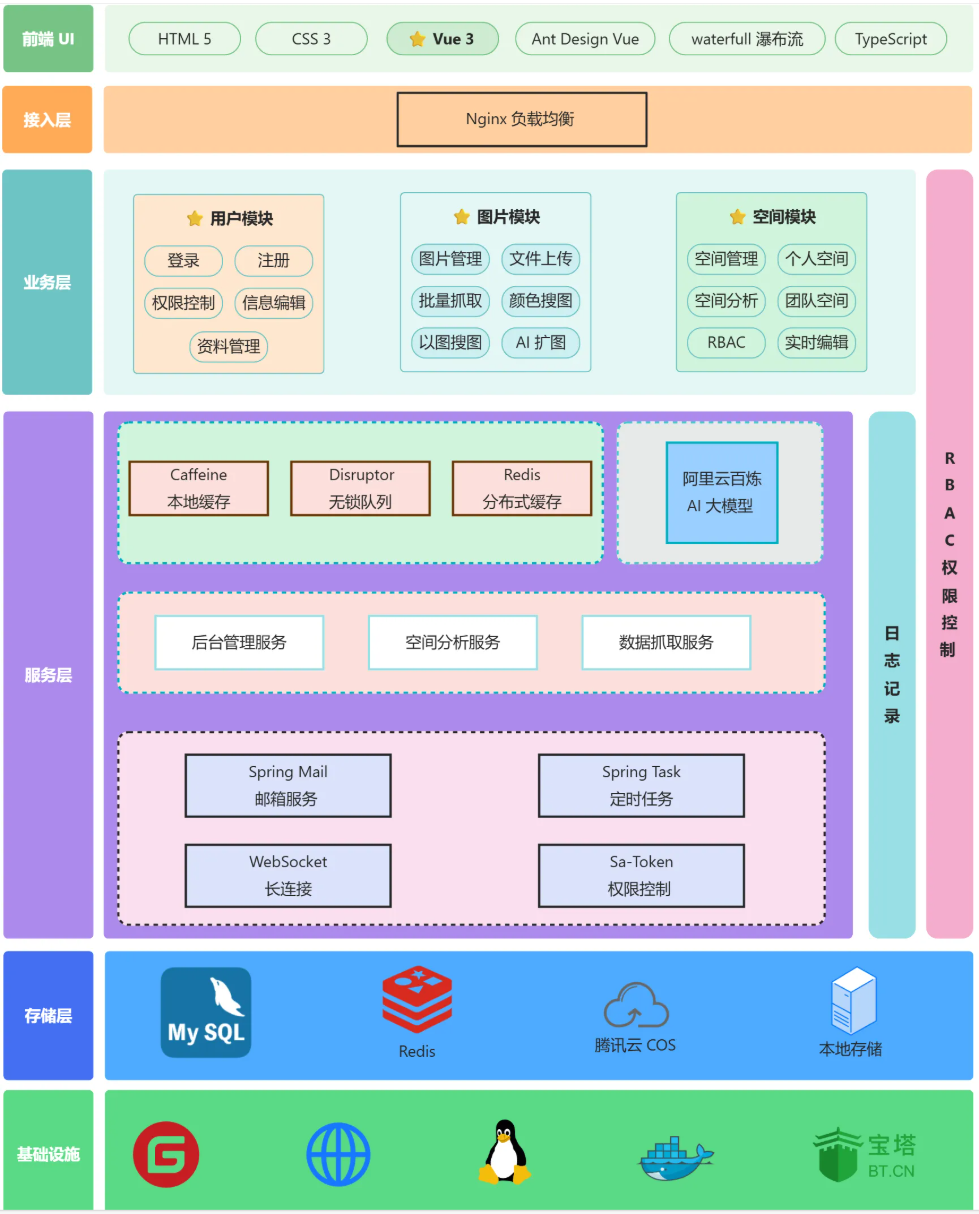
拼团设计模式
项目
1年前
0
12
0
推荐
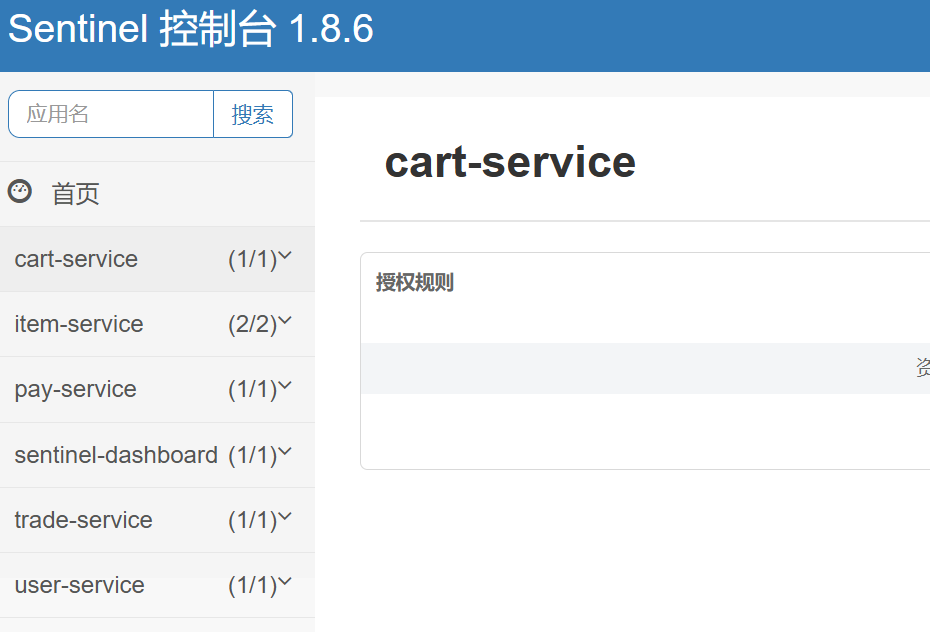
拼团交易系统
项目
1年前
0
41
1
推荐
Smile云图库
项目
1年前
0
60
0
热门文章
146 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
146
0
47 ℃
微服务
后端学习
1年前
0
47
0
43 ℃
苍穹外卖
项目
1年前
0
43
0
最新发布
2025-04-03
JAVA面试题
JAVA基础 JDK和JRE JDK 是开发环境,JRE 是运行环境。 JDK(Java Development Kit) = JRE + 开发工具(如 javac 编译器、调试器等); JRE(Java Runtime Environment) = JVM + 核心类库,只负责运行 Java 程序。 开发用 JDK,运行用 JRE。 Java 面向对象的四大特性 封装(Encapsulation) 含义:把数据和操作数据的方法封装在对象内部,对外只暴露必要的接口,隐藏实现细节。 好处:降低耦合、提高安全性、便于维护。 继承(Inheritance) 含义:子类继承父类,复用代码,同时可以扩展或重写父类功能。 好处:提高代码复用性,建立层次结构。 多态(Polymorphism) 含义:同一方法调用在不同对象上表现出不同的行为(编译时多态/运行时多态)。 好处:增强灵活性、可扩展性。 在框架层面的应用 封装:Spring 的 Bean的字段通常 private,通过 setter/getter 控制访问。 继承:模板方法模式提供了执行流程的骨架,子类必须继承才能扩展步骤。 而策略模式继承只是辅助,真正的精髓是组合和可替换性。 // 伪代码示例:JdbcTemplate的execute骨架 public abstract class JdbcTemplate { public final void execute() { // final防止子类重写算法骨架 getConnection(); // 固定步骤1 doStatement(); // 抽象方法,由子类实现 releaseConnection(); // 固定步骤2 } protected abstract void doStatement(); // 可变部分,子类实现 } 多态:多态的前提之一是继承/实现。Spring 的依赖注入(DI)注入接口类型,运行时由容器选择具体实现(Servcie)。多态强调的是运行时动态分派。 编译期用的是 接口引用,运行期执行的是 实现类方法,这就是多态。 JAVA创建对象的方法 1.运用反射 Class 类的 newInstance() 方法 MyClass obj = (MyClass) Class.forName("MyClass").newInstance(); 依赖无参构造方法; 2.运用反射 Constructor 类的 newInstance() 方法 Constructor<MyClass> cons = MyClass.class.getConstructor(); MyClass obj = cons.newInstance(); 这是 反射创建对象 的推荐方式; 可调用有参或无参构造函数; 3.调用对象的 clone() 方法 MyClass obj1 = new MyClass(); MyClass obj2 = (MyClass) obj1.clone(); clone() 创建的是一个新的对象(地址不同),但复制了字段值。 是一种基于已有对象复制的创建方式。 实现类必须实现 Cloneable 接口: class MyClass implements Cloneable { int x = 10; @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); // 调用 Object 的 clone() } } 4.使用 new 关键字创建 MyClass obj = new MyClass(); 说说 Java 中 HashMap 的原理? HashMap 允许 1 个 null key、多条 null value,因为单线程场景下没歧义。 为什么引入红黑树: 当hash冲突较多的时候,链表中的元素会增多,插入、删除、查询的效率会变低,退化成O(n)使用红黑树可以优化插入、删除、查询的效率,logN级别。 转换时机: 链表上的元素个数大于等于8 且 数组长度大于等于64; 链表上的元素个数小于等于6的时候,红黑树退化成链表。 JDK8为什么从"头插法"改为"尾插法" 头插法特点: 插入时不需要遍历链表 直接替换头结点 扩容时会导致链表逆序 多线程环境下可能产生死循环 尾插法改进: 避免扩容时的链表逆序 解决多线程环境下的潜在死循环问题 死循环产生场景 旧桶链表: A -> B -> C -> null 线程1 迁移时: 先拿到 A,放到新桶头部。 此时新桶是 A -> null。 线程 2 也在迁移,刚好也拿到 B,打算放到新桶头: 修改 B.next = A,新桶成了 B -> A -> null。 线程 1 继续迁移 B(因为它也在遍历旧链表): 此时它的 B.next 已经被线程2 改过了! 它会把 B 再放到新桶头,把指针一改,可能出现: A.next = B B.next = A 扩容 假设某个key的hash = ...10010b,旧容量n = 16: oldIndex = hash & 01111b = 2 扩容后 2n = 32: newIndex = hash & 11111b = (hash & 01111b) + (hash & 10000b) = oldIndex + 16(如果第 5 位是 1) 于是只需要 检查 hash 的第 5 位(10000b): 如果为 0 → newIndex = 2 如果为 1 → newIndex = 2 + 16 = 18 JAVA8及之后,扩容时只需要看 hash 的新高位,而不用重新计算哈希!!!这个 hash 会存进 Node 对象里,而不是每次都重新算。 扩容的时机:HashMap 的总元素个数,包括桶+链表+红黑树中的,而不只是看桶被占用了多少。 Java 中 ConcurrentHashMap 1.7 和 1.8 的区别? ConcurrentHashMap不允许null的key和value 在并发环境中,返回 null 可能同时表示两种情况: 1.key 不存在 2.key 对应的 value 是 null。无法区分这两种情况,会导致线程安全逻辑混乱。 HashMap 是非线程安全的,通常在单线程环境中使用,containsKey(key)可以区分“key 不存在”还是“value 为 null”。ConcurrentHashMap 在多线程环境下,即便先判断了 containsKey(key) 为 true,在你下一行 get(key) 时,另一个线程可能已经删除了这个 key,导致返回 null,从而产生逻辑混乱。 不同JDK版本的实现对比 1.数据结构 JDK1.7: 使用 Segment(分段锁) + HashEntry数组 + 链表 的数据结构 JDK1.8及之后: 使用 数组 + 链表/红黑树 的数据结构(与HashMap类似) 2.锁的类型与宽度 JDK1.7: 分段锁(Segment)继承了 ReentrantLock Segment容量默认16,不会扩容 → 默认支持16个线程并发访问 JDK1.8: 使用 synchronized + CAS 保证线程安全 空节点:通过CAS添加(put操作,多个线程可能同时想要将一个新的键值对插入到同一个桶中,这时它们会使用 CAS 来比较当前桶中的元素(或节点)是否已经被修改过。) 非空节点:通过synchronized加锁,只锁住该桶,其他桶可以并行访问。 3.渐进式扩容(JDK1.8+) 触发条件:元素数量 ≥ 数组容量 × 负载因子(默认0.75) 扩容过程: 创建2倍大小的新数组 线程操作数据时,逐步迁移旧数组数据到新数组 使用 transferIndex 标记迁移进度 直到旧数组数据完全迁移完成 == 和 equals 的区别是什么? 基本数据类型 ==:比较的是 值。 equals:基本数据类型(int、double、char 等)不是对象,没有 equals 方法,所以只能用 == 比较。 引用数据类型(对象)以及集合类 ==:比较的是 引用是否相同,即两个变量是否指向同一个对象。 equals:默认继承自 Object.equals,比较地址;但很多类(如 String、Integer、List)都 重写了 equals 方法,用于比较对象的 值。 List<String> list1 = Arrays.asList("A", "B"); List<String> list2 = Arrays.asList("A", "B"); System.out.println(list1 == list2); // false:不同对象 System.out.println(list1.equals(list2)); // true :元素顺序和值完全一致 HashSet<Point> 大坑 在 Java 中,有一个 HashSet<Point> points,Point 是自定义类,里面有两个成员 x 和 y。 如果我往里面 add 了一些 Point,之后想通过新构造一个同样 x、y 的 Point 来调用 points.remove(point),能否成功删除? HashSet和HashMap两者底层都用 哈希表(JDK8 之后是数组 + 链表 + 红黑树): 数组:用 hashCode() 定位桶(数组下标)。 链表/红黑树:解决哈希冲突。 扩容机制:负载因子超过阈值时,数组扩容并重新计算 hash。 HashSet.remove(Object o) 的底层流程: 计算哈希值 调用传入对象(o)的 hashCode() 方法,得到哈希值。 定位桶 根据哈希值取模,找到可能存放该对象的 桶。 如果 hashCode 不一样,元素直接定位到不同的桶,根本不会去比较 equals。 遍历桶中链表/红黑树 在对应的桶里,依次拿已有元素跟传入对象比较: 先比 hashCode(已经定位桶了,这里一般相同)。 再比 equals,确认是否是逻辑相等的对象。 删除成功 如果找到了 equals 为 true 的对象,就把它移除。否则返回 false。 contains也是类似的流程。 回答 默认情况下不能删除 自定义类 Point 没有重写 equals 和 hashCode,继承的是 Object 的实现。 这样比较时: equals 比较的是 引用地址,不是内容; hashCode 也是基于对象地址生成。 即使 x、y 相同,new Point(1,2) 和之前插入的对象也被视为 不同对象,所以 remove 会失败。 正确做法 必须同时重写 equals 和 hashCode,让两个 Point 在 x 和 y 相同的情况下被认为相等。 class Point { int x, y; Point(int x, int y) { this.x = x; this.y = y; } @Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof Point)) return false; Point p = (Point) o; return x == p.x && y == p.y; } //只要两个 Point 的 x 和 y 相同,它们的 hashCode 就相同。 @Override public int hashCode() { return Objects.hash(x, y); // Objects.hash() 是可变参数方法 Objects.hash(a, b, c); } } 这样,下面的代码才会返回 true: points.remove(new Point(1, 2)); // 成功删除 扩展 List<Point> 在使用contains和remove的时候,必须重写Point中的equals方法,但不用重写HashCode,因为用不上。 限流算法 1.固定窗口算法 将时间划分为固定的窗口(如1分钟),在每个窗口内对请求进行计数。 如果计数超过阈值,则后续请求被拒绝。 时间窗口重置时,计数器归零。 缺点: 在窗口切换的临界点附近,可能会遭遇两倍的流量冲击。 2.滑动窗口 滑动窗口将一个大窗口划分为多个更小的时间片(Slice)。每个时间片独立计数,窗口随着时间向前滑动,计算的是最近N个时间片内的总和。 3.漏桶算法 请求来是加++++ 想象一个底部有固定开口的桶: 请求像水一样以任意速率流入桶中。 如果水超过桶的容量,则溢出(拒绝请求)。 处理请求像水从桶底以恒定速率漏出。 // 伪代码概念 long capacity; // 桶的容量 long outflowRate; // 漏出的速率(如:100ms/个) long waterLevel; // 当前水位 long lastLeakTime; // 上次漏水的时间 synchronized boolean tryAcquire() { long now = System.currentTimeMillis(); // 1. 先计算上次到现在漏掉了多少水 long waterToLeak = (now - lastLeakTime) / outflowRate; waterLevel = Math.max(0, waterLevel - waterToLeak); lastLeakTime = now; // 2. 判断加水后是否会溢出 if (waterLevel < capacity) { waterLevel++; return true; } return false; } 4.令牌桶 请求来是减------- 想象一个以恒定速率生成令牌的桶: 令牌以固定速率放入桶中,直到桶满为止。 每个请求需要从桶中获取一个令牌才能被处理。 如果桶中有令牌,请求立即被处理(允许突发流量)。 如果桶中无令牌,则请求被拒绝或等待。 // 伪代码概念 long capacity; // 桶的容量 long refillRate; // 添加令牌的速率(如:每秒10个) long tokens; // 当前令牌数量 long lastRefillTime; // 上次添加令牌的时间 synchronized boolean tryAcquire() { long now = System.currentTimeMillis(); // 1. 计算上次到现在应该添加多少令牌 long tokensToAdd = (now - lastRefillTime) * refillRate / 1000; tokens = Math.min(capacity, tokens + tokensToAdd); // 桶不能超过容量 lastRefillTime = now; // 2. 取一个令牌 if (tokens > 0) { tokens--; return true; } return false; } 全局变量和局部变量 public class Person { // 实例变量(对象的属性,每个对象一份) String name; int age; // 静态变量(类变量,所有对象共享一份) static String species = "Human"; public void introduce() { // 局部变量(方法里的变量,每次调用方法时创建) String greeting = "Hello, my name is "; System.out.println(greeting + name + ", age " + age + ", species " + species); } } ① 实例变量(name, age) 定义位置:类中、方法外,且没有 static 修饰。 归属:属于对象,每个对象都有自己独立的副本。 存储位置:堆内存(Heap),随对象存活。 默认值:如果没赋值,自动有默认值(null、0 等)。 Person p1 = new Person(); p1.name = "Alice"; p1.age = 20; Person p2 = new Person(); p2.name = "Bob"; p2.age = 25; // p1 和 p2 的实例变量互不影响 System.out.println(p1.name); // Alice System.out.println(p2.name); // Bob p1、p2都是 局部变量(引用变量),存储在栈里。 p1 指向一个堆内存中新建的 Person 对象,这个对象有自己的实例变量 name = "Alice", age = 20。 ② 静态变量(species) 定义位置:用 static 修饰,写在类中。 归属:属于类本身,不属于某个对象。所有对象共享一份。 存储位置:方法区(JDK 8 以后在堆里的元空间)。 默认值:和实例变量一样,有默认值。 ③ 局部变量(greeting) 定义位置:在方法、构造方法、代码块里。 归属:只在当前方法或代码块有效。 存储位置:栈内存(Stack),随方法调用创建,方法结束销毁。 默认值:必须手动赋值,否则不能使用。 500. 什么是 Java 的 CAS(Compare-And-Swap)操作? CAS操作包含三个基本操作数: 内存位置(V):要更新的变量 预期原值(A):认为变量当前应该具有的值 新值(B):想要更新为的值 CAS 工作原理: 读取内存位置V的当前值为A 计算新值B 当且仅当V的值等于A时,将V的值设置为B 如果不等于A,则操作失败(通常重试) 伪代码表示: if (V == A) { V = B; return true; } else { return false; } ABA问题 假设一个共享变量 V = A,线程 T1 和 T2 同时操作: T1 读取 V 的值,得到 A,准备把它改成 C T2抢先执行: 把 V 改成 B 又把 V 改回 A T1继续执行 CAS: 发现 V 还是 A CAS 成功,把 V 改成 C 但实际上 V 已经被 T2 改过一次(A→B→A),T1 却完全察觉不到 解决方案:比较值 + 版本号,避免被 A→B→A 误导 class AtomicStampedValue { volatile int value; volatile int version; boolean compareAndSwap(int expectedValue, int expectedVersion, int newValue) { synchronized (this) { // 同时比较 value 和 version if (value == expectedValue && version == expectedVersion) { value = newValue; version++; // 每次修改版本号 +1 return true; } else { return false; } } } } JAVA异常体系 两大核心子类:Error 和 Exception Error (错误)指程序无法处理的严重问题,通常与代码编写无关,而是JVM运行时本身出现的错误。应用程序不应该尝试捕获(catch) 这些错误,因为通常无法恢复。 Exception(异常)指程序本身可以处理的问题,是开发者需要关心的异常。 Checked Exception:这些异常都继承自 Exception(但不是 RuntimeException),编译期必须显式处理:要么 try…catch 捕获,要么 throws 向上抛出。 类别 常见检查异常 典型触发场景 I/O 文件 IOException、FileNotFoundException 文件读写、网络传输、文件路径不存在 反射 / 类加载 ClassNotFoundException、IllegalAccessException Class.forName() 找不到类、无权限反射 数据库 JDBC SQLException 执行 SQL、数据库连接失败或语法错误 并发线程 InterruptedException 线程 sleep()、wait()、join() 被中断 解析 / 格式化 ParseException 解析日期、数字、文本格式错误 捕获: try { methodA(); } catch (IOException e) { ... } 向上抛出: public void methodB() throws IOException { methodA(); } // Thread.sleep 静态方法 Thread.sleep(1000); // 任何地方都能用,暂停当前线程 1 秒 // Object.wait 实例方法 synchronized(lock) { lock.wait(); // 必须先获得 lock 的监视器锁 } 补充:Compilation Error Compilation Error(编译错误) 是指 在程序编译阶段由编译器发现的问题。 分类 常见情况 举例说明 ① 语法错误 拼写错误、少了分号、括号不匹配 System.out.println("Hi")(缺少分号) ② 类型错误 不兼容的类型赋值 int x = "abc"; ③ 访问控制错误 访问 private 成员、包外访问 default 方法 obj.y (y 是 private) ⑧ 抽象类或方法使用错误 实例化抽象类 A obj = new A();(A 是 abstract) ⑨ 异常处理错误(受检异常) 未捕获或声明 Checked Exception new FileReader("a.txt"); 未加 try-catch 或 throws 补充:异常捕获顺序很重要 public class Test { public int div(int a, int b) { try { return a / b; } catch (Exception e) { System.out.println("Exception"); } catch (NullPointerException e) { System.out.println("NullPointerException"); } catch (ArithmeticException e) { System.out.println("ArithmeticException"); } finally { System.out.println("finally"); } return 0; } public static void main(String[] args) { Test demo = new Test(); System.out.println("商是:" + demo.div(9, 0)); } } 编译无法通过,因为catch 顺序要从小到大(子类 → 父类) Stream流 流的基本使用 Java 8 引入的 Stream API 是函数式编程风格的集合操作工具,能让你用声明式写法来处理数据。 1.创建流 List<String> list = List.of("a","b","c"); // 创建固定大小的列表,不能增删 //List<String> list = Arrays.asList("a","b","c"); //效果同上 Stream<String> s = list.stream(); 2.中间操作 filter:过滤 list.stream().filter(x -> x.startsWith("a")) map:转换 list.stream().map(s -> s.toUpperCase()) sorted:排序 list.stream().sorted() distinct:去重 list.stream().distinct() limit / skip:截取 list.stream().skip(1).limit(2) 函数的参数基本上都是函数式接口,可以用lambda表达式实现。 3.终止操作(常用的) forEach:遍历 list.stream().forEach(System.out::println); collect:收集 List<String> res = list.stream().collect(Collectors.toList()); count:计数 long c = list.stream().count(); 示例: import java.util.*; import java.util.stream.*; public class StreamDemo { public static void main(String[] args) { List<String> names = Arrays.asList("Tom", "Jerry", "Alice", "Tom", "Bob"); // 示例:取长度大于 3 的名字,去重,按字母逆序,转成大写,收集到 List List<String> result = names.stream() .filter(name -> name.length() > 3) // 筛选 .distinct() // 去重 .sorted((a, b) -> b.compareTo(a)) // 排序 .map(s -> s.toUpperCase()) // 转换 .collect(Collectors.toList()); // 收集 System.out.println(result); // [ALICE, JERRY] } } 使用注意点: 流只能用一次 Stream<String> s = names.stream(); s.forEach(System.out::println); s.forEach(System.out::println); // ❌ 报错:stream has already been operated upon or closed 补充:方法引用 引用现有方法作为 lambda 的实现,语法格式为: 类名或对象名::方法名 示例1:任意对象实例方法引用 class Person { private String name; public String getName() { return name; } } 我们想提取所有人的名字: List<String> names = people.stream() .map(Person::getName) .collect(Collectors.toList()); 等价于: .map(p -> p.getName()) 示例2:特定对象的实例方法引用 list.forEach(s -> System.out.println(s)); //等价于 list.forEach(System.out::println); 示例3:静态方法引用 Stream.of("1", "2", "3") .map(Integer::parseInt) .forEach(System.out::println); JAVA序列化 二进制序列化和 JSON 序列化 对比维度 二进制序列化(如 Protobuf、Kryo) JSON 序列化 数据格式 二进制(紧凑、不可读) 文本(可读、结构化) 体积大小 更小(无冗余字段名,高效编码) 更大(带字段名,格式冗余) 解析速度 更快(直接二进制解析,无词法分析) 较慢(需解析字符串) 可读性 不可读(需工具解析) 可读(直接查看) 适用场景 高性能 RPC(gRPC)、游戏、金融高频交易 REST API、前端交互、日志存储 序列化和反序列化在哪一层? 属于 应用层,解决应用数据的跨网络传输或持久化问题,例如: 将 Java 对象转为 JSON/二进制,通过 HTTP(REST API)或 TCP(Dubbo RPC)发送。 将 Redis 中的字符串反序列化为程序中的对象。 四种引用类型 引用类型 强度 GC 回收时机 常见用途 代码示例 强引用 (Strong Reference) 最强 永远不会被 GC 回收(除非失去所有强引用) 普通对象赋值 Object obj = new Object(); 软引用 (Soft Reference) 次强 内存不足时回收 内存敏感缓存(如图片缓存) Bitmap bitmap = new Bitmap();SoftReference<Bitmap> cache = new SoftReference<>(bitmap);bitmap = null; 弱引用 (Weak Reference) 较弱 下一次 GC 时回收 临时缓存、ThreadLocal.Key WeakReference<Metadata> metaRef = new WeakReference<>(data); 虚引用 (Phantom Reference) 最弱 GC 时回收,但需手动清理 对象销毁跟踪(如堆外内存回收) ReferenceQueue<File> queue = new ReferenceQueue<>(); PhantomReference<File> phantomRef = new PhantomReference<>(file, queue); Integer 为什么Java需要 Integer 这种封装类? 1)Java 是纯面向对象语言,很多集合类(如 ArrayList、HashMap)泛型只能存对象,不能存基本类型。 2)封装类提供了很多实用方法(如 Integer.parseInt、Integer.valueOf、进制转换、比较);继承自 java.lang.Object,可以使用 Object 的通用方法(如 equals()、hashCode()、toString()) 3)基本类型没有 null 值,封装类可以用 null 表示“缺失/未知”。 4)自动装箱/拆箱,int ↔ Integer 自动转换,提升了开发便利性。 Integer.valueOf()缓存机制 Integer.valueOf(int i) 在内部会先判断 i 是否在 [-128, 127] 之间。 如果在这个区间,会直接返回缓存池里的对象;否则才会 new 一个新的 Integer。 因为小整数是最常用的,比如循环下标、常量、集合大小等,可节省内存 Integer a = Integer.valueOf(100); Integer b = Integer.valueOf(100); System.out.println(a == b); // true(因为在缓存范围) Integer x = Integer.valueOf(200); Integer y = Integer.valueOf(200); System.out.println(x == y); // false(超出缓存范围,new 出来的对象) 补充1: new Integer(127) == new Integer(127) -》false,new Integer(...) 每次都会新建对象,不会走缓存机制 Long.valueOf(127L) == Long.valueOf(127L) -》true,和 Integer.valueOf() 类似,Long.valueOf() 也有缓存机制,默认缓存范围同样是 [-128, 127]。 补充2: Integer 的缓存池cache[]在 类加载时 就会被创建,缓存的对象存在 堆(Heap)中,默认范围是 [-128, 127]。之后所有 Integer.valueOf() 调用只是在 堆中的缓存数组中取引用,而不是重新 new。 String vs StringBuilder vs StringBuffer String:不可变,底层是 final char[],一旦创建内容不可改。 StringBuilder / StringBuffer:可变字符串,底层是一个可变数组,内容可以增删改。 区别: StringBuffer:线程安全,方法上加了 synchronized。 StringBuilder:非线程安全,但性能更快。 StringBuffer JDK 8 及以前:StringBuffer 内部维护一个 char[] 数组来存储字符。 JDK 9 及以后:Java 对 String、StringBuilder、StringBuffer 做了优化,引入了 byte[] + coder(编码标识) 的实现,称为 Compact Strings。 byte[] 用来存储字符内容。 coder 表示编码方式(0 = Latin1,1 = UTF-16)。 这样在大多数只包含拉丁字符的字符串里可以节省一半的内存。 面试官:“StringBuffer 会不会直接引用常量池里的字符串?” 你: “不会。字面量 "abc" 会进入常量池,但 StringBuffer 在构造时会把 "abc" 的字符复制到自己内部的数组里。这样它就可以在堆里维护一个可变的副本,而不会破坏常量池的不变性。如果它直接用常量池对象,那修改 sb 的时候就会污染常量池,导致整个 JVM 中所有引用 "abc" 的地方都被影响,这是设计上不允许的。” StringBuffer sb = new StringBuffer("abc"); sb.append("d"); // 现在变成 "abcd" "abc" 作为字面量,一定在字符串常量池里。 sb.append("d") 的过程是: 取出字面量 "d"(常量池已有)。 把 'd' 加到 sb 的内部数组中(堆内存)。 最终结果 "abcd" 只存在于 sb 的堆内数组里,不会自动放入常量池。 字符串常量池 String a = "1"; String b = "1"; 变量 a和变量 b会指向同一个内存中的 String对象。 原理:常量池中有,就直接返回其引用;没有,就创建一个放进去再返回。 存放位置: Java 7 之前:字符串常量池逻辑上属于方法区(Method Area) 的运行时常量池(Runtime Constant Pool) 的一部分。而方法区的具体实现是 永久代(PermGen)。 问题:永久代大小有限且难以调整,容易发生 OutOfMemoryError: PermGen space。 Java 7 开始:字符串常量池被从永久代移动到了 Java 堆(Heap) 中。 Java 8 及以后:永久代被彻底移除,取而代之的是元空间(Metaspace)(用于存类元信息、方法码等)。而字符串常量池依然留在堆中。 注意:逻辑上一直属于方法区(运行时常量池的一部分) 常见操作:intern() 方法 String s1 = new String("abc"); String s2 = s1.intern(); String s3 = "abc"; System.out.println(s1 == s2); // false System.out.println(s2 == s3); // true String s1 = new String("abc"); 创建了 两个对象(常量池 + 堆各一个): "abc" 常量在类加载时进入字符串常量池; s1 是一个新建的堆中对象; String s2 = s1.intern(); 如果池中已有 "abc",则返回池中的引用; 如果没有,就把这个堆中的对象引用放进常量池,以后重用。 LeetCode 中常见操作类型与推荐结构 需求类型 推荐数据结构 原因 随机访问(按索引 get/set) ArrayList / 原生数组 int[] O(1) 访问,最快 在尾部插入或删除 ArrayList / ArrayDeque 尾部操作快,连续内存友好 在头部插入或删除 LinkedList / ArrayDeque ArrayList 头插删除太慢(O(n)) 在中间频繁插入、删除 LinkedList(前提是已有节点引用) 直接修改指针,不移动数组 队列(FIFO) ArrayDeque(首选) / LinkedList ArrayDeque 性能更好 栈(LIFO) ArrayDeque(首选) 比 Stack 更高效、线程安全性不强制 需要排序、二分、索引定位 ArrayList / 数组 支持 Collections.sort()、二分查找 双端队列 ArrayDeque 头尾操作都是 O(1) 频繁查找是否存在 HashSet / HashMap O(1) 查找,比 List 快得多 算法中直接用LinkedList比较少。 JUC多线程并发 线程的生命周期 新建状态(New):调用 new Thread() 时 ,线程对象被创建,但尚未调用 start() 方法。 就绪状态(Runnable):调用了 start() 方法后,线程进入就绪状态,等待被 JVM 的线程调度程序分配 CPU 时间片。 (注意,start后不一定马上运行!!要等时间片) 运行状态(Running):线程获得 CPU 时间片后开始执行 run() 方法中的代码。 阻塞状态(Blocked):线程因某些原因(如等待资源)进入阻塞状态,暂时停止执行。 Blocked:等待锁(如同步块) Waiting:无限期等待(如 wait()、join()) Timed Waiting:有限期等待(如 sleep(ms)、wait(ms)) 终止状态(Terminated):线程执行完毕或被notifyAll()强制终止。 wait、notify、notifyall wait() —— 线程主动让出锁并等待 让当前线程主动释放对象锁,进入等待状态(Waiting)。 等待其他线程调用该对象的 notify() 或 notifyAll() 来唤醒。 notify() —— 唤醒一个等待线程 唤醒一个正在 wait() 的线程,使其从等待队列转入锁的争用队列。 被唤醒的线程还需要重新获取锁才能继续执行。 notifyAll() —— 唤醒所有等待线程 唤醒所有在该对象上等待的线程; 所有线程都会从等待队列移动到争用队列; 只有拿到锁的线程能继续执行,其他会重新进入等待。 场景:消费者和生产者模型中,如果用 notify() 可能只唤醒了同类线程(比如生产者唤醒另一个生产者),造成假死。 线程池 线程池创建与原理 1.通过 Executors 工具类 ExecutorService pool = Executors.newFixedThreadPool(5); 固定线程数,任务多时放在无界队列里排队。适合 任务量大但稳定 的场景。 2.通过 ThreadPoolExecutor 创建(推荐) import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.concurrent.*; @Configuration public class ThreadPoolConfig { @Bean public ThreadPoolExecutor threadPoolExecutor() { return new ThreadPoolExecutor( 2, // corePoolSize 核心线程数 5, // maximumPoolSize 最大线程数 60, // keepAliveTime 空闲线程存活时间 TimeUnit.SECONDS,// 时间单位 new ArrayBlockingQueue<>(10), // 队列 Executors.defaultThreadFactory(), // 线程工厂 new ThreadPoolExecutor.AbortPolicy() // 拒绝策略 ); } } 创建线程池推荐项目里全局复用这一个线程池 使用 import org.springframework.stereotype.Service; import java.util.concurrent.ThreadPoolExecutor; @Service public class MyService { private final ThreadPoolExecutor threadPoolExecutor; public MyService(ThreadPoolExecutor threadPoolExecutor) { //构造器注入 this.threadPoolExecutor = threadPoolExecutor; } public void doSomething() { threadPoolExecutor.execute(() -> { System.out.println("任务执行中:" + Thread.currentThread().getName()); }); } } 为什么阿里巴巴 Java 开发手册里禁止直接用 Executors? 答:因为 Executors 创建的线程池容易导致 任务队列无限膨胀(OOM),比如 newFixedThreadPool 用的是无界队列。用 ThreadPoolExecutor 可以自己设定队列大小,更安全 3.ForkJoinPool JAVA线程池工作原理 当调用 execute(Runnable task) 提交任务时,逻辑大致是这样的: 如果当前线程数 < corePoolSize 直接新建一个线程来处理任务。 否则(线程数 ≥ corePoolSize) 尝试把任务放进工作队列(workQueue)。 如果队列没满 → 入队成功,等候线程来取。 如果队列已满 判断当前线程数是否 < maximumPoolSize: 如果是 → 新建一个非核心线程处理任务。 如果不是 → 执行拒绝策略。 核心线程的默认行为:不会因为空闲就被回收,即使没有任务,也会一直存在。非核心线程空闲时间超过 keepAliveTime 才会被回收。 拒绝策略 策略类 名称 行为说明 AbortPolicy (默认) 中止策略 直接抛出 RejectedExecutionException 异常 🚫 CallerRunsPolicy 调用者运行策略 由提交任务的线程(即调用 execute() 的线程)自己执行任务 🧵 DiscardPolicy 丢弃策略 直接丢弃该任务,不抛异常 ❌ DiscardOldestPolicy 丢弃最旧策略 丢弃队列中最早的一个任务,然后尝试执行当前任务 🔁 如果用无界队列,会怎样? workQueue.offer(task) 永远返回 true(队列永远不满); 因此永远不会进入创建非核心线程的分支; 所以线程数固定在 corePoolSize。 如果生产速度 > 消费速度,队列会持续增长 无界队列不断堆积任务对象,最终撑爆内存 等待队列过长,任务响应越来越慢 如何知道线程池中线程运行状态 由于任务的执行是在另一个线程中异步进行的,所以我们在提交任务的线程(主线程)中尝试用 try-catch 是捕捉不到的。我们需要使用一些回调机制或定制化手段来捕获和处理异常。 try { threadPoolExecutor.execute(() -> { // 任务代码 int i = 1 / 0; // 故意制造异常 }); } catch (Exception e) { System.out.println("捕获异常: " + e); } 这样是无法捕捉异常的!!! **方案 A:**通过 Future捕获异常(推荐) ThreadPoolExecutor executor = new ThreadPoolExecutor( 2, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>() ); Future<?> future = executor.submit(() -> { int a = 1 / 0; // 抛出 ArithmeticException }); try { future.get(); // 这里会抛出 ExecutionException,其 cause 是真正的异常 } catch (ExecutionException e) { Throwable realException = e.getCause(); System.out.println("捕获到异常: " + realException.getMessage()); } catch (InterruptedException e) { Thread.currentThread().interrupt(); // 恢复中断状态 } **方案 B:**重写 afterExecute,全局捕获 自定义 ThreadPoolExecutor,重写 afterExecute方法捕获异常(包括 submit()提交的任务)。 public class CustomThreadPoolExecutor extends ThreadPoolExecutor { // 构造器省略... @Override protected void afterExecute(Runnable r, Throwable t) { super.afterExecute(r, t); if (t == null && r instanceof Future<?>) { try { Future<?> future = (Future<?>) r; if (future.isDone()) { future.get(); // 触发 ExecutionException } } catch (ExecutionException e) { t = e.getCause(); // 获取真实异常 } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } if (t != null) { System.err.println("线程池捕获到异常: " + t.getMessage()); // 这里可记录日志、告警或重启任务 } } } // 使用自定义线程池 ThreadPoolExecutor executor = new CustomThreadPoolExecutor(...); executor.submit(() -> { int a = 1 / 0; }); // 异常会被 afterExecute 捕获 这里重写了 afterExecute,无论是普通 Runnable 还是 Callable,都能统一捕获异常,并打印是哪一个线程出问题。 方案C:在任务内部 try-catch (但是主线程是无感的,不太符合!!!) executor.submit(() -> { try { int a = 1 / 0; } catch (Exception e) { System.out.println("任务内部处理异常: " + e.getMessage()); // 可记录日志、重试或补偿 } }); 虚线程 定义:虚线程是 JDK21 为了解决高并发下线程数量瓶颈而引入的一种 轻量级线程。 虚线程前,主要靠线程池+IO多路复用来实现高并发连接,缺点是编程复杂!!! 区别:传统的线程(称为平台线程)是直接映射到操作系统内核线程;而虚线程则由 JVM 调度,并且不与内核线程一一绑定。 平台线程:笨重 → 每个线程都有 1MB 默认栈内存,数量有限(几千 ~ 几万),否则会内存溢出 虚线程:轻量 → 几乎没有额外内存开销,可以轻松创建百万级。 作用: 1)当虚线程执行阻塞调用(如 IO)时,JVM 会把它挂起,释放底层内核线程,不会浪费资源。 2)不用像以前那样必须写异步回调(CompletableFuture/Reactive),同步代码就能写高并发逻辑。 public class VirtualThreadDemo { public static void main(String[] args) throws InterruptedException { try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { for (int i = 0; i < 1_000_000; i++) { int id = i; executor.submit(() -> { Thread.sleep(1000); // 看似阻塞,但虚线程会挂起,不占用内核线程 System.out.println("Task " + id + " done"); return null; }); } } } } 普通线程1000000个线程sleep,系统几乎撑不住(线程数上限、内存爆炸)。 用虚线程JVM 碰到虚线程阻塞调用(如 sleep、IO 等),会把虚线程 挂起,把底层 OS 线程还给调度器,到点后再把虚线程唤醒,继续执行。 虚线程和epoll协同 虚线程和 epoll 并不冲突,而是协同:虚线程在遇到阻塞 IO 时会挂起(unmount),JVM 在底层通过 epoll 等多路复用机制等待 IO 事件,当 IO 就绪后再恢复虚线程执行。 虚线程更高级,epoll是底层。 用户代码层(同步写法) ┌──────────────────────────────────────┐ │ VirtualThread: │ │ out.println(); │ │ String line = in.readLine(); ← 阻塞调用点 └──────────────────────────────────────┘ ↓ JVM 调度器检测阻塞 ↓ ┌──────────────────────────────────────┐ │ JVM IO Poller: 使用 epoll_wait 等待 │ │ - 注册 fd → epoll_ctl │ │ - 等待事件 → epoll_wait │ └──────────────────────────────────────┘ ↓ IO 就绪(EPOLLIN) ↓ ┌──────────────────────────────────────┐ │ JVM 调度器唤醒虚线程 │ │ 恢复 Continuation → 继续执行 │ └──────────────────────────────────────┘ synchronized synchronized (obj) { // 临界区代码 } 锁升级 偏向→轻量级→重量级是 synchronized 的 JVM 优化路径,锁的升级方向是不可逆的 第一阶段:无锁 -> 偏向锁 (适用于:几乎无竞争): 场景:假设一个同步代码块或方法,在绝大多数情况下都只有一个线程在访问。 当一个线程第一次访问同步块时,它会通过 CAS 操作,将线程ID 写入对象头的 Mark Word。 对象进入“偏向锁”状态,表示此锁偏向于该线程。 同一线程再次进入时,只比较 Mark Word 中的线程 ID;匹配则直接进入;不匹配则撤销偏向锁,升级为轻量级锁。 **第二阶段:**偏向锁 -> 轻量级锁 触发条件:有另外一个线程来尝试获取这个锁。 1)偏向锁被撤销后,锁对象进入轻量级锁状态。 2)线程在进入同步块时,会在自己栈帧中创建一份 锁记录(Lock Record),并通过 CAS 尝试将对象头的 Mark Word 更新为指向该锁记录的指针。 3)如果 CAS 成功,则该线程成功获取轻量级锁。 4)若 CAS 失败,表示锁已被其他线程持有,此时线程不会立即阻塞,而是**自旋(Spin)**等待 通过多次重试 CAS 操作,期望前一个线程很快释放锁 如果在短时间内获取到锁,可避免线程挂起与唤醒的系统开销 **第三阶段:**轻量级锁 -> 重量级锁 触发条件: 当自旋失败次数超过阈值,或有多个线程同时参与竞争时。 现在抢东西的人太多了,文明排队的方式(自旋)太浪费体力(CPU)且效率低下。于是叫来了管理员(操作系统内核)来维护秩序,没拿到的人先去睡觉(挂起),等有了再被叫醒。 锁消除 含义:JIT 编译器在运行时即时编译优化时,通过逃逸分析发现某段同步代码块里的锁对象 不会被多线程共享,就会把这把锁直接“消除”,不生成加锁字节码。 结果:虽然你写了 synchronized,但实际运行时不会真的加锁。 public String concatString(String s1, String s2) { StringBuffer sb = new StringBuffer(); // 局部变量,不会逃逸出方法 sb.append(s1).append(s2); return sb.toString(); } StringBuffer.append() 本身是 synchronized 方法。 但是这里的 sb 是局部变量,不可能被其他线程访问。 JIT 通过逃逸分析发现 sb 不会“逃逸”出当前方法 → 就会触发 锁消除,把 synchronized 去掉。 实际运行时,这个方法的执行效率就和 StringBuilder 一样。 volatile 在 Java 中,volatile 是一个 轻量级同步机制,主要有两个作用: 保证可见性:当一个线程修改了 volatile 变量的值,其他线程能立即“看到”最新值。 禁止指令重排序:保证对该变量的读写操作不会和前后的指令发生重排序,从而在多线程下避免出现“乱序执行”的问题。(双重检查单例模式中) 原理: JVM 底层通过 内存屏障(Memory Barrier) 来实现这两个效果: 可见性: volatile 写操作 → 编译器会在写操作 前 插入一个 StoreStore 屏障 在写操作 后 插入一个 StoreLoad 屏障 这样能保证:写之前的所有操作对其他线程可见,写之后其他线程能立刻读到。 volatile 读操作 → 在读操作 前 插入一个 LoadLoad 屏障 在读操作 后 插入一个 LoadStore 屏障 这样能保证:读之后的所有操作一定拿到的是最新值,不会被重排到读之前。 禁止重排序: 内存屏障同时约束了编译器和 CPU 的优化,不允许把 volatile 读写与其前后的操作交换顺序。 happens-before: volatile 写 → happens-before → 后续对该 volatile 变量的读。也就是说,线程 A 写入一个 volatile 变量,线程 B 之后读取到这个 volatile 变量时,能看到 A 写入之前的所有修改。 normalVar = 1; // 普通写 flag = true; // volatile 写 根据 happens-before 规则,其他线程只要看到 flag == true(volatile 读),就一定能看到 normalVar = 1。 volatile 不能保证原子性,比如 count++ 这样的复合操作仍然存在线程安全问题。 ThreadLocal 每个线程内部维护一个私有变量 ThreadLocalMap,每个 ThreadLocal 对象 作为键(Key),存储的值(Value)由 ThreadLocalMap管理。 假设你在代码中定义了两个 ThreadLocal 变量并设置值: ThreadLocal<String> userContext = new ThreadLocal<>(); ThreadLocal<Integer> requestId = new ThreadLocal<>(); userContext.set("Alice"); // 存储第一个字段 requestId.set(123); // 存储第二个字段 底层存储结构: // 伪代码展示当前线程的存储结构 Thread.currentThread().threadLocals = { // Entry[] table (ThreadLocalMap 内部数组) [0]: Entry(userContext, "Alice"), // Key 是 ThreadLocal 对象,Value 是存储的值 [1]: Entry(requestId, 123) }; Entry的 Key(ThreadLocal 对象)是弱引用,避免内存泄漏(但 Value 是强引用,需手动 remove())。 void someMethod() { ThreadLocal<Long> localVar = new ThreadLocal<>(); // 局部变量(强引用) localVar.set(100L); } // 方法结束,localVar 被回收(key 变成 null) 这样的话,key会在下一次GC的时候被回收。 try { userContext.set("Alice"); // ...业务逻辑 } finally { userContext.remove(); // 必须清理! } 在 Spring Boot 中,通过 HandlerInterceptor实现 ThreadLocal 的安全清理。 具体做法是:在拦截器的 preHandle方法中设置 ThreadLocal 值,在 afterCompletion方法(无论请求成功或异常都会触发)中调用 remove()彻底清理。这样能确保线程池中的线程被重用时,不会残留脏数据。 不调用 remove()的后果 Key(ThreadLocal 对象):由于 ThreadLocalMap.Entry的 Key 是弱引用(WeakReference),当 ThreadLocal对象失去强引用时(如置为 null),Key 会在下一次 GC 时被回收。 Value(存储的值):Value 是强引用,即使 Key 被回收,Value 仍会保留在 ThreadLocalMap中,除非显式调用 remove()或线程终止。 CountDownLatch 字面意思就是 “倒计数锁存器”。 作用:让一个或多个线程 等待,直到一组操作完成。 内部维护一个 计数器(初始值由构造函数指定),每次调用 countDown() 就减 1,当计数器减到 0 时,所有在 await() 上等待的线程都会被唤醒。 使用场景:1)主线程等待子任务完成 CountDownLatch latch = new CountDownLatch(3); for (int i = 0; i < 3; i++) { new Thread(() -> { try { // 执行任务 } finally { latch.countDown(); // 完成一个任务 } }).start(); } latch.await(); // 主线程阻塞,直到3个子任务都完成 System.out.println("所有任务完成,主线程继续"); 2)多个线程等待统一起点 CountDownLatch latch = new CountDownLatch(1); for (int i = 0; i < 10; i++) { new Thread(() -> { try { latch.await(); // 等待统一起跑 System.out.println(Thread.currentThread().getName() + " 开始执行"); } catch (InterruptedException e) {} }).start(); } Thread.sleep(2000); System.out.println("主线程发令"); latch.countDown(); // 所有等待的线程同时被唤醒 AtomicLong 在多线程开发中,AtomicLong 是最常见、最实用的原子类之一。它提供高性能的无锁原子操作,非常适合管理计数、金额、库存等需要保证一致性的数值。 对单个变量实现无锁的原子操作 AtomicLong 示例:多线程安全计数器 import java.util.concurrent.atomic.AtomicLong; public class AtomicLongDemo { private static final AtomicLong counter = new AtomicLong(0); public static void main(String[] args) throws InterruptedException { int threadCount = 10; Thread[] threads = new Thread[threadCount]; for (int i = 0; i < threadCount; i++) { threads[i] = new Thread(() -> { // 每个线程自增1000次 for (int j = 0; j < 1000; j++) { counter.incrementAndGet(); // 原子 +1 } }, "线程-" + i); threads[i].start(); } // 等所有线程执行完 for (Thread t : threads) t.join(); System.out.println("最终计数值:" + counter.get()); } } AtomicLong 常用方法速查表 方法名 说明 返回值 示例 get() 获取当前值 当前值 long v = counter.get(); set(long newValue) 设置新值(非原子操作) 无 counter.set(100); getAndSet(long newValue) 原子地设置新值,并返回旧值 旧值 long old = counter.getAndSet(50); compareAndSet(long expect, long update) 如果当前值等于预期值,则更新为新值 true / false counter.compareAndSet(100, 200); incrementAndGet() 原子地加 1,返回新值 新值 counter.incrementAndGet(); // ++i getAndIncrement() 原子地加 1,返回旧值 旧值 counter.getAndIncrement(); // i++ addAndGet(long delta) 原子地加上 delta,返回新值 新值 counter.addAndGet(10); // +=10 getAndAdd(long delta) 原子地加上 delta,返回旧值 旧值 counter.getAndAdd(10); // +=10,但返回加前值 getAndXxx() 形式的返回 旧值 XxxAndGet() 形式的返回 新值 compareAndSet() 是实现“无锁并发”的核心操作 getAndAdd() 是存款/累计类操作最常用的方法 如何多线程循环打印1-100数字? public class AlternatePrint { private static int count = 1; private static final Object lock = new Object(); public static void main(String[] args) { new Thread(() -> { while (count <= 100) { synchronized (lock) { if (count % 2 == 1) { System.out.println(Thread.currentThread().getName() + ": " + count++); lock.notify(); } else { try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } }, "Thread-1").start(); new Thread(() -> { while (count <= 100) { synchronized (lock) { if (count % 2 == 0) { System.out.println(Thread.currentThread().getName() + ": " + count++); lock.notify(); } else { try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } }, "Thread-2").start(); } } 线程间是如何通信的? 共享内存:线程通过共享变量通信,需要同步机制保证可见性和原子性。比如 volatile、synchronized、Lock、wait/notify。 消息传递:线程通过消息队列或管道传递数据,比如 BlockingQueue、PipedStream、并发工具类。 在 Java 里,最常见的做法是用 volatile 做标志位通知,或者用 BlockingQueue 实现生产者-消费者模型。 共享内存方式 —— 用 volatile 做标志位 public class VolatileFlagDemo { private static volatile boolean running = true; public static void main(String[] args) throws InterruptedException { // 工作线程 Thread worker = new Thread(() -> { while (running) { System.out.println("Working..."); try { Thread.sleep(500); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } System.out.println("Stopped."); }); worker.start(); // 主线程 2 秒后修改标志位 Thread.sleep(2000); running = false; System.out.println("Main thread set running=false"); } } 消息传递方式 —— 用 BlockingQueue 实现生产者-消费者 生产者调用 queue.put(msg) 把消息放入队列: 如果队列满了,会阻塞,直到有空间。 消费者调用 queue.take(): 如果队列为空,消费者会阻塞,直到有新消息进入。 import java.util.concurrent.*; public class BlockingQueueDemo { private static final BlockingQueue<String> queue = new LinkedBlockingQueue<>(); public static void main(String[] args) { // 生产者线程 Thread producer = new Thread(() -> { try { for (int i = 1; i <= 5; i++) { String msg = "Message-" + i; queue.put(msg); // 放入队列 System.out.println("Produced: " + msg); Thread.sleep(300); } } catch (InterruptedException e) { Thread.currentThread().interrupt(); } }); // 消费者线程 Thread consumer = new Thread(() -> { try { while (true) { String msg = queue.take(); // 从队列取出 System.out.println("Consumed: " + msg); } } catch (InterruptedException e) { Thread.currentThread().interrupt(); } }); producer.start(); consumer.start(); } } 前面的多线程循环打印1-100,线程之间通过 共享变量 count 来传递状态,同时用 wait/notify 来协调线程的执行顺序,属于共享内存模型 下的通信。 CountDownLatch内部其实也是用 共享内存 + AQS,线程通过 await() 进入阻塞队列,等计数器归零后被唤醒,但从使用者角度,它更像是 消息/信号通知 的抽象。 Reentrant Reentrant是可重入锁,可重入是指:同一个线程可以重复获取自己已经持有的锁,不会死锁。 import java.util.concurrent.locks.ReentrantLock; public class Example { private final ReentrantLock lock = new ReentrantLock(); public void methodA() { lock.lock(); // 第一次获取锁 try { System.out.println("Method A"); methodB(); // 调用 methodB,会再次获取锁(可重入) } finally { lock.unlock(); // 释放锁 } } public void methodB() { lock.lock(); // 第二次获取锁(可重入) try { System.out.println("Method B"); } finally { lock.unlock(); // 释放锁 } } public static void main(String[] args) { Example example = new Example(); example.methodA(); // 测试调用 } } 但它是独占锁,同一时刻只允许一个线程持有锁。 AQS AQS 是作为构建各种锁/同步器的基础。 基于它实现的有: 独占锁:ReentrantLock 共享锁:Semaphore、CountDownLatch 读写锁:ReentrantReadWriteLock 其他同步工具:FutureTask 等 获取资源失败的线程 → 被放入 等待队列(FIFO)。 唤醒机制 → 当资源释放时,队列中的线程按顺序被唤醒,尝试再次获取资源。 公平/非公平 公平/非公平 → AQS 提供了公平/非公平两种获取策略,子类可选择。 公平锁(Fair): 按照 FIFO 顺序 获取锁,谁先来谁先拿。线程必须排队,避免“插队”。 非公平锁(NonFair): 允许线程在 CAS 抢占时“插队”。锁释放时,队头线程会被唤醒尝试获取,但与此同时,外部新来的线程也能立刻尝试 CAS 抢占。 独占模式 vs 共享模式 独占模式:同一时刻只能有一个线程获取资源。 代表:ReentrantLock、ReentrantReadWriteLock.WriteLock 共享模式:同一时刻多个线程可以共享资源。 代表:Semaphore、CountDownLatch、ReentrantReadWriteLock.ReadLock 示例1:Semaphore Semaphore semaphore = new Semaphore(3); // 最多允许 3 个线程同时访问 Runnable task = () -> { try { semaphore.acquire(); // 请求许可,拿不到就阻塞 System.out.println(Thread.currentThread().getName() + " 获取许可,执行中"); Thread.sleep(1000); // 模拟工作 } catch (InterruptedException e) { e.printStackTrace(); } finally { semaphore.release(); // 释放许可 } }; // 启动 10 个线程 for (int i = 0; i < 10; i++) { new Thread(task, "线程-" + i).start(); } 最多只能看到3 个线程同时在执行;其他线程会阻塞,直到前面的释放许可。 示例2:ReentrantReadWriteLock ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock(); ReentrantReadWriteLock.ReadLock readLock = rwLock.readLock(); ReentrantReadWriteLock.WriteLock writeLock = rwLock.writeLock(); Runnable readTask = () -> { readLock.lock(); try { System.out.println(Thread.currentThread().getName() + " 读数据中..."); Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { readLock.unlock(); } }; Runnable writeTask = () -> { writeLock.lock(); try { System.out.println(Thread.currentThread().getName() + " 写数据中..."); Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } finally { writeLock.unlock(); } }; // 启动多个读线程 for (int i = 0; i < 3; i++) { new Thread(readTask, "读线程-" + i).start(); } Thread.sleep(200); // 稍等一会儿启动写线程 new Thread(writeTask, "写线程").start(); 多个读线程可以并行执行;写线程必须等待所有读线程完成;读线程也会在写线程执行时阻塞。 AQS为什么用双向链表 最主要的原因是为了支持高效的节点移除操作。在 AQS 的实现中,线程可能会因为超时、中断等原因需要从队列中移除。 在单向链表中,要删除一个节点,必须从头开始遍历找到它的前驱节点,时间复杂度是 O(n)。而双向链表可以直接通过前驱指针(prev)快速定位前驱节点,实现 O(1) 时间复杂度的节点移除。 手撕限流器 import com.google.common.util.concurrent.RateLimiter; import java.util.concurrent.ConcurrentHashMap; public class IpRateLimiterGuava { private final ConcurrentHashMap<String, RateLimiter> ipRateLimiters = new ConcurrentHashMap<>(); private final double permitsPerSecond = 10.0; // 每秒10个许可 public boolean allowAccess(String ip) { // 为每个IP创建独立的RateLimiter(懒加载) RateLimiter limiter = ipRateLimiters.computeIfAbsent(ip, k -> RateLimiter.create(permitsPerSecond)); return limiter.tryAcquire(); // 尝试获取许可 } public static void main(String[] args) { IpRateLimiterGuava limiter = new IpRateLimiterGuava(); String ip = "192.168.1.1"; for (int i = 0; i < 15; i++) { boolean allowed = limiter.allowAccess(ip); System.out.println("Access " + i + ": " + (allowed ? "Allowed" : "Denied")); try { Thread.sleep(50); } catch (InterruptedException e) { e.printStackTrace(); } } } } JAVA高级 垃圾回收 垃圾回收算法 1)标记-清除算法 首先标记出所有需要回收的对象。统一回收所有被标记的对象。 缺点:内存碎片化 2)标记-整理算法 与“标记-清除”一样,标记所有需要回收的对象。让所有存活的对象都向内存空间的一端移动,然后直接清理掉边界以外的内存。 避免了内存碎片,但是移动存活对象并更新所有引用地址是一个负重操作。 3)复制算法 将可用内存按容量分为大小相等的两块,每次只使用其中一块。当这一块用完了,就将还存活着的对象复制到另一块上面,然后再把已使用过的内存空间一次清理掉。 没有内存碎片,但是可用内存缩小为原来的一半。 垃圾回收器 1)CMS:并发标记清除器 回收过程(仅针对老年代,与ParNew搭配使用): 初始标记: 动作:标记与 GC Roots 直接关联 的对象。 特点:速度极快,但需要 “Stop The World”。 并发标记: 动作:从初始标记的对象开始,进行可达性分析,标记所有存活对象。 特点:与用户线程并发执行,耗时较长,但不会暂停应用。 重新标记: 动作:修正并发标记期间,因用户程序继续运行而导致标记产生变动的那部分对象。 特点:需要 “Stop The World”,但采用了优化算法(如增量更新),比初始标记稍长,但远短于并发标记。 并发清除: 动作:清理死亡对象,回收内存空间。 特点:与用户线程并发执行。回收期间,用户线程仍可创建新对象。 特点:CMS主要负责的是 老年代,以并发、低停顿为目标,通过多阶段标记和清除来避免长时间的 Stop-The-World。它需要与一个“新生代收集器”配合使用。 在 CMS 时代,最常见的搭配是: 新生代用:ParNew(并行的新生代收集器),使用复制算法。 老年代用:CMS(并发标记清除收集器) 2)G1:垃圾回收器 回收过程(混合回收): 初始标记: 同CMS,标记GC Roots直接关联的对象,需要 STW。 优化:这个阶段会借一次 Young GC 的机会完成,所以成本极低。 并发标记: 同CMS,从GC Root开始进行可达性分析,找出存活对象,并发执行。 最终标记: 同CMS的“重新标记”,修正并发标记期间的变动,需要 STW。 优化:G1使用 SATB 算法,通常比CMS的增量更新更快。 筛选回收: 动作:G1的核心阶段。根据用户设定的期望停顿时间,计算出回收哪些Region(垃圾比例高的Region)效益最高。 过程:对这些选中的Region进行回收,采用复制算法,将存活对象复制到空的Region中,同时清空整个旧Region。 特点:需要 STW,但可以多线程并行执行,并且是多个Region一起回收。 算法层面,G1 是一种基于 分区 + 复制 + 标记整理 混合算法的回收器: 年轻代回收(Young GC):使用 复制算法,把存活对象从 Eden 复制到 Survivor 或老年代。 老年代或混合回收(Mixed GC):采用 标记-整理 思想,将存活对象复制到新的 Region 并清空旧的 Region。 双亲委派 双亲委派(Parent Delegation)是 Java 类加载器(ClassLoader)的一种工作模式,加载一个类的流程是: 一个类加载器收到类加载请求。 它不会自己先尝试加载,而是先把请求交给父类加载器。 父类加载器再交给它的父类,层层向上,直到BootstrapClassLoader。 如果父类加载器能成功加载,就直接返回。 如果父类都找不到,再由当前类加载器自己去加载。 常见类加载器层次: BootstrapClassLoader:加载 JDK 核心类(rt.jar) ExtClassLoader:加载 JDK 扩展库 AppClassLoader:加载应用 classpath 下的类 为什么? 1)安全性。避免用户自定义类“伪造”JDK 核心类。比如有人自己写了一个 java.lang.String,如果没有双亲委派,可能被应用加载,造成安全问题。 2)避免重复加载。如果每个 ClassLoader 都自己加载一遍 java.util.List,就会有多份不同的 Class 对象。 JVM的组成部分 1)类加载器子系统(ClassLoader) 负责把编译好的 .class 字节码文件加载到 JVM 内存中。 它遵循 双亲委派机制,优先交给父加载器加载,避免重复加载和核心类被篡改。 2)运行时数据区 方法区(Method Area):存放类的结构信息(类元数据、常量、静态变量、JIT 编译后的代码等)。 堆(Heap):存放对象实例,几乎所有对象都在堆中分配。 栈(Stack):每个线程都有一个独立的栈,存放方法调用的局部变量、操作数栈、方法出口信息。 程序计数器:记录当前线程执行的字节码指令地址。 本地方法栈:为本地代码(例如 C/C++ 函数)运行时提供栈空间。 3) 执行引擎 负责把字节码指令翻译成底层机器指令交给 CPU 执行。 包含 解释器(逐条解释执行)和 JIT 编译器(热点代码编译成本地机器码,提高性能)。 4)本地方法接口 提供调用非 Java 语言(如 C/C++)编写的本地方法的能力。 通过 JNI 连接到本地库(Native Libraries),比如操作系统底层函数等(创建线程、读写文件、网络 IO)。 5)本地库 实际的本地代码实现,JNI 会调用它们来完成底层操作。 怎么理解Java堆是线程共享的? 所有线程都可以访问堆中的对象(只要它们持有该对象的引用)。 注意:虽然堆是共享的,但每个线程的栈是私有的!!!! public class MethodLocalObjectExample { public static void main(String[] args) { // 方法内创建对象 Object obj = new Object(); // obj 是局部变量,但 new Object() 在堆上 System.out.println(obj); // 输出对象地址 } } new Object()是在堆上分配的,所有线程都能访问(如果有引用)。 但 obj是局部变量(栈私有),其他线程无法直接访问这个引用,因此这个对象默认不共享。除非这个引用传递给其他线程!!! JMM内存模型 JMM (Java Memory Model) 是 Java 语言规范里定义的一套内存可见性与有序性规则。 因为底层硬件(CPU、缓存、多核架构)和编译器优化会导致: 指令重排(out-of-order execution) 缓存不一致(每个线程可能有本地缓存) 编译器优化导致的“读旧值” JMM 主要解决 可见性 一个线程对共享变量的修改,能不能被其他线程及时看到? volatile / synchronized / Lock 都能保证可见性。JMM 会在读写时插入 内存屏障,强制刷新到主内存、强制从主内存读取,确保线程之间的修改可见。 当线程进入 synchronized 块时: JVM 会执行 加锁(monitorenter) 指令,**清空工作内存(私有缓冲区)**中该共享变量的值,从 主内存中重新读取最新的值; 当线程退出 synchronized 块时: JVM 会执行 释放锁(monitorexit) 指令,把该线程对共享变量的修改 刷新回主内存; 并且会插入 内存屏障,禁止指令重排。 有序性 编译器和 CPU 会对指令做重排序优化,JMM 提供了 happens-before 规则 来约束哪些操作必须有序。 happens-before 规则定义了哪些操作必须有序。 原子性 单次操作不可分割。 复合操作(如 i++)不是原子操作,需要用 锁(synchronized/Lock) 或 原子类(AtomicInteger 等,利用 CAS 实现) 来保证原子性。 happens-before 规则 如果操作 A happens-before 操作 B,那么: A 的结果对 B 可见; 并且 A 的执行顺序在 B 之前(逻辑顺序,而非物理执行顺序)。 常见的 happens-before 规则: 程序顺序规则:允许指令重排(物理顺序可以变),但重排不能改变程序在单线程中的逻辑结果。 int a = 1; int b = 2; int c = a + b; 编译器分析后发现 a 和 b 没依赖;它可能重排为: b = 2; a = 1; int c = a + b; 物理顺序变了,但逻辑结果不变 锁规则:解锁 happens-before 后续的加锁,即前一个线程在释放锁之前对共享变量的修改, 对随后获得同一锁的线程 可见。 volatile 规则:对 volatile 变量的写 happens-before 后续的读。 线程启动与终止规则:线程 start() happens-before 线程中所有操作;线程中所有操作 happens-before 另一个线程成功从 join() 返回。 即主线程对共享变量的修改,对新启动的线程 可见;子线程结束 → 主线程通过 join() 可见子线程的结果。 元空间 元空间(Metaspace)是 JDK8 之后用来存储类的元信息(class metadata)的内存区域(方法区),位于本地内存(Native Memory)中。在 JDK 8 之后,它取代了以前的 永久代(PermGen) 什么是类的元数据 元数据内容 详细说明 类名和修饰符 public final class User 父类信息 extends Object(显式或隐式) 实现的接口 implements Serializable, Cloneable 字段信息 名称、类型、偏移量(如 private String name) 方法信息 签名、字节码、异常表(如 public void setName(String)的字节码) 运行时常量池 符号引用(类/方法/字段)、字面量(如 final int MAX=100) 虚方法表(vtable) 支持多态的方法调用表(如 toString()的动态绑定) 注解信息 类/方法/字段上的注解(如 @Override) 用 元空间(Metaspace) 替代永久代 对比维度 永久代(PermGen) 元空间(Metaspace) 存储位置 JVM 堆内 本地内存(Native memory) 是否固定大小 是,需手动指定 否,默认按需增长 容易 OOM 吗? 是,类多时易崩 少见,但可用参数限制防爆 是否会被 GC 扫描 会 一般不会(但类卸载可手动触发) 从哪个版本开始移除 JDK8 JDK8 引入 Java 代码的编译过程 编写源代码(.java 文件) 编译阶段(javac 编译器) javac HelloWorld.java (1) 词法分析:将源代码分解为最小语法单元(tokens),例如关键字 public、标识符 main、分号等。 (2) 语法分析:根据 Java 语法规则生成抽象语法树(AST),判断语法是否正确(例如括号是否匹配、语句是否完整)。 (3) 语义分析:检查语义上的正确性,例如类型是否匹配、变量是否声明、继承是否合理。 (4) 字节码生成:编译器最终会生成 .class 文件 类加载 JVM启动后,会通过 类加载器 加载 .class 文件到内存。 字节码执行 加载完成后,JVM 会执行字节码: 解释执行:逐条解释执行字节码。 JIT 编译:热点代码(频繁执行的部分)会被即时编译为机器码,提高性能。 类加载过程 类加载过程分为 加载(Loading)→ 链接(Linking)→ 初始化(Initialization) 三个阶段。 **加载:**将 .class文件的二进制字节流加载到 JVM 内存,并生成一个 Class<?>对象。 链接: (1) 验证:检查字节码合法性,确保符合 JVM 规范,防止恶意代码(如篡改字节码)。 (2) 准备:为静态变量分配内存并赋默认值(非初始值!)基本类型:int→ 0,boolean→ false。 (3) 解析:将符号引用转为直接引用 符号引用:类/方法/字段的文本描述(如 com.example.User.getName)。 直接引用:指向方法区内存地址的指针或句柄。 **初始化:**静态代码块和静态变量赋值 类加载时机: new实例化对象。 访问类的静态字段或调用静态方法。 反射调用(如 Class.forName("com.example.User"))。 子类初始化时,父类需先初始化。 静态代理、动态代理 动态代理代理类(如 $Proxy0或 UserService$$EnhancerByCGLIB$$123456)在程序运行时动态生成。代理类的字节码在内存中生成,不会出现在你的源代码或编译后的 .class文件中。 静态代理代理类(如 UserServiceProxy)是你手动编写的,编译前就已经存在。 静态代理 静态代理 是一种在编译期( Java 源码编译成字节码(.class 文件)的阶段)就已经确定的代理模式,它通过手动编写一个代理类,在不修改原始类代码的情况下,增强或控制目标对象的行为。 示例: 假设我们有一个 UserService接口,它有一个方法 getUser(),我们想在调用这个方法前后 添加日志,但不修改 UserServiceImpl的代码。 1. 定义接口和实现类 // 接口 public interface UserService { String getUser(int id); } // 真实实现类 public class UserServiceImpl implements UserService { @Override public String getUser(int id) { return "User-" + id; } } 2. 编写静态代理类 // 代理类(手动编写) public class UserServiceProxy implements UserService { private UserService target; // 持有真实对象 public UserServiceProxy(UserService target) { this.target = target; } @Override public String getUser(int id) { System.out.println("【日志】开始查询用户,id=" + id); // 增强逻辑(日志) String result = target.getUser(id); // 调用真实对象的方法 System.out.println("【日志】查询结果:" + result); // 增强逻辑(日志) return result; } } 3. 使用代理类 public class Main { public static void main(String[] args) { // 真实对象 UserService realService = new UserServiceImpl(); // 代理对象(包装真实对象) UserService proxy = new UserServiceProxy(realService); // 调用代理对象的方法 String user = proxy.getUser(100); System.out.println("最终结果:" + user); } } 优点:不侵入目标类:无需修改 UserServiceImpl的代码。 缺点:灵活性差:代理关系在编译期固定,无法动态调整。如果要代理多个类,需要为每个类写一个代理类。 JDK Proxy动态代理 JDK 动态代理是 Java 原生提供的、基于接口的代理技术,通过反射动态生成代理类,在运行时拦截目标方法调用,实现增强逻辑(如日志、事务等)。 简单示例 (1) 定义接口和实现类 // 接口 public interface UserService { String getUser(int id); void deleteUser(int id); } // 真实实现类 public class UserServiceImpl implements UserService { @Override public String getUser(int id) { return "User-" + id; } @Override public void deleteUser(int id) { System.out.println("删除用户: " + id); } } (2) 实现 InvocationHandler import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; public class UserServiceInvocationHandler implements InvocationHandler { private final Object target; // 被代理的真实对象 public UserServiceInvocationHandler(Object target) { this.target = target; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 前置增强:日志 System.out.println("【日志】调用方法: " + method.getName()); // 调用真实对象的方法 Object result = method.invoke(target, args); // 后置增强:记录结果 System.out.println("【日志】方法结果: " + result); return result; } } 3.使用 Proxy.newProxyInstance生成代理对象 import java.lang.reflect.Proxy; public class Main { public static void main(String[] args) { // 1. 创建真实对象 UserService realService = new UserServiceImpl(); // 2. 创建 InvocationHandler,传入真实对象 InvocationHandler handler = new UserServiceInvocationHandler(realService); // 3. 动态生成代理对象 UserService proxy = (UserService) Proxy.newProxyInstance( realService.getClass().getClassLoader(), // 使用真实对象的类加载器 realService.getClass().getInterfaces(), // 代理的接口(UserService) handler // 方法调用处理器 ); // 4. 调用代理对象的方法 String user = proxy.getUser(100); // 会触发 InvocationHandler.invoke() proxy.deleteUser(200); } } 生成的代理类结构 // JDK 动态生成的代理类(简化版) public final class $Proxy0 extends Proxy implements UserService { private InvocationHandler handler; public $Proxy0(InvocationHandler h) { this.handler = h; } @Override public String getUser(int id) { return handler.invoke( this, UserService.class.getMethod("getUser", int.class), new Object[]{id} ); } @Override public void deleteUser(int id) { handler.invoke( this, UserService.class.getMethod("deleteUser", int.class), new Object[]{id} ); } } 局限性:如果类没有实现接口了,JDK Proxy 无法代理;接口中的 final 方法无法被代理。 应用: Spring AOP 如果目标类实现了接口,Spring 默认使用 JDK Proxy。 示例:@Transactional的事务管理就是通过动态代理实现的。 RPC 框架(如 Dubbo) 客户端通过 JDK Proxy 生成远程服务的本地代理,调用时触发网络请求。 CGLIB 动态代理 它通过 继承目标类 的方式在运行时动态生成代理类。与 JDK Proxy 不同,CGLIB 不需要目标类实现接口,可以直接代理普通类。 (1) 定义目标类(无需接口) // 目标类(没有实现任何接口) public class UserService { public String getUser(int id) { return "User-" + id; } public void deleteUser(int id) { System.out.println("删除用户: " + id); } } (2)实现 MethodInterceptor import net.sf.cglib.proxy.MethodInterceptor; import net.sf.cglib.proxy.MethodProxy; import java.lang.reflect.Method; public class UserServiceMethodInterceptor implements MethodInterceptor { @Override public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { // 前置增强:日志 System.out.println("【CGLIB日志】调用方法: " + method.getName()); // 调用父类(即真实对象)的方法 Object result = proxy.invokeSuper(obj, args); // 后置增强:记录结果 System.out.println("【CGLIB日志】方法结果: " + result); return result; } } (3) 使用 Enhancer生成代理对象 import net.sf.cglib.proxy.Enhancer; public class Main { public static void main(String[] args) { // 1. 创建 Enhancer(CGLIB 的核心类) Enhancer enhancer = new Enhancer(); // 2. 设置父类(即被代理的目标类) enhancer.setSuperclass(UserService.class); // 3. 设置回调(方法拦截器) enhancer.setCallback(new UserServiceMethodInterceptor()); // 4. 创建代理对象 UserService proxy = (UserService) enhancer.create(); // 5. 调用代理对象的方法 String user = proxy.getUser(100); // 会触发 MethodInterceptor.intercept() proxy.deleteUser(200); } } Enhancer是 CGLIB 的核心工具类,它会在运行时动态生成一个继承目标类(如 UserService)的子类,而这一切对开发者是透明的。 角色 作用 目标类(如 UserService) 被代理的原始类 MethodInterceptor 定义代理逻辑(如日志、事务) Enhancer CGLIB 的核心类,用于生成代理类 动态生成的代理类 继承目标类,覆盖其方法 UserService(目标类) ↑ 继承 UserService$$EnhancerByCGLIB$$123456(动态生成的代理类) 代理类 只在第一次调用 newProxyInstance()时生成,后续调用复用已生成的类。 Netty核心流程 数据处理流程 注册与监听: 首先,将所有的Channel注册到Selector上,并告诉Selector关心每个Channel的什么事件(比如“可读”事件)。 事件就绪: Selector作为调度员,在一个线程中循环检查。当某个客户端发送数据,对应的Channel连接上有数据可读时,Selector会检测到这个OP_READ事件就绪,并将其汇报出来。 注意:epoll是它的底层,epoll是事件驱动 + 就绪列表返回,不是轮询。 数据入站: 系统根据Selector的汇报,找到就绪的Channel,然后从该Channel中将数据读取到缓冲区(ByteBuf)中。至此,网络I/O操作完成。 流水线加工: 数据到达缓冲区后,就开始在ChannelPipeline这条流水线上流动。ChannelHandler链被依次触发: 首先,解码Handler(如ByteToMessageDecoder)将缓冲区里的原始字节解码成一个有意义的业务请求对象(比如一个HTTP请求对象)。 然后,这个业务请求对象被传递给业务逻辑Handler,在这里执行具体的业务计算(比如查询数据库)。 业务逻辑Handler处理完后,通常会生成一个响应结果。 数据出站(响应): 响应结果的发送是反向流程: 业务Handler将响应对象传递给Pipeline中的编码Handler(如MessageToByteEncoder)。 编码Handler将响应对象编码回字节,并写入缓冲区(ByteBuf)。 最后,这些在缓冲区中的字节数据再通过原来的Channel发送回客户端。在此过程中,Selector可能同时也在监听Channel是否“可写”,以高效地完成发送任务。 Channel = 水管(连接) ByteBuf = 水桶(存放数据) Pipeline = 加工流水线(加工数据) 零拷贝 传统 I/O 数据拷贝路径(有多次拷贝) byte[] buf = new byte[4096]; //申请一个缓冲区 int len = fileInputStream.read(buf); //从文件中读取数据到缓冲区 socketOutputStream.write(buf, 0, len); //把缓冲区的数据写到网络 socket 底层会发生 4 次数据拷贝 和多次上下文切换: 磁盘 → 内核缓冲区(DMA 拷贝) 内核缓冲区 → 用户态缓冲区(CPU 拷贝) 用户态缓冲区 → socket 内核缓冲区(CPU 拷贝) socket 内核缓冲区 → 网卡(DMA 拷贝) 问题: 读的时候从内核缓冲区拷贝到用户态 buf;写的时候又从用户态 buf 拷贝回 socket 内核缓冲区。有两次内核 ↔ 用户空间的数据搬运和两次系统调用(read + write) 零拷贝优化:减少或消除第 2、3 步的用户态拷贝,让数据在内核态直接完成“文件缓冲区 → socket 缓冲区”的传输。 场景题 设计一个会议室预约系统,多个会议室,每次最少定半小时,最多定两小时,一天一个人最多定两次,问题 1)存储结构怎么设计2)核心预定流程是什么3)抢会议室如何实现 1) ① 用户表(User) 字段 类型 说明 user_id INT 用户唯一标识 name VARCHAR 用户姓名 dept VARCHAR 部门等信息 ② 会议室表(Room) 字段 类型 说明 room_id INT 会议室唯一标识 name VARCHAR 名称 capacity INT 容量 location VARCHAR 位置描述 ③ 预定表(Booking) 字段 类型 说明 booking_id INT 预定唯一标识 room_id INT 外键,关联会议室 user_id INT 外键,关联用户 start_time DATETIME 会议开始时间 end_time DATETIME 会议结束时间 status ENUM 状态(已预定、取消、过期) created_at DATETIME 创建时间 2) 用户发起预定请求 输入:会议室ID、开始时间、结束时间。 系统校验: 会议时长是否在 0.5h~2h; 用户当天预定次数 ≤ 2; 时间段是否冲突(会议室是否已被占用)。 时间冲突判断 查询 Booking 表 : SELECT * FROM booking WHERE room_id = ? AND status = 'booked' AND (start_time < ? AND end_time > ?); 若有记录 → 冲突,拒绝预约。 写入预定记录 使用 事务 + 乐观锁 或 数据库唯一约束 保证并发安全; 成功后写入 Booking 表; 通知用户(可选:发邮件/推送)。 3)抢会议室的实现 当多个用户同时预定同一个会议室、同一时间段时,必须保证: 不能重复预定; 只有一个用户能成功。 数据库层防重 Redis 分布式锁 消息队列串行化请求(高并发优化) 高效判断若干个接口是否可用 有一批远程接口(比如几十个 API),需要检查它们是否可正常访问。 系统中已经有一个方法: boolean checkApi(String apiName) 该方法会调用远程接口,并返回: true:接口可用 false:接口不可用 请设计一段高效的代码,判断所有接口的可用性,并输出每个接口的检测结果。 思路: 1)不能串行检查,因为每次远程调用都要等待响应(可能几百毫秒甚至几秒),如果一个个调会非常慢。 所以要并发执行检查任务。 2)可以用 线程池(ThreadPoolExecutor) 管理线程,避免创建过多线程浪费资源。 3)每个接口检查都封装成一个任务(Callable),提交到线程池执行。 4)用 Future 或 CompletableFuture 收集每个任务的执行结果。 5)等所有任务完成后输出结果。 示例代码: import java.util.*; import java.util.concurrent.*; public class ApiCheckerSimple { public static void main(String[] args) throws Exception { // 模拟接口列表 List<String> apis = List.of("apiA", "apiB", "apiC", "apiD", "apiE"); // 1️⃣ 创建线程池 ExecutorService executor = new ThreadPoolExecutor( 2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(apis.size()) ); //分别是 核心线程数,最大线程数,空闲存活时间,单位(秒),workQueue(任务队列) // 2️⃣ 提交任务(每个接口一个检测任务) List<Future<Boolean>> futures = new ArrayList<>(); for (String api : apis) { futures.add(executor.submit(() -> checkApi(api))); } // 3️⃣ 收集结果(顺序与接口列表一致) for (int i = 0; i < apis.size(); i++) { Boolean ok = futures.get(i).get(); // 阻塞等待执行结果 System.out.println(apis.get(i) + " => " + (ok ? "可用" : "不可用")); } // 4️⃣ 关闭线程池 executor.shutdown(); } // 模拟接口检测 static boolean checkApi(String name) { //省略具体逻辑,概率返回true or false } } 接口变慢的排查思路 1)检查网络是否存在延迟或带宽瓶颈 常见于:带宽满、跨服务 / 跨区域 / 跨 VPC 调用 工具:ping、traceroute、netstat 2)查看接口日志 核心:是否一直慢,还是在某些时间段或特定请求下变慢? log.info("营销锁单开始执行:拼团交易锁单入参 userId={} req={}", userId, JSON.toJSONString(lockMarketPayOrderRequestDTO)); log.error("拼团交易锁单业务异常 userId={} req={}", ..., e); 接口开始/结束时间戳差值,看这次请求花了多久。 日志里是否有重试、异常堆栈、timeout、fallback、熔断等字眼? 3)观察数据库指标 是否存在慢查询、锁等待、连接池爆满等? 工具:数据库日志、EXPLAIN、慢 SQL 查询工具 -- 1. 开启慢查询日志功能 SET GLOBAL slow_query_log = 'ON'; -- 2. 设置慢查询阈值(单位:秒,默认 10 秒,建议设置为 1 秒或更小) SET GLOBAL long_query_time = 1; MySQL 会把 执行时间超过 1 秒的 SQL 语句 自动写入到 慢查询日志文件(slow query log) 中 内容形如: # Time: 2025-09-09T11:45:12.123456Z # User@Host: app_user[app_user] @ 192.168.1.10 # Thread_id: 12345 Schema: mydb QC_hit: No # Query_time: 3.214654 Lock_time: 0.000123 Rows_sent: 1 Rows_examined: 30542 SET timestamp=1694259912; SELECT * FROM trade_order WHERE status = 'PAID'; 开启慢日志找到耗时 SQL 后,我会用 EXPLAIN 看执行计划,重点关注是否走了全表扫描、索引有没有命中、扫描行数是否过多以及是否有临时表或排序;如果发现问题,就通过建合适的组合索引、做覆盖索引、或者重写 SQL(比如避免函数、只查必要字段、改用游标分页替代大 OFFSET)来优化。 4)查看代码 & 发布变更 是否新上线的代码引入了性能问题? 排查逻辑是否复杂、是否有死循环、递归、重复查询等问题? 5)查看服务监控 观察:系统资源是否有瓶颈?(CPU、内存、磁盘、网络 等) 如何排查 OOM 问题? 一、第一步:识别 OOM 类型 OOM 错误信息本身就提供了最重要的线索。常见的 OOM 类型及含义如下: OOM 类型 关联内存区域 常见原因 java.lang.OutOfMemoryError: Java heap space 堆内存 最常见。对象太多或太大,无法在堆中分配。 java.lang.OutOfMemoryError: Metaspace 元空间(方法区) 加载的类太多(如反射、动态代理、字节码增强框架)。 java.lang.OutOfMemoryError: Direct buffer memory 直接内存 NIO 的 DirectByteBuffer使用过多,未释放。 java.lang.OutOfMemoryError: Unable to create new native thread 系统内存 创建的线程数过多,超出系统或进程限制。 java.lang.OutOfMemoryError: GC overhead limit exceeded 堆内存 GC 花费了太多时间(如98%)却只回收了很少的内存(如2%),这是一种“几乎内存泄漏”的信号。 StackOverflowError 栈空间 递归、深层嵌套 行动: 首先查看错误日志,明确是哪种 OOM。 二、第二步:根据类型采取不同排查策略 场景 1:堆内存 OOM (Java heap space) 最常见 这是最复杂的场景,核心是分析堆转储文件(Heap Dump)。 1. 在启动时添加 JVM 参数,以便在发生 OOM 时自动生成堆转储文件(.hprof): -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/save/dump.hprof (如果未提前设置,在 OOM 发生后也可以用 jmap命令手动抓取,但可能已错过最佳现场) 2. 使用分析工具加载堆转储文件: Eclipse MAT (Memory Analyzer Tool):功能强大,首选。 3. 分析步骤(以 MAT 为例): 查看 Dominator Tree(支配树):列出占用内存最大的对象线程,快速找到“罪魁祸首”。 按对象实例(而不是类)占用的保留大小 (Retained Heap) 排序。保留大小是指这个对象本身加上它直接或间接引用的所有对象的总大小。 查看 Leak Suspects Report(泄漏嫌疑报告):MAT 会自动生成一个分析报告,直接给出可能发生内存泄漏的点,非常有用。 查看 Histogram(直方图):按类名统计实例数量和总大小,看看哪个类的对象异常得多。 分析引用链:对疑似泄漏的对象,查看其到 GC Roots 的引用链,重点排查为什么这些对象无法被垃圾回收。常见原因: 静态集合类(如 static Map)持有对象引用,忘记移除。 private static Map<Long, User> cache = new HashMap<>(); 所有存入的 User对象会永久存活,即使业务上已不再需要。 各种缓存(如本地缓存)没有淘汰策略或清理机制。 线程池中的线程局部变量(ThreadLocal)未清理。 (ThreadLocalMap 的 key 是弱引用指向 ThreadLocal 实例,而value是强引用) 数据库连接、网络连接、文件流等未显式关闭。 // 错误示例:文件流未关闭 public void readFile(String filePath) { FileInputStream fis = new FileInputStream(filePath); byte[] buffer = new byte[1024]; while (fis.read(buffer) != -1) { System.out.println(new String(buffer)); } // 忘记 fis.close()! } 排查 CPU 100% 的问题 第1步:找到罪魁祸首的 Java 进程 使用 top命令找到哪个 Java 进程最耗 CPU。 top 第2步:找到这个进程下的问题线程 看 %CPU 列,找到最耗 CPU 的线程,记下它的 TID(线程 ID)。 -H:显示线程模式 -p <PID>:只监控指定进程 top -Hp <PID> 第3步:将线程ID转换为16进制 printf "%x\n" <TID> 第4步:抓取整个进程的线程堆栈 jstack <PID> > jstack_dump.txt 第5步:定位问题线程 在生成的 jstack_dump.txt文件中搜索第3步得到的十六进制 nid。 grep -n <nid> jstack_dump.txt # 例如:grep -n 1a4e jstack_dump.txt 如何定位哪个容器里的Java 占用 CPU 高 1.docker status 效果类似 top,会显示每个容器的 CPU %、内存、网络、I/O,比如: CONTAINER ID NAME CPU % MEM USAGE / LIMIT ... 386e85737b31 smile-picture-backend 250.00% 517MiB / 2GiB be7f319061c9 gitea 1.20% 530MiB / 2GiB ... 2.docker top smile-picture-backend 会列出容器里的所有进程(宿主机 PID、用户、启动命令)。 3.后续同前面第二步开始!根据PID找线程,使用Top命令。 但是这里有个问题,容器是运行在隔离环境中的,jstack <PID> > jstack_dump.txt 貌似无法查看容器内进程的运行情况!!! 你会怎样设计一个RPC框架 1.动态代理 (Proxy Layer) - 对开发者透明 是什么:自动生成客户端代理类,伪装成本地接口。用户调用 userService.getUser(1),感觉像调用本地方法,但实际上是由代理类发起网络请求。 为什么:这是 RPC 的初心——隐藏远程调用的复杂性,让开发者专注于业务逻辑。这是框架易用性的最关键体现。 2. 序列化与反序列化 (Serialization/Deserialization) - 协议层核心 是什么:将 Java 对象转换成可在网络上传送的二进制字节流的过程叫序列化;反之叫反序列化。 为什么:网络只能传输二进制数据。这是通信的基石。 3. 网络传输 (Transport) - 通信基础 是什么:负责在客户端和服务端之间收发序列化后的二进制数据。 为什么:这是通信的物理基础。 考量点: 协议:基于 TCP 还是 HTTP?TCP 性能更优,HTTP 更通用、易调试。 IO 模型:主流选择是 NIO,能够用少量线程处理大量连接,性能极高(Netty 是事实标准)。 连接管理:使用长连接+连接池,避免频繁创建和销毁 TCP 连接的开销。 4. 服务发现与注册 (Service Discovery & Registry) - 治理基石 是什么: 服务注册:服务提供者启动时,将自己的地址(IP:Port)、服务名等信息上报到“注册中心”。 服务发现:消费者调用前,先连接到“注册中心”,根据服务名拉取所有可用提供者的地址列表。 为什么:在微服务动态环境中,服务的 IP 和端口是随时变化的(扩容、缩容、宕机)。不能将服务地址硬编码在配置文件中,需要一个中心化的目录服务来动态管理。 常见选型:ZooKeeper, Nacos 5. 负载均衡 (Load Balancing) - 公平调度 是什么:当从一个服务名下获取到多个提供者地址时,需要选择一个来发起调用。选择策略就是负载均衡。 为什么:将请求均匀分散到多个提供者实例上,避免单机过热,提高整体吞吐量和可用性。 常见策略:随机(Random)、轮询(RoundRobin)、加权(根据性能分配权重)、一致性哈希(同一用户请求总是落到同一台机器,适用于有状态或缓存场景)。 6. 容错机制 (Fault Tolerance) - 系统韧性 网络是不可靠的,服务可能会宕机。必须有完善的容错策略来保证系统的鲁棒性。 超时控制 (Timeout):防止调用者无限期等待,快速释放资源。 重试机制 (Retry):对超时或失败调用进行有限次数的重试(注意:对非幂等操作要谨慎)。 熔断器 (Circuit Breaker):类似电路保险丝。当失败率达到阈值,熔断器“跳闸”,后续请求直接失败,不再发起远程调用。给服务提供者恢复的时间。一段时间后进入“半开状态”尝试放行少量请求。 降级 (Fallback):调用失败后,提供一种备选方案,如返回默认值、缓存数据等,保证主流程可用。 如何优化? 1)序列化层优化,优化目标是:更小、更快。 2)网络传输层优化,使用长连接 (Keep-Alive) 和连接池:避免每次 RPC 调用都经历三次握手和四次挥手;采用高性能 NIO 框架:使用 Netty 作为网络通信框架。 Mysql如何设计索引 表t有查询: SELECT a FROM t WHERE b > 1 AND c <> 5 AND d = 10; # <> 等价于 '不等于' 在 MySQL(InnoDB) 中,应该如何设计索引?为什么?优化器会自动调整这些条件的顺序吗? 1.索引设计 建复合覆盖索引 INDEX(d, b, a) d=10 是等值 → 放首列,先把范围收窄。 b>1 是范围 → 放第二列,在 d=10 的段内做 range 扫描。 a 放末位做覆盖,减少回表。 c<>5 不等值对 B-Tree 不友好,通常由 ICP(索引条件下推)或残留过滤处理,不强求入键位。 索引字段选择: =、IN 能很好地用上索引 >、< 能部分利用索引(范围扫描) <>(不等于)会导致“两段范围”((-∞,5) 和 (5,+∞)),多数时候优化器宁愿直接全表扫或残留过滤。所以通常 不会专门为了 <> 建索引。 为什么把 a 放进索引 索引作用点主要是 WHERE 条件,帮你缩小扫描范围,但是查询里 SELECT 的列如果不在索引里,MySQL 要回到 聚簇索引(主键数据页)去拿数据,这叫“回表”。如果你在二级索引里同时包含了要查询的列,那结果就可以直接从索引里拿出来 → 减少回表 I/O,速度会快很多。 2.优化器“会不会自动调整顺序 谓词求值顺序:优化器会重排,选择性强的会先评估。 索引列顺序:不会自动调换;B-Tree 的物理顺序由你建索引时决定,所以仍需遵循“等值在前、范围其后”的建模原则。 如何避免分布式系统出现故障 1)多实例部署 数据库:主从复制;自动故障切换;分片/分库分表,避免单机压力过大 缓存:哨兵模式,本地缓存 + 远程缓存双层兜底 服务实例:多实例部署,负载均衡,Nacos监控 2)降级、熔断和限流 服务降级:非核心功能先停掉,保证主流程可用。 熔断机制:当依赖系统不可用时,快速失败,避免请求堆积拖垮自己。 限流保护:用漏桶/令牌桶保护后端,防止雪崩。 3)监控、告警、自动恢复 实时监控、告警,结合容器编排。 4)数据保障:日志、备份、幂等设计,确保出故障后能快速恢复。 Mysql统计字段中xx出现的次数 在 SQL 里,没有直接的“数某个字符出现次数”的函数。 但我们可以用 字符串长度差 来实现: LENGTH(content):原始字符串长度。 LENGTH(REPLACE(content, ',', '')):把逗号都去掉之后的长度。 两者之差,就是逗号的个数。 SELECT id, content, LENGTH(content) - LENGTH(REPLACE(content, ',', '')) AS num FROM information; Mysql查询语句性能分析 ① SELECT * FROM ClassA WHERE id IN (SELECT id FROM ClassB); ② SELECT * FROM ClassA A WHERE EXISTS (SELECT * FROM ClassB B WHERE A.id = B.id); 假设: ClassB 表数据量非常大; ClassB.id 上有 索引。 问:哪一段执行效率更高? 答: ① IN 子查询 IN 会先执行子查询: SELECT id FROM ClassB 得到一个结果集,然后外层再判断: A.id IN (结果集) 如果 ClassB 很大,结果集会非常大; 系统可能会将整个结果集加载到内存中再比较; 即使有索引,仍可能导致性能下降,因为 IN 需要逐个匹配。 ② EXISTS 子查询 EXISTS 的逻辑是: 对 ClassA 的每一行,去 ClassB 里查是否存在匹配; 一旦找到匹配(即 A.id = B.id),就立即返回 TRUE; 不再继续扫描 ClassB。 是以数据量比较少的A来驱动的!!! 谈谈你对分布式系统的理解 优点: 1)可扩展性,水平扩展,突破单机 CPU/内存/IO 的限制 2)高可用,多副本冗余,节点挂了还能切换 3)高性能,负载均衡,请求分散到多节点并行处理 4)灵活性 & 弹性,弹性扩缩容,按需节省成本 缺点: 1)复杂性增加,部署、运维、监控、排查问题都更难 2)网络不可靠带来的问题,延迟、丢包、脑裂、超时重试 3)一致性问题,多副本更新要考虑一致性 4)成本更高 CAP理论 在一个分布式系统里,最多只能同时满足以下三项中的两项: C(Consistency,一致性) 所有节点对外看到的数据是强一致的,像访问单机一样,读到的一定是最新值。 A(Availability,可用性) 每个请求都能在有限时间内返回(不一定是最新数据,但不能一直挂起)。 P(Partition tolerance,分区容错性) 即使网络出现分区(节点之间通信失败、丢包、延迟),系统也能继续对外提供服务。 雪花算法底层实现 0 | 41位时间戳 | 10位机器ID | 12位序列号 0:符号位,固定为 0。 时间戳 (41 bits):相对时间戳,能用约 69 年。 机器 ID (10 bits):最多支持 1024 个节点。 序列号 (12 bits):每毫秒最多 4096 个 ID。 生成流程: 1)获取当前毫秒时间戳。 2)如果时间戳和上次相同 → 序列号 +1;超过 4095 → 等下一毫秒。 3)如果时间戳比上次大 → 序列号重置为 0。 4)拼接得到唯一 ID。 所以 在同一毫秒、同一机器上,最多可以生成 4096 个不同 ID。 大数据分布式计算 + TopK 问题 问题抽象 数据规模:100 亿个数。 环境:5 台机器,每台 1 CPU,512 MB 内存,1 TB 硬盘,1 G 网卡。 目标:选出最大的 1000 个数。 特点: 数据量极大(10¹⁰),远远超过单机内存。 硬盘和网络资源有限,必须流式处理、分布式处理。 TopK(K=1000)相对很小。 算法层面:TopK 的经典方法 单机思路 使用 小根堆(min-heap): 维护一个大小为 1000 的小根堆。 遍历所有数据,每来一个数: 如果比堆顶大 → 替换堆顶并调整堆。 否则丢弃。 最终堆里就是最大的 1000 个数。 复杂度: 时间:O(N log K) ≈ 10¹⁰ * log 1000。 空间:O(K),只需存 1000 个数(几 KB)。 问题:单机 CPU / IO 扛不住 100 亿规模,需要分布式。 分布式系统设计 我们有 5 台机器 → 可以用 分布式 TopK 聚合: Step 1:数据分片 假设数据分布在 5 台机器上(或通过切分 / 分布式存储)。 每台机器 只处理自己那部分数据。 Step 2:局部 TopK 每台机器用小根堆求 本地前 1000 个数。 这样 100 亿数据在每台机器先被压缩成 1000 个候选。 本地计算代价:O((N/5) log K),只需几百 MB 内存,很轻量。 Step 3:全局归并 将 5 * 1000 = 5000 个候选数汇总到一台机器。 在这 5000 个数里再用小根堆求前 1000。 这一步开销很小,5000 个数据完全可以在内存里做。 追问:算法层面可以采用负载均衡、数据分块并结合堆来实现,那么如何从工程的角度来保证这个系统的稳定性? 1)流式处理: 避免一次性加载数据,采用顺序读写硬盘(避免随机 IO), 流式扫描(边读边处理)。这样即使单机内存有限(512 MB),也能稳定运行,不会 OOM。 2)负载均衡 使用 统一调度器(可以是 Nginx、任务队列、或 K8s 调度器),合理分配任务,防止某台机器过载。 3)容错机制 如果某台机器宕机或任务失败,调度器能 重试任务 或 转移任务到其他机器。 4)扩展性 系统应该支持 水平扩展:增加机器数量 → 按数据分块比例缩小每台的工作量。 5)资源隔离、系统监控、报警、记录日志。 追问:一个机器处理某个数据块时宕机了,如何不让其从头开始处理数据,而是找到上一次处理数据的位置继续处理?怎么做持久化?怎么做数据恢复?怎么实现数据处理进度的标记? 问题分析:如果没有机制,只能 从头重新处理整个数据块 → 浪费大量资源。 核心思路: 1)持久化中间状态 定期把处理进度和关键数据写到可靠存储(如磁盘/分布式存储)。 1)假设数据块存在文件里,可以用「字节偏移量」或「行号」来记录当前处理到哪。offset=123456789,表示已经处理到文件的第 1.23 GB。 2)每处理一批数据(比如 1 万条),写一次进度到磁盘/数据库。写入内容包括:任务ID、数据块ID、偏移量、已处理的TopK候选堆内容。 2)数据恢复机制 任务失败后重新启动时,能读到之前的持久化状态(偏移量 + 堆内容),从断点继续。 断点续传如何实现? 核心目标是:文件传输中断后,不用从头重新传,只需从上次中断的位置继续。 本质:把大文件分成多个小块传输,并记录哪些块已经成功。 前端: 1)文件分块,把大文件分成多个小块(chunk),每块单独上传。 2)给文件(原始大文件或切片)算一个唯一的 ID(比如 MD5),用来让后端识别这是同一个文件。 3)记录哪些块已经上传成功,能知道上次传到哪一块。 4)续传控制,重新连接后,先询问后端“哪些块已经传完”;然后只上传剩余的块。 后端: 1)接收分块,要区分属于哪个文件、是第几块。 2)记录状态,每个文件有哪些块已上传。 常用数据库或 Redis 存储上传进度。 3)当所有分块上传完后,后端进行完整性校验+按顺序合并 4)提供一个接口让前端询问“我这个文件哪些块已经传过了?” 查找第K大元素 OR 查找某个数 如果查找无序数组第K大元素? 选择一个枢轴(pivot),通常取区间的第一个元素。执行 partition 操作:把小于 pivot 的元素放左边,大于 pivot 的放右边;返回 pivot 的最终位置 pos。如果我们不需要整个数组排序,只需要第 k 大的元素, 就没必要递归左右两边 —— 只递归包含第 k 大的那一边即可。这样每次都能排除掉一半数据,平均时间复杂度是 O(n)。 给你一个 有序数组,请找到目标值的下标。 二分查找的思想是利用有序性, 每次把搜索区间折半,逐步缩小范围,直到找到目标或确定不存在。 具体做法: 设两个指针 left 和 right 分别指向数组两端; 每次取中点 mid = (left + right) / 2; 比较 nums[mid] 和目标值: 若相等 → 返回 mid; 若 nums[mid] < target → 说明目标在右边,left = mid + 1; 若 nums[mid] > target → 说明目标在左边,right = mid - 1; 循环直到 left > right,表示没找到。 Spring 谈谈String的核心特性 Spring 的核心特性可以概括为以下几点,其中 IoC 和 AOP 是基石中的基石: 控制反转与依赖注入 面向切面编程 Spring 声明式事务管理 数据访问与集成 提供了统一的数据访问抽象,比如 JdbcTemplate、HibernateTemplate,简化了 JDBC 和 ORM 框架的使用。 Web MVC 框架 支持 REST 风格接口,配合注解(@Controller, @RequestMapping 等)开发高效 强大的测试支持 JUnit5,@SpringBootTest,Spring 会启动容器,把真实 Bean 注入进来,测试组件之间的协作。 Spring Boot 的“约定大于配置” 基于 Spring 的一站式框架,强调快速开发与自动化配置;通过 Starter 依赖、自动配置机制减少样板代码和繁琐的 XML 配置;内置 Tomcat,开箱即用。 SpringBoot的原理 如果我们直接基于Spring框架进行项目的开发,会比较繁琐。SpringBoot框架之所以使用起来更简单更快捷,是因为SpringBoot框架底层提供了两个非常重要的功能:一个是起步依赖,一个是自动配置。 起步依赖 Spring Boot 只需要引入一个起步依赖(例如 springboot-starter-web)就能满足项目开发需求。这是因为: Maven 依赖传递: 起步依赖内部已经包含了开发所需的常见依赖(如 JSON 解析、Web、WebMVC、Tomcat 等),无需开发者手动引入其它依赖。 结论: 起步依赖的核心原理就是 Maven 的依赖传递机制。 自动装配 在传统 Spring 开发中,需要在 applicationContext.xml 或 @Configuration 类里手工声明大量 Bean。Spring Boot 为了简化配置,引入了 自动装配(Auto Configuration),让我们只需少量注解就能“开箱即用”。 自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是: @SpringBootConfiguration 声明当前类是一个配置类,作用类似 @Configuration,但作为 Spring Boot 的专用配置入口标识。 @ComponentScan 用于 扫描项目自定义的 Bean,比如 @Component、@Service、@Repository、@Controller 等。 默认扫描 启动类所在包及其子包。 如果项目分为 server、common 等模块,可以通过: @ComponentScan({"com.your.package.server", "com.your.package.common"}) 来显式指定需要扫描的包路径。 @EnableAutoConfiguration(自动配置核心注解) 导入自动配置类 通过元注解 @Import(AutoConfigurationImportSelector.class),在启动时读取所有 JAR 包中 META‑INF/spring.factories 中声明的自动配置类,并注册到容器。 按条件注册 Bean 配置类内部使用条件注解(@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty 等)。 仅在 类路径、配置属性、已有 Bean 满足条件时,才创建对应 Bean。 典型示例 DataSourceAutoConfiguration:检测到 JDBC 驱动和 spring.datasource. 配置时自动创建数据源。 WebMvcAutoConfiguration:配置 Spring MVC 默认组件;若用户提供了自定义 MVC 配置,则自动“退让”(Back Off)。 自动配置的效果: Spring Bean 生命周期与 AOP 代理生成流程 Bean 从类加载到定义注册 本笔记以 UserService为例,详细说明一个 Bean 从.class文件到成为代理对象的完整过程。 一、类加载(JVM 层面):负责把 .class 文件加载进内存,生成 Class 对象。Spring 要使用某个类(比如反射扫描注解)时,前提是这个类已经被 JVM 加载过了。 触发时机: 组件扫描时(@Component、@Service、@Controller 等); 配置类解析时(@Configuration、@Bean 方法、自动配置类); 反射访问或依赖注入时(如第一次 getBean() 调用懒加载 Bean)。 二、Bean 定义加载(Spring 层面) 旨在收集所有 Bean 的元数据(BeanDefinition)。 【配置解析】:Java 配置类:通过 @Configuration + @Bean 方法; 【组件扫描】:@Component、@Service、@Repository、@Controller 等; 【注册定义】:将为每个 Bean 解析出的元信息(如类名、作用域、是否懒加载等)封装为一个 BeanDefinition对象,并注册到 BeanFactory的 beanDefinitionMap中。 - class = UserService.class - scope = singleton - lazy = false 此时的状态:UserService类已经被类加载器加载,JVM中有它的 Class对象,Spring容器中有它的 BeanDefinition,但尚未创建任何实例,也未生成任何代理。 Spring Bean 生命周期 容器启动时(中后期),容器创建 Bean 实例,AOP 代理对象即在此过程中生成。 以下Bean例外: 1.被标记为 @Lazy 的 Bean,只有第一次被依赖或调用时才实例化 2.条件化注入(@Conditional),若配置项不满足,则这个 BeanDefinition 根本不会注册进容器 3.作用域为 prototype,每次 getBean() 才会创建一个新实例。 序号 阶段 说明 关键点 1 **实例化 ** Spring 容器根据配置(如 @Component、@Bean、XML)创建 Bean 的实例。通常通过 反射 调用无参构造方法创建对象。 此时是原始对象,非代理。 2 属性填充、**依赖注入 ** 按照注解(如 @Autowired)或配置,为原始对象注入其所需的依赖。 3 BeanPostProcessor 前置处理 执行所有 BeanPostProcessor的 postProcessBeforeInitialization 方法。 可用于修改 Bean 实例,此时仍是原始对象。 4 **初始化 ** 1. 执行 @PostConstruct注解的方法。 2. 执行 InitializingBean.afterPropertiesSet()方法。 3. 执行自定义的 init-method。 Bean 自身定义的初始化逻辑。 5 BeanPostProcessor 后置处理 (AOP 切入点!) 执行所有 BeanPostProcessor的 postProcessAfterInitialization 方法。这是 AOP 代理生成的核心时机! - AnnotationAwareAspectJAutoProxyCreator 会检查当前 Bean 是否需要被代理(如是否被 @Transactional、AOP 切面匹配)。 - 如果需要:则调用 JDK Proxy 或 CGLIB 动态生成代理对象,并返回此代理对象。 - 如果不需要:则直接返回原始对象。 代理对象在此刻诞生,并替换了原始对象。 6 Bean 就绪 经过上述步骤的最终对象(可能是代理对象,也可能是原始对象)被放入单例池(singletonObjects),标志着 Bean 完全就绪,可供容器和其他 Bean 使用。 使用代理 Bean 当其他组件(如 UserController)通过 @Autowired注入 UserService时,它们拿到的是第二步第5步中返回的代理对象,而非最初的原始对象。 当调用 userService.someMethod()时,调用的是代理对象的方法。 代理对象会先执行增强逻辑(如事务管理、日志记录),然后通过反射调用原始对象(rawInstance)的相应方法。 SpringBoot启动流程 Spring Boot 启动顺序就是: JVM 类加载 → 创建 SpringApplication → 加载配置 → 扫描并注册 BeanDefinition → 实例化 & 注入 & 初始化 → AOP 代理 → 启动 Web 容器 → 发布启动完成事件。 入口:main 方法 做什么:所有 Spring Boot 应用从带有 @SpringBootApplication 注解的类的 main 方法启动。 关键代码 public static void main(String[] args) { SpringApplication.run(MyApplication.class, args); } 作用:调用 SpringApplication.run() 启动整个流程。 前提:启动类本身(MyApplication.class)已经被 JVM 类加载器加载到内存。 初始化 SpringApplication 做什么 创建 SpringApplication 实例,负责管理整个启动流程。 准备一系列监听器(Listeners)、初始化器(Initializers)。 加载扩展组件:从 META-INF/spring.factories 读取自动配置、监听器等第三方扩展点。 事件机制:发布 ApplicationStartingEvent 等事件,允许开发者在早期介入。 读取配置文件 做什么 加载配置:读取 application.properties 或 application.yml。 设置环境变量:构建 ConfigurableEnvironment,整合系统属性、JVM 参数、配置文件参数。 刷新应用上下文(核心步骤) 调用 context.refresh() → Spring Boot 启动的心脏。 关键子流程: 加载 Bean 定义 组件扫描:解析 @Component、@Service、@Controller 等注解类。 配置类解析:读取 @Configuration 类中的 @Bean 方法。 注册成 BeanDefinition,存放在 beanDefinitionMap 中。 注意:此时只是“配方”,尚未 new 出对象。 自动配置 触发 @EnableAutoConfiguration。 加载 META-INF/spring.factories 中的自动配置类。 条件化配置 在加载自动配置类时,@ConditionalOnXxx 会通过 ConditionEvaluator 判断是否满足条件,决定 BeanDefinition 是否注册。 实例化与依赖注入 所有非懒加载的单例 Bean 被实例化 执行依赖注入(@Autowired、@Resource 等)。 Bean 初始化 调用 @PostConstruct、InitializingBean.afterPropertiesSet()、init-method 等初始化方法。 后置处理器(AOP 切入点) BeanPostProcessor.postProcessAfterInitialization() 阶段,如果匹配到切面(如事务、日志),生成 代理对象,替换原始 Bean。 启动内嵌 Web 服务器(Web 场景) 做什么:如果是 Web 应用,会自动启动内嵌的 Tomcat/Jetty/Undertow。 关键点:端口监听完成后,Spring Boot 应用对外提供服务。 完成启动 做什么:容器进入就绪状态。 回调执行:执行 ApplicationRunner、CommandLineRunner 中的逻辑。 事件发布:发布 ApplicationReadyEvent,通知应用完全启动成功。 Spring循环依赖为什么需要三级缓存 在Spring的默认单例Bean创建过程中,三级缓存指的是三个Map: 一级缓存 :存放完全初始化好的、成熟的Bean。这是我们实际用到Bean的地方。 二级缓存 :存放早期的Bean引用(已实例化但未完成属性填充和初始化)。 三级缓存 :存放Bean的工厂对象(ObjectFactory)。这个工厂能根据条件(如是否需要AOP)返回一个早期的Bean引用。 如果只有二级缓存(早期暴露) 开始创建 A 实例化 A(调用构造函数,得到一个原始对象 A@123) 将原始对象 A@123放入二级缓存(earlySingletonObjects) 为 A 填充属性时发现需要注入 B → 触发 getBean("B") 开始创建 B 实例化 B(得到原始对象 B@456) 将 B@456放入二级缓存 为 B 填充属性时发现需要注入 A → 从二级缓存拿到 A@123(原始对象) B 完成属性注入(此时 B 中持有的是 A@123) B 完成初始化,放入一级缓存(singletonObjects) 回到 A 的创建 从一级缓存拿到 B@456,注入到 A 中 问题来了:如果 A 需要被 AOP 代理(比如有 @Transactional注解),Spring 会生成代理对象 A$Proxy@789,并放入一级缓存 最终结果: 一级缓存中是 A$Proxy@789(代理对象) 但 B 中已经注入了 A@123(原始对象),导致 B 依赖的 A 和最终暴露的 A 不是同一个对象! (AOP 失效,事务等增强不生效) 引入三级缓存 开始创建 A 实例化 A(得到原始对象 A@123) 向三级缓存暴露一个工厂(ObjectFactory),而非直接放入二级缓存 (工厂的作用:在需要时能返回原始对象或代理对象) 为 A 填充属性时发现需要注入 B → 触发 getBean("B") 开始创建 B 实例化 B(得到 B@456) 向三级缓存暴露 B 的工厂 为 B 填充属性时发现需要注入 A → 从三级缓存拿到 A 的工厂 工厂执行 getObject(),此时发现 A 需要 AOP 代理 → 生成代理对象 A$Proxy@789 (代理逻辑会根据 A 的最终状态生成,但此时仅提前生成引用) 将 A$Proxy@789放入二级缓存(标记为“早期引用”) B 完成属性注入(此时 B 中持有的是 A$Proxy@789) B 完成初始化,放入一级缓存 回到 A 的创建 从一级缓存拿到 B@456,注入到 A 中 A 完成初始化,检查二级缓存: 如果存在(说明有工厂提前生成过代理),则确保最终暴露的对象与早期引用的代理一致 (这里直接返回二级缓存的 A$Proxy@789,避免重复生成代理) 将 A$Proxy@789放入一级缓存 Spring事务失效的情况 一、自调用 同一个类中,一个方法调用另一个标注了 @Transactional 的方法时,事务不会生效。 原因:Spring AOP 是基于代理的,调用必须通过 Spring 生成的代理对象进行。如果是类内部调用,相当于 this.method(),绕过了代理。 @Service public class UserService { @Transactional public void methodA() { methodB(); // 自调用,事务失效 } @Transactional public void methodB() { // 不会开启事务 } } 正确调用方式: 将 methodB() 提取到另一个类中 @Service public class MethodBService { @Transactional public void methodB() { // 事务生效 } } @Service public class UserService { @Autowired private MethodBService methodBService; public void methodA() { methodBService.methodB(); // ✅ 通过 Spring 管理的代理对象调用,事务生效 } } 进阶:通过代理调用自身方法(推荐) 你可以从 Spring 容器中获取当前 Bean 的代理对象,然后用代理对象调用 methodB(): @Service public class UserService { @Autowired private ApplicationContext context; @Transactional public void methodA() { // 从容器中获取代理对象 UserService proxy = context.getBean(UserService.class); proxy.methodB(); // 经过代理调用 } @Transactional public void methodB() { // 这里的事务才会生效 } } 二、方法不是 public 导致事务失效 被 @Transactional 注解的方法如果不是 public 的,事务不会生效。 原因:Spring 默认使用 JDK 或 CGLIB 代理,而代理只对 public 方法进行增强。 三、异常未被正确抛出 如果抛出的异常是 checked exception 或者被 catch 捕获而没有重新抛出,事务不会回滚。 默认情况下,只有 RuntimeException 和 Error 会触发回滚,可以通过设置 rollbackFor 参数来指定其他异常: @Transactional(rollbackFor = Exception.class) 被 catch 捕获而没有重新抛出,正确做法:捕获后继续抛出 @Transactional public void saveUser() { try { userRepository.save(null); } catch (Exception e) { throw new RuntimeException("数据库保存失败", e); // 重新抛出,触发回滚 } } 四、数据库引擎不支持事务 使用的数据库或数据库表不支持事务(如 MySQL 的 MyISAM 引擎),即使开启事务也不会生效。 分布式事务 好的,我来分别简洁说明 2PC、3PC、TCC 三种分布式事务控制方式: 1. 2PC(两阶段提交) 阶段一:准备(Prepare) 协调者向所有参与者发送“准备提交”请求,参与者执行事务但不提交,只写入日志并锁定资源,返回“可以提交/回滚”。 阶段二:提交(Commit) 如果所有参与者都同意,协调者下发“提交”;若有一个失败,则下发“回滚”。 优点:实现简单,强一致性。 缺点:同步阻塞、单点故障风险大、可能导致资源长时间锁定。 同步阻塞:在事务提交前,参与者资源会被锁定,导致其它请求被阻塞,效率较低。 单点故障:协调者是单点,一旦出问题,整个事务无法推进,严重依赖其可用性。 数据不一致:由于网络异常或消息丢失,可能导致部分参与者提交,部分未提交,从而产生数据不一致。 2. 3PC(三阶段提交) 在 2PC 基础上增加 “预提交”阶段,拆成三步: CanCommit:协调者询问是否可提交。 PreCommit:若所有参与者都回复可行,协调者发送“预提交”,参与者执行事务并进入“可提交”状态。 DoCommit:协调者最终发出提交命令,参与者完成提交。 优点:减少单点故障导致的阻塞,超时可自动决策。 缺点:实现复杂,依然可能出现数据不一致。 在 3PC 中,参与者在 PreCommit 阶段已经进入“可以提交”的状态,如果后续协调者消息丢失,参与者还能根据超时策略自主提交或回滚。 3. TCC(Try-Confirm-Cancel) 应用层实现的补偿事务模型: Try:尝试阶段,预留资源(如冻结资金)。 Confirm:确认阶段,正式执行业务操作。 Cancel:取消阶段,释放预留资源,回滚业务。 要求: 三套接口:开发者需要在业务代码里写冻结、确认、释放三套接口 幂等性:Cancel 接口必须设计成可安全多次调用。 如果没有冻结,就什么都不做,返回成功; 如果已经冻结,就解冻并返回成功。 空补偿(Null Compensation):允许 Cancel 在没有 Try 的情况下被调用,业务逻辑要能识别并正确处理。 计算机网络 三次握手 三次握手过程 TCP三次握手的目标是双方 同步序列号 和 确认序列号,并建立一条可靠的连接。 假设客户端(Client)想要与服务器(Server)建立连接。 第一次握手(SYN) 客户端向服务器发送一个请求连接的报文,标志位 SYN=1,并携带一个随机的初始序列号 seq=x, 表示希望建立连接。 发送完后,客户端进入 SYN-SENT 状态。 第二次握手(SYN-ACK) 服务器收到客户端的 SYN 报文后,如果同意建立连接,会回复一个标志位为 SYN=1、ACK=1 的报文, 此时服务器自己也生成一个初始序列号 seq=y,并将 ack=x+1 作为确认号, 表示已收到客户端的请求。 服务器进入 SYN-RCVD 状态。 第三次握手(ACK) 客户端收到服务器的 SYN-ACK 后,再回复一个 ACK=1 的确认报文, 其中 seq=x+1、ack=y+1,表示双方的握手确认成功。 此时客户端进入 ESTABLISHED 状态;服务器收到该报文后,也进入 ESTABLISHED 状态。 为什么两次握手不行 防止已失效的连接请求报文突然传到,导致错误(核心原因) 场景:假设客户端发送了一个SYN请求(第一次握手),但这个报文在网络中滞留了,迟迟没有到达服务器。客户端超时后未收到回复,于是重发了一个新的SYN请求,这次成功建立连接,数据传输完毕后关闭了连接。 问题:此时,那个滞留的SYN报文终于到达了服务器。服务器误以为这是客户端发起的一个新连接请求,于是回复SYN-ACK(第二次握手)并提前分配了资源(如缓冲区、连接变量)。如果只有两次握手,服务器发出SYN-ACK后就会认为连接已经建立,并一直等待客户端发送数据。 结果:但客户端根本没有想要建立这个新连接!客户端不会发送任何数据。这将导致服务器的资源被白白浪费,等待一个永远不会到来的数据请求,造成资源耗尽和服务不可用的风险。 三次握手如何解决? 在三次握手的机制下,服务器收到滞留的SYN报文后,会回复SYN-ACK。但客户端不会回复第三个ACK(因为它没有请求这个新连接)。服务器在长时间收不到ACK后,会超时重传SYN-ACK,最终失败并释放资源,从而避免了错误。 四次挥手 四次挥手过程 TCP是全双工通信,这意味着数据在两个方向上可以独立传输。因此,关闭连接需要每个方向都单独被关闭。 假设客户端(Client)主动发起关闭连接。 第一步:FIN (Finish) 动作:客户端希望关闭连接,于是发送一个TCP报文段。 标志位:设置 FIN = 1(表示它没有更多数据要发送了)。 序列号:seq = u(u等于客户端之前已传送数据的最后一个字节的序列号加1)。 状态变化:客户端进入 FIN-WAIT-1状态。这意味着客户端已经没有数据要发送了,但如果服务器还有数据要发送,客户端仍然需要接收。 第二步:ACK (Acknowledge) 动作:服务器收到客户端的FIN报文后,对其进行确认。 标志位:设置 ACK = 1。 确认号:ack = u + 1(确认收到了客户端的关闭请求)。 状态变化:服务器进入 CLOSE-WAIT状态。 此时状态:从客户端到服务器的这个方向的连接已经关闭。客户端收到这个ACK后,进入 FIN-WAIT-2状态。但服务器到客户端的连接仍然打开,服务器可能还有未发送完的数据需要继续发送。 第三步:FIN (Finish) 动作:当服务器也完成了所有数据的发送后,它也会发送一个FIN报文。 标志位:设置 FIN = 1(有时这个报文会和第二步的ACK合并,此时标志位为 FIN = 1, ACK = 1)。 序列号:seq = w(w等于服务器之前已传送数据的最后一个字节的序列号加1)。 确认号:ack = u + 1(通常还会再次确认客户端的FIN)。 状态变化:服务器进入 LAST-ACK状态。 第四步:ACK (Acknowledge) 动作:客户端收到服务器的FIN报文后,必须发送一个确认报文。 标志位:设置 ACK = 1。 确认号:ack = w + 1。 状态变化:客户端进入 TIME-WAIT状态。等待一段时间(2MSL,Maximum Segment Lifetime)后,客户端才进入 CLOSED状态,彻底释放资源。服务器在收到这个最终的ACK后,立即进入 CLOSED状态,释放资源。 为什么客户端需要 TIME-WAIT 状态? 客户端发送完最后一个ACK后,必须等待 2MSL 的时间长度。 主要原因有两个: 可靠地终止连接:确保最后一个ACK能被服务器收到。如果这个ACK报文丢失,服务器会在超时后重传它的FIN报文(第三次挥手)。客户端在TIME-WAIT状态下可以收到这个重传的FIN,并重新发送ACK,从而保证双方都能正常关闭。如果没有这个等待,客户端直接关闭,服务器将永远收不到ACK,会一直处于LAST-ACK状态,无法正常关闭。 让旧连接的报文在网络中消散:等待2MSL时间,可以确保本次连接所产生的所有报文都从网络中消失,这样就不会影响到未来可能建立的、具有相同四元组(源IP、源端口、目的IP、目的端口)的新连接。 TCP和UDP 特性 TCP UDP 连接 面向连接 (需三次握手) 无连接 可靠性 高可靠,不丢包、不乱序 不可靠,可能丢包、乱序 速度/延迟 慢,开销大 快,延迟低 控制机制 有流量控制、拥塞控制 无控制,直接发送 数据形式 字节流 (无边界) 数据报文 (有边界) 特性 流量控制 (Flow Control) 拥塞控制 (Congestion Control) 控制对象 发送方 vs 接收方 (一对一) 发送方 vs 网络 (一对多) 解决什么问题 发送太快,接收方处理不过来(缓冲区溢出) 发送太快,网络处理不过来(路由器丢包) 根本原因 接收方处理能力、缓冲区大小有限 网络带宽、路由器缓存等公共资源有限 谁在控制 接收方主导(通过通知发送方自己的窗口大小) 发送方主动探测和调整(根据网络反馈) 实现机制 滑动窗口协议 (TCP头部中的窗口大小字段) 多种算法 (慢启动、拥塞避免、快重传、快恢复) 目标 防止接收方被淹没 防止网络被塞满瘫痪 使用场景: TCP:用于需要“万无一失”的场景 Web浏览 (HTTP/HTTPS) 文件传输 (FTP) 邮件发送 (SMTP) 远程登录 (SSH) UDP:用于需要“越快越好”的场景 视频直播/视频会议 在线实时游戏 (如吃鸡、王者荣耀) 语音通话 (VoIP) DNS域名解析 TCP是面向连接的、可靠的协议,通过三次握手、确认重传等机制保证数据正确送达,但速度慢,适合网页、邮件、文件传输。UDP是无连接的、不可靠的协议,不做任何保证,但速度快、延迟低。 应用层的拼包、拆包 TCP 是“面向字节流”的、无边界的协议,它只保证数据按顺序、无丢失地到达,但—— 并不会告诉你消息的边界。 应用层必须自己定义消息边界。 1.固定长度协议 规定每个消息固定长度,比如 100 字节。 优点:实现简单。 缺点:浪费空间,不灵活。 2.特殊分隔符 在每条消息末尾加上特殊字符,比如 \n、#END# 等。 优点:简单直观。 缺点:内容里不能包含分隔符(要转义)。 3.消息长度前缀 在每条消息前加上一个定长的“长度字段”,告诉接收方消息体有多长。 最常用、最通用的方式。 | 4 bytes length | <length> bytes data | TCP保证按序接收(乱序到达,但是内部会重排再传给应用层),根据事先约定的协议,前4个字节是代表这条消息的长度,然后再读取对应长度的字节流,就可以组装成完整的一条消息了。 4.高级协议 像 HTTP、WebSocket、gRPC 等都在 TCP 之上定义了自己的消息边界: HTTP:以请求头中的 Content-Length 或分块编码表示长度。 WebSocket:帧格式中定义了帧长度。 gRPC / Netty:自动处理粘包拆包问题。 HTTP 版本对比表 特性/版本 HTTP/1.0 HTTP/1.1 HTTP/2 连接方式 每次请求都新建 TCP 连接,用完立即关闭(短连接) 默认支持 长连接(Connection: keep-alive),一个 TCP 连接可复用 多路复用:一个 TCP 连接里并发处理多个请求/响应 请求并发 不支持,需要并发就建多个连接 支持管道化(pipelining),但存在队头阻塞,实际应用少 真正解决队头阻塞,多路复用并行传输 带宽利用 头部重复多,浪费带宽 引入 Host 头字段,支持虚拟主机;依然是明文文本传输 头部压缩(HPACK),大幅减少头部开销 传输效率 每次请求-响应一个连接,效率低 长连接提升效率,但仍有队头阻塞问题 二进制分帧、并行传输、服务器推送,效率最高 使用场景 早期 Web 目前最广泛使用(浏览器默认) 大型应用、高并发、移动端、CDN,逐渐普及 HTTP/1.1 解决了 1.0 的短连接问题,但仍然存在队头阻塞、并发效率低、头部冗余的问题。 HTTP/2 的主要优势体现在: 二进制分帧:高效传输,方便扩展; 多路复用:一个连接并发多个请求,解决了 1.1 的队头阻塞; 头部压缩:减少带宽浪费; 服务器推送:服务器可以主动把可能用到的资源(CSS/JS)推给客户端,减少延迟。 访问一个网站的过程 1.建立连接 DNS 解析:浏览器先把域名(如 www.example.com)解析成 IP 地址。 TCP 三次握手:和目标服务器建立 TCP 连接(默认端口 80,若是 HTTPS 还要做 TLS 握手)。 建立 HTTP/1.1 长连接 请求头里会带上 Connection: keep-alive(默认启用),同一个 TCP 连接可以复用多次请求。 2.浏览器先请求 HTML 页面: GET /index.html HTTP/1.1 Host: www.example.com Connection: keep-alive User-Agent: Chrome/... Accept: text/html,application/xhtml+xml 3.服务器返回响应 服务器处理请求,返回 HTML 页面: HTTP/1.1 200 OK Content-Type: text/html Content-Length: 1234 Cache-Control: max-age=3600 <html> ... </html> 4.浏览器解析 HTML 解析 HTML 时,发现里面引用了 CSS、JS、图片 等静态资源。 浏览器会发起新的请求去获取这些资源。 5.并发请求资源 HTTP/1.1 一个 TCP 连接虽然可以复用,但请求必须顺序执行 → 存在队头阻塞。 为了提高并发性能,浏览器会:同时打开多个 TCP 连接(6~8 个/域名),每个连接里顺序下载多个资源; 6.页面渲染 CSS、JS、图片加载完成后,浏览器开始渲染页面。JS 可能会再发起 Ajax 请求(同样走 HTTP/1.1 长连接)。 HTTPS和HTTP的区别是? HTTP 是超文本传输协议,数据以明文方式传输; HTTPS 是基于 SSL/TLS 的加密版 HTTP,通信过程经过加密、认证和完整性校验。 主要区别: 传输安全性: HTTP 明文传输,容易被窃听、篡改、伪造(中间人攻击); HTTPS 通过非对称加密 + 对称加密 + 数字证书三重机制确保保密性、完整性、身份验证。 连接建立: HTTPS 在 TCP 三次握手后还需进行 TLS 握手(协商加密算法、交换密钥); 端口与证书: HTTP 用 80 端口,无证书; HTTPS 用 443 端口,需要 CA 签发证书(如 Let’s Encrypt 免费证书)。 “HTTP 使用 80 端口” 指的是:服务器端(Web Server)默认监听 80 端口,浏览器(客户端)会默认向服务器的 80 端口发起连接请求。 当你在浏览器输入: http://example.com 实际上等价于: http://example.com:80 假设后端java监听8080,那生产环境为什么能直接访问域名不带端口? 原因:只有对外提供 Web 访问的入口服务(网关 / 反向代理)监听 80 端口。 用户访问 → http://www.xxx.com(默认走 80) ↓ DNS 解析 —— 把域名解析成 IP ↓ Nginx 监听 80 端口 ↓ 反向代理到 8080(Spring Boot/Tomcat) 浏览器(80) → Nginx(80) → 内部应用(8080) ,这样外部用户访问时不用加 :8080,通过nginx访问后端服务。 HTTPS能否抓包解密? 抓包本质是监听网络上的数据包。 正常情况:HTTPS 的数据虽然可以被抓到(因为数据包仍然经过网卡),但它是 经过 TLS 加密 的,内容是密文,看不懂。 抓包工具 抓包工具(如 Fiddler、Charles)之所以能“看到明文”,是因为它们在本机充当了一个 中间代理服务器(MITM,中间人) 并安装了自己的“根证书”,拦截并解密 HTTPS 流量。 具体步骤 ① 安装自己的“根证书”到系统/浏览器信任区 ,让浏览器信任它 ② 拦截请求并伪造中间证书,工具假装是服务器,与浏览器建立加密连接,再与真正服务器建立另一个加密连接 这样 Charles 能在中间看到明文内容(相当于翻译官)。 注意:这是本地信任的中间人攻击!因为用户主动信任了 Charles 的证书; 而且不是配置浏览器或者服务器的私钥!!! F12开发者模式 浏览器 F12 的 Network 面板能看到所有该标签页发出的请求与响应(包括 HTTPS 的明文内容),因为浏览器在显示给你之前已经完成了 TLS 解密。但它不能抓取网络层的原始加密包。 为什么能看到 HTTPS 明文? 浏览器本身在内核里完成 TLS 握手并解密数据,DevTools 是运行在浏览器进程内的开发者工具,所以它能读取到浏览器已经解密后的请求/响应内容。 HTTPS连接建立过程 使用的主要技术手段:非对称加密、对称加密、数字证书、摘要算法。 建立过程 1)TCP 三次握手 和普通 HTTP 一样,首先通过三次握手建立 TCP 连接。 2)客户端发起请求 客户端发送支持的 TLS 版本、加密套件列表、随机数(Client Random)。 随机数将用于后续生成会话密钥。 3)服务端响应 服务器确认选择使用的 TLS 版本、加密算法,并返回服务器的 随机数(Server Random)。 服务器同时发送 数字证书(包含公钥、域名信息、签发机构等)。 4)客户端验证证书 客户端检查证书是否由 可信 CA 签发、域名是否匹配、是否过期/吊销。 验证通过后,客户端生成一个 Pre-Master Secret(预主密钥),并用服务器公钥加密后发送给服务端。 5)生成会话密钥 客户端和服务端根据: Client Random Server Random Pre-Master Secret 共同计算出 会话密钥(对称加密密钥)。 6)握手完成 双方用会话密钥加密一段测试数据,互相验证可解密成功。 之后正式使用 对称加密 进行数据传输。 非对称加密 常见非对称加密算法:RSA DSA ECC 使用一对密钥:公钥 (Public Key) 和 私钥 (Private Key)。 这里表现: 客户端用 服务器证书里的公钥 加密 Pre-Master Secret,发送给服务器。 服务器用 私钥 解密,得到 Pre-Master Secret。 对称加密 常见对称加密算法: DES AES 加密和解密使用 同一把密钥。 优点:计算速度快,效率高,适合大规模数据加密。 缺点:密钥分发困难,如果密钥在传输过程中被截获,通信就不安全。 这里表现: Client Random、Server Random、Pre-Master Secret生成 会话密钥。客户端和服务端都有这个密钥,之后的请求响应都用这个加密。 操作系统 多个进程同时执行一个代码块会产生冲突吗? 不会产生内存级别的冲突,因为进程的内存空间是隔离的。 但是,如果这些进程要操作 同一个外部资源(比如:同一个文件、同一个数据库表、同一个 socket),就可能发生冲突或竞争。 例如:两个进程同时写一个文件 → 文件可能被覆盖或写乱,需要 文件锁 来保护。 两个进程同时更新数据库记录 → 可能出现脏数据,需要 事务机制 / 乐观锁 / 悲观锁。 如果是线程呢? 多线程在同一个进程内,会共享堆和方法区的数据。如果多个线程同时执行修改同一个共享变量,就会出现 线程安全问题(比如 i++ 的经典例子)。所以多线程比多进程更容易因为共享数据而冲突,需要 synchronized、ReentrantLock等手段保证安全。 进程和线程和程序区别 程序是蓝图,是静态的代码文件,还没运行; 进程是运行起来的实例,是资源分配的最小单位; 线程是 CPU 调度的最小单位。 1)进程(Process)是程序在系统中的一次运行实例;线程(Thread)是进程内的一个独立执行单元。 2)进程拥有独立的内存空间和系统资源;线程共享进程的内存(堆、方法区等),但有自己的栈和程序计数器。 3)CPU 调度线程执行(线程是最小调度单位),进程之间切换开销更大,线程切换更轻量。 4)进程间通信(IPC)需通过管道、Socket、共享内存等;线程间通信更简单(共享变量即可)。 操作系统调度算法 周转时间 = 完成时间 − 到达时间 等待时间 = 完成时间 − 到达时间 − 运行时间 响应时间 = 第一次开始运行 − 到达时间 算法 是否抢占 简要说明 特点 / 优缺点 FCFS(先来先服务) ❌ 非抢占 按到达先后顺序执行 简单易实现;对短作业不利,平均等待时间较长 SJF(短作业优先) ❌ 非抢占 优先执行运行时间最短的作业 平均等待时间最小,但长作业易“饥饿”;需要已知运行时间 SRTF(最短剩余时间优先) ✅ 抢占式 SJF 到达新作业时比较剩余时间,短者先执行 提高响应速度,但长作业可能长期不运行 HRRN(最高响应比优先) ❌ 非抢占 优先级 = (等待时间 + 运行时间) / 运行时间 兼顾短作业与长作业;避免饥饿;计算复杂度略高 RR(时间片轮转) ✅ 抢占 每个进程分配相等时间片,时间片到就切换 公平性好;时间片太小开销大,太大退化为 FCFS 数据结构 迪杰斯特拉算法 用途:解决 单源最短路径问题 —— 从一个起点出发,找到到所有其他节点的最短路径。 前提:边权重必须是 非负数。 核心思想 利用 贪心策略:每次从未确定的节点中,选择距离起点最近的节点,把它加入“已确定集合”。 然后用新加的点作为中间跳板,计算当前邻接点的最短距离。 循环,直到所有节点都确定最短路径。 算法步骤 初始化: 起点到自身距离设为 0,其余节点设为 ∞。 已确定集合为空。 重复以下操作: 从未确定的节点里,选一个当前距离最小的节点 u。 把 u 加入“已确定集合”。 用 u 更新它的邻居 v: if dist[v] > dist[u] + w(u,v): dist[v] = dist[u] + w(u,v) 直到所有节点都被处理。 笔试选择题 节点的度:指这个节点的子树的数量。 树的结点个数为 n。 树的分支数 = 所有节点的度之和 = n-1 A /|\ B C D / \ E F 度为3的节点有1个(A);度为2的节点有1个(B);度为0的节点有4个 数据库Mysql 什么是约束 约束名称 英文名称 主要作用 示例 主键约束 Primary Key 唯一标识表中每一行数据,且不能为空 PRIMARY KEY (id) 外键约束 Foreign Key 保证一个表中的值引用另一个表中存在的值 FOREIGN KEY (dept_id) REFERENCES department(id) 唯一约束 Unique 确保列中的数据唯一,但可为空 UNIQUE (email) 检查约束 Check 限制列中数据的取值范围 CHECK (age >= 18) 非空约束 Not Null 确保列的值不能为空 name VARCHAR(50) NOT NULL 什么是事务?事务有哪些特性? 什么是事务 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 BEGIN; 和 START TRANSACTION; 都能开启事务; BEGIN; -- 或者 START TRANSACTION; 在 MySQL 的事务型引擎(InnoDB)中,单条 SQL 本身就是一个事务;执行成功自动提交,失败自动回滚; UPDATE users SET balance = balance - 100 WHERE id = 1; 流程实际上是: BEGIN; UPDATE users SET balance = balance - 100 WHERE id = 1; COMMIT; 手动提交事务使用步骤: 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务 -- 开启事务 start transaction ; -- 删除学工部 delete from tb_dept where id = 1; -- 删除学工部的员工 delete from tb_emp where dept_id = 1; 上述的这组SQL语句,如果执行成功,则提交事务 commit ; 上述的这组SQL语句,如果执行失败,则回滚事务 rollback ; 注意:要手动 COMMIT; 或者 ROLLBACK; 才能结束当前事务。 场景 操作结果 数据最终状态 ✅ 所有 SQL 成功执行,输入 COMMIT; 事务提交 数据永久保存 ✅ 所有 SQL 成功执行,但输入 ROLLBACK; 手动回滚 所有修改撤销 ⚠️ 某条 SQL 执行失败,输入 COMMIT; 部分提交 仅前面成功的语句生效,失败语句无效 ⚠️ 某条 SQL 执行失败,输入 ROLLBACK; 全部回滚 所有语句都撤销 Spring 的 @Transactional 注解,就是在 Java 层面自动帮你包裹事务。 事务有哪些特性? 1)原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。 2)一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。 约束层面一致性主要指 数据要符合数据库定义的各种约束,主键约束、外键约束、唯一约束等必须始终成立。 业务层面一致性:部门和该部门下的员工数据全部删除。 3)隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(事务还没commit,那么别的窗口就看不到该修改 )。在 MySQL(InnoDB 引擎)里,隔离性主要是通过 事务隔离级别 + MVCC(多版本并发控制) + 锁机制 来实现的。 SQL 标准定义了 4 种隔离级别(MySQL 都支持): 读未提交 (READ UNCOMMITTED) 能读到别的事务未提交的数据(脏读)。 几乎没隔离,效率最高。 读已提交 (READ COMMITTED) 只能读到别的事务已提交的数据。 Oracle、PostgreSQL 默认级别,避免脏读,但会出现不可重复读。 可重复读 (REPEATABLE READ) MySQL 默认级别。 在同一个事务里,多次读同一行结果一致(避免不可重复读)。 InnoDB 在此级别下还能避免幻读(通过间隙锁)。 串行化 (SERIALIZABLE) 所有事务串行执行(加锁),最安全但效率最低。 4)持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。 事务的四大特性简称为:ACID 第一、二、三范式含义 第一范式: 表中每一列(字段)都必须是原子性的,不能再拆分。 反例: 学号 姓名 电话 001 张三 13888888888, 13999999999 第二范式: 在满足 1NF 的基础上,非主键字段必须完全依赖于主键(如果表的主键是复合主键,则非主键字段必须完全依赖于整个主键,不能只依赖主键的一部分)。 反例: 学号 课程号 学生姓名 成绩 001 C01 张三 90 001 C02 张三 85 主键是(学号, 课程号) “成绩”依赖于(学号, 课程号) → ✅ 完全依赖 “学生姓名”只依赖于学号 → ❌ 部分依赖(不满足 2NF) 关键是需要学号+课程号才能确定一条记录,缺一不可,而这里只需要学号这个姓名就确定了!!! 正确做法: 拆成两张表: 学生表(student) 学号 姓名 001 张三 成绩表(score) 学号 课程号 成绩 001 C01 90 001 C02 85 → 消除部分依赖,满足 2NF。 第三范式 必须先满足 2NF;非主键字段必须直接依赖于主键,不能存在传递依赖。 反例: 学号 姓名 系编号 系名称 001 张三 D01 计算机系 这里: “系编号”依赖于“学号”(主键); “系名称”依赖于“系编号”; → “系名称”间接依赖于主键(学号),出现传递依赖,不满足 3NF。 正确做法: 拆成两张表: 学生表(student) 学号 姓名 系编号 001 张三 D01 系别表(department) 系编号 系名称 D01 计算机系 → 消除了传递依赖,满足 3NF。 B+树结构 计算三层B+树大致存多少数据: 数据页大小:16KB(16384字节) 单条记录大小:1KB(主键+数据,实际通常更小) 内部节点存储内容:指向子节点的指针 + 索引键 指针大小:6字节 索引键大小:8字节(bigint类型) 计算: 叶子节点层(第三层):每个叶子节点页可存储记录数:16KB ÷ 1KB = 16条 每个中间节点页可指向的子节点数:16 × 1024 ÷ (6 + 8) = 1170个 根节点可指向的中间节点数:1170个 1170 × 1170 × 16 = 21,902,400条,一棵三层的B+树在MySQL中可存储约2000万条记录 1. 非叶子节点(Internal Node) 作用:索引导航,决定往哪个子节点走。 内容 键值(key,可能是单列值,也可能是联合索引的前缀组合值)。 子节点指针。 特点 非叶节点里的键值是**“分隔键”**,用于划分范围。 不是表里的真实记录,不存完整数据,也不存主键。 它就像一本书的目录,告诉你“第 1-100 页是 A,101-200 页是 B”。 2. 叶子节点(Leaf Node) 聚簇索引 (PRIMARY KEY):叶子节点存整行数据(所有列)。 二级索引 叶子节点存 索引列 + 主键值 因为二级索引不是数据行存储的地方,需要主键值才能回表。 联合索引:叶子节点存 (col1, col2, …, colN) + 主键值。 它就像图书馆的书架,摆放着书的完整信息(至少包含你要定位的索引列 + 主键)。 3. 排序 & 查找规则 联合索引按 字典序排序 先比第一列; 相同再比第二列; 相同再比第三列; …依此类推。 查找过程: 在非叶子节点里二分定位范围; 进入叶子节点,顺序扫描(或精确匹配)到目标记录。 节点内部查找 页目录分了多个槽,每个槽都指向对应一个分组内的最后一条记录,每个分组内都会包含若干条记录。 通过二分查询,利用槽就能直接定位到记录所在的组,从而就能获取到对应的记录。 举个例子,现在有5个槽,如果想查找主键为3的记录,此时的流程是: 1)通过二分得到槽的中间位置,low=0,high=4,(0+4)/2=2; 2)通过槽定位到第二个分组中的主键为4的记录,4大于3,low=0不变,high=2; 3)继续二分(0+2)/2=1;槽1中主键2小于3,low=1,high=2; 4)此时high-low=1,可以确定值在high即槽2中,但是槽2只能定位到主键为4的记录,又因为槽之间是挨着的,所以可以得到槽1的位置,从槽1入手拿到主键2的记录,然后因为记录是通过单向链表串起来的,往下遍历即可定位到主键3的记录。 聚簇索引和二级索引 聚簇索引和二级索引都用 B+ 树实现,区别在于叶子节点存的内容。聚簇索引的叶子节点存整行数据,所以查主键不需要回表;而二级索引的叶子节点只存索引列和主键值,如果要取不在索引里的列,就要用主键回表去聚簇索引查数据。 什么是最左匹配原则? 当你为多列创建复合索引时,例如: CREATE INDEX idx_d_b_a ON test_optimizer(d, b, a); 索引本质是按照 (d, b, a) 这个顺序生成的 B+Tree。只有从最左边的列开始,连续的条件才能被索引用上。 一旦中间某一列无法利用,就会“断掉”,后面的列通常用不上。 针对的是查询条件的顺序。 例子1: WHERE b=1 AND a=123 没有 d 的条件,最左列 d 没匹配 → 索引基本用不上 例子2: WHERE d=10 AND a=123 有 d,但缺了中间的 b。索引利用度仅止于 (d)。 例子3: WHERE d = 5 AND b > 10 AND a = 123 d = 5 用上了索引,b > 10 也能用上索引,但是由于b是范围索引,因此后面的a = 123 不能再走索引查找,只能在扫描结果里再做过滤。 关键总结!!! WHERE 子句的顺序无关紧要。 索引的定义顺序才重要(最左列必须命中,才能往后用)。 一旦遇到 范围条件(b>1),匹配就停止,后续列不能再用于索引过滤,但可以用于覆盖索引。因为b>1的结果集已经是一整片连续范围,需要顺序扫描,不可以用a 来做定位了 还可以用于索引下推过滤!!! 什么是覆盖索引? 查询所需要的字段(包括 SELECT 的列和 WHERE 条件中用来过滤的列)都能在某一个索引里找到,这样数据库只需扫描索引,不用回表访问数据行。 非覆盖索引:索引只能帮你定位行,还得回到表里再取其他字段。 覆盖索引:索引里就有全部需要的列,直接返回,不用回表。 举例1: CREATE TABLE user ( id INT PRIMARY KEY, name VARCHAR(50), age INT, city VARCHAR(50) ); CREATE INDEX idx_age_city ON user(age, city); SELECT city FROM user WHERE age = 30; 需要的列是 age(用于条件)和 city(用于结果)。 这两个列都在 idx_age_city 里。所以查询只访问索引即可,覆盖索引。 举例2: SELECT name FROM user WHERE age = 30; 过滤用的 age 在索引里。但查询要返回 name,而 name 不在索引里。必须回表去拿 name,所以不是覆盖索引。 索引下推 把本来需要在回表之后才能判断的条件,尽量提前“下推”到索引扫描阶段,用索引本身的数据来过滤掉更多无效行。 例一: CREATE TABLE user ( id INT PRIMARY KEY, name VARCHAR(50), age INT, city VARCHAR(50), KEY idx_age_city (age, city) ); SELECT id FROM user WHERE age > 30 AND city = 'Beijing'; MySQL 5.5 及以前: 使用 age > 30,在索引里做范围扫描,得到一批候选主键 id。 回表(访问聚簇索引/数据页),再判断 city='Beijing' 是否成立。 换句话说,只有最左前缀能利用索引,后续条件只能在回表之后判断。这会带来大量“无效回表”,I/O 消耗很大。 MySQL 5.6 之后: 用 age > 30 在索引里做范围扫描。 在扫描索引的过程中,直接判断索引里是否满足 city='Beijing'。 因为 (age, city) 索引的叶子节点里就有 city 的值。 只有满足两个条件的行,才去回表拿 id。 例二: -- 索引 CREATE INDEX idx_zip_last_addr ON people(zipcode, lastname, address); -- 查询 SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%'; **无索引下推:**lastname LIKE '%etrunia%',注意 % 前缀通配,不能利用 B-Tree 前缀有序性,因此这一步索引无法继续用来缩小范围,索引利用度其实只到第一列 (zipcode)。理论上这会退化成: “找到 zipcode=95054 的所有记录 → 回表 → 再判断 lastname 和 address 条件”。 使用索引下推:MySQL 在扫描 (zipcode, lastname, address) 索引时,已经能拿到 lastname 和 address 的值,因为它们就在复合索引的叶子节点上。 即使 lastname/address 不能帮你缩小索引扫描范围,MySQL 也可以把它们的过滤条件“下推”到索引扫描阶段: 扫描到某条 zipcode=95054 的索引记录时,立刻在索引层检查 lastname LIKE '%etrunia%' AND address LIKE '%Main Street%'。 如果不满足,就直接丢掉,不去回表。 只有满足的记录才回表取出 *。 ICP 的触发条件总结 在 MySQL 里,索引下推的触发条件大致是: 使用了二级索引扫描(ICP 对主键聚簇索引没意义,ICP的核心意义就是减少回表次数)。 查询条件涉及的列都包含在索引中。 某些列因为最左匹配或范围条件导致不能直接用于索引定位,但它们的值在索引叶子节点里存在,可以被“下推”来过滤。 ICP 必须在叶子节点做,因为只有叶子节点才有“完整的、逐条的索引值”。 索引失效的情况 1)对索引列做了函数/计算/表达式 2)模糊匹配以通配符开头 3)不等于和范围条件的特殊情况 WHERE status != 1 WHERE a = 1 AND b > 5 AND c = 3 如果有 (a, b, c) 联合索引,c 就失效了,因为范围查询(b > 5)后索引顺序性被破坏。 4)OR 条件 WHERE id = 1 OR name = 'Tom' 如果 id 和 name 都有索引,可能无法同时利用,MySQL 会选择走一个或直接全表扫描。 5)优化器选择了全表扫描 即使你建了索引,但全表扫描比走索引更快时,MySQL 会直接放弃索引,比如: 表数据很少 过滤条件选中率高(几乎全表都要返回) 6)最左前缀原则 -- 有联合索引 (a, b, c) WHERE b = 2 AND c = 3 -- 索引失效,因为没有用到 a MySQL 大数据排序(ORDER BY)实现机制 MySQL 处理大数据排序时,会根据数据量大小和可用资源采用不同的策略,主要涉及两种核心算法:内存排序和外部排序。 一、排序基本流程 确定排序字段和顺序 读取需要排序的数据 根据数据量选择排序算法 将排序后的数据返回客户端 二、排序模式(sort_mode) 通过 EXPLAIN的 Extra字段可以查看排序模式: 模式 含义 触发条件 Using filesort 需要额外排序 无合适索引时 Using index 索引覆盖排序 索引满足排序顺序 三、大数据排序实现策略 内存排序(单路排序) 适用场景: 排序数据量 < sort_buffer_size 查询字段较少(特别是使用 LIMIT时) 特点: 一次性读取所有需要排序的字段(select *) SELECT * FROM employees ORDER BY salary DESC; -- 示例:需要读取所有列 当使用覆盖索引时: -- 示例:索引覆盖了查询字段 CREATE INDEX idx_salary_name ON employees(salary, name); SELECT name, salary FROM employees ORDER BY salary; 在内存中快速排序(通常使用快速排序) 无需临时文件 配置参数: SET sort_buffer_size = 4M; -- 默认值通常为256K-2M 外部排序(双路排序) 适用场景: 排序数据量 > sort_buffer_size 包含 TEXT/BLOB等大字段 实现过程: 第一次扫描:只读取排序字段和行指针rowid -- 假设employees表有10万行数据 SELECT name FROM employees ORDER BY salary DESC; 强制分阶段读取,即使查询name,第一阶段还是只读取salary和rowid 内存排序:对这些指针进行排序 第二次扫描:根据排序结果回表读取完整数据 多轮归并:如果数据极大,会使用多路归并算法 Mysql8.0为什么移除缓存 工作原理: 当执行一个 SELECT语句时,MySQL 会先计算该语句的“哈希值”作为键(Key)。 然后检查查询缓存中是否存在这个键。 如果存在(即缓存命中),则直接返回缓存的结果集,完全跳过解析、优化和执行等所有后续步骤,效率极高。 如果不存在(即缓存未命中),则正常执行查询流程,并将执行得到的结果集存储到查询缓存中,以便下次使用。 性能原因: 1:严重的锁竞争,查询缓存有一个全局锁(lock_query_cache)。任何试图访问查询缓存的操作(检查缓存或失效缓存)都需要先获得这个全局锁。 2.缓存失效策略过于粗暴,缓存失效是以“表”为粒度的。只要表有任何变动,所有涉及到该表的查询缓存,无论其具体内容是否真的被影响,都会被全部清除。 insert操作背后执行了什么? 1.客户端发送 SQL 应用端通过 **连接器(Connector)**先通过 JDBC 连接建立连接,此时进行账号验证。 把 INSERT ... 语句发送给 MySQL 服务器。 2.语法解析 & 优化 词法分析是哪种执行语句,SELECT还是INSERT..语法分析SQL 语法是否正确 优化器决定具体执行计划(比如选择哪个索引、怎样写数据)。 3.执行器 打开目标表(Table handler)。 检查当前用户是否对目标表有相应权限(如 INSERT 权限)。 检查表的读写锁、元数据锁。 准备调用存储引擎写数据。 4.写入存储引擎 写入 Buffer Pool(内存缓存):新行先写入缓冲区,而不是直接落盘。 更新索引结构:修改 B+ 树,把新记录插入主键索引和必要的二级索引。 5.日志记录 为了保证 崩溃恢复和事务一致性,InnoDB 会记录两类日志: Redo Log(重做日志) 记录“做了什么修改”。 先写入 redo log buffer,再刷到磁盘(prepare → commit 两阶段提交)。 事务提交后,redo log 不会马上清空,而是被标记为“已提交”,之后可以被覆盖(循环写,固定大小的 log file)。 Undo Log(回滚日志) 记录“如何撤销修改”,保证事务回滚时能恢复。 存在系统表空间或 Undo 表空间里。 提交后,Undo Log 并不会立刻删除,因为可能有其他正在执行的快照事务还需要它。 6.返回结果 当 redo log 写入成功,并且 binlog 写入成功(双写保证),事务提交成功。 Mysql二阶段提交 binlog的作用: 1)数据恢复。binlog 会记录所有修改数据的 SQL 语句或行事件(如 INSERT、UPDATE、DELETE 等)。 当数据库崩溃或需要恢复到某个时间点时,可以先恢复最近一次完整备份,再通过回放 binlog 中的事件,将数据恢复到指定时刻。 2)主从复制。主库将写入操作记录在 binlog,从库通过 I/O 线程 读取 binlog,再由 SQL 线程 重放这些事件,实现主从数据同步。 二阶段提交的两个阶段: 准备阶段(Prepare Phase):在事务提交时,MySQL 的 InnoDB 引擎会先写入 redo log,并将其状态标记为 prepare,表示事务已经准备提交但还未真正完成。此时的 redo log 是预提交状态,还未标记为完成提交。 提交阶段(Commit Phase):当 redo log 的状态变为 prepare 后,MySQL Server 会写入 binlog(记录用户的 DML 操作)。binlog 写入成功后,MySQL 会通知 InnoDB,将 redo log 状态改为 commit,完整整个事务的提交过程。 为什么需要二阶段提交 如果没有二阶段提交,关于这两个日志,要么就是先写完 redo log,再写 binlog,或者先写 binlog 再写 redo log。我们来分析一下会产生什么后果。 1) 先写 redo log,再写 binlog redo log 已经落盘 → 主库事务恢复时能看到数据。但 binlog 还没写入 → 从库永远不会收到这个事务。 结果:主库比从库多一条数据(主库领先,从库落后)。 2) 先写 binlog,再写 redo log binlog 已经写入 → 从库收到并重放事务。但 redo log 没写入 → 主库宕机恢复后,事务回滚,数据丢失。 结果:从库比主库多一条数据(从库领先,主库落后)。 有了二阶段提交,MySQL 异常宕机恢复后如何保证数据一致呢? 情况 1:redo log = prepare,binlog 未写入 崩溃恢复时,因为 redo log 没有 commit,binlog 也没记录 → 事务直接回滚,数据一致。 情况 2:redo log = prepare,binlog 已写入但 redo log 未 commit 崩溃恢复时,对比 redo log 与 binlog:一致就提交,不一致就回滚。 所以才需要 **两阶段提交(2PC)**让 redo log 和 binlog 的提交状态严格绑定,要么一起成功,要么一起失败,保证主从一致。 MVCC 多版本并发控制。 ungo log 1)当你执行 insert (1, XX) 时,除了在表里存储 ID 和 name,还会自动记录两个隐藏字段: trx_id:事务 ID。 roll_pointer:指向对应的 undo log。 这个 undo log 是一条类型为 TRX_UNDO_INSERT_REC 的日志,表示它是由 insert 操作产生的。undo log 会保存主键等必要信息,如果事务回滚,InnoDB 就能根据这些信息删除对应记录,从而恢复到执行前的状态。 2)当事务 1 提交后,另一个事务(事务 ID=5)执行 update id=1 时,新的记录会带有 trx_id=5 和新的 roll_pointer,同时生成一条新的 undo log。 这条 undo log 类型是 TRX_UNDO_UPD_EXIST_REC,它会保存: 旧的 trx_id 旧的 roll_pointer 被修改前的字段值(比如 name 原本是 XX) 旧值 → 用于回滚。 old_trx_id + old_roll_pointer → 用于构建版本链,支持 MVCC 下的一致性读。 与 insert 的 undo log 不同: insert 生成的 undo log 在事务提交后就会被清理(因为不会有人需要看到插入之前不存在的版本)。 update 生成的 undo log 则会保留一段时间,用于回滚和多版本并发控制(MVCC,其他事务可能还需要访问旧值)。 3)又有id=11的事务执行 update yes where id=1 ReadView readView 用来判断 某个版本的数据 对当前事务是否可见。 它依赖四个核心概念: creator_trx_id:当前事务 ID。 m_ids:生成 readView 时,系统里所有未提交事务的 ID 集合。 min_trx_id:m_ids 中最小的事务 ID。 max_trx_id:生成 readView 时,系统将分配给下一个事务的 ID(比现有所有事务 ID 都大)。 注意,如果一个事务是查询,它的creator_trx_id 为0 可见性判断流程 判断逻辑是:从最新版本开始,沿着版本链往回找,遇到第一个符合条件的版本就返回。 具体条件: trx_id = creator_trx_id → 说明是当前事务自己修改的,可见。 trx_id < min_trx_id → 修改这个数据的事务在 readView 生成前就提交了,所以可见。 min_trx_id ≤ trx_id < max_trx_id: 如果 trx_id ∈ m_ids(事务未提交),不可见。 如果 trx_id ∉ m_ids(事务已提交),可见。 trx_id ≥ max_trx_id → 说明修改事务在 readView 生成时还没开始,所以不可见。 读已提交下的MVCC 场景说明: 事务 1 已经提交。 事务 5 执行了 update,但还没提交。 此时新开一个事务(事务 ID=6),去查询 select name where id=1。 readView 的关键参数: creator_trx_id = 6 → 当前查询事务的 ID。 m_ids = {5,6} → 活跃事务 ID 集合(未提交的事务)。 min_trx_id = 5 → m_ids 中最小值。 max_trx_id = 7 → 下一个待分配事务 ID。 查询过程: 查询到 id=1 的最新版本,其 trx_id=5。 不小于 min_trx_id,说明不是历史提交版本。 又在 m_ids 集合里,说明事务 5 还没提交。 所以这个版本 不可见。 根据 roll_pointer 追溯到上一个版本(undo log)。 该版本 trx_id=1,小于 min_trx_id=5,说明生成 readView 时它已经提交。 所以这个版本 可见。 然后事务 5 提交 此时再次查询 select name where id = 1,这时候又会生成新的 readView。 此时 creator_trx_id 为 0,因为还是没有修改操作。 此时 m_ids 为 [6],因为事务 5 提交了。 此时 min_trx_id 为 6。 此时 max_trx_id 为 7,此时没有新的事务申请。 同样还是查询的是 ID 为 1 的记录,所以还是先找到 ID 为 1 的这条记录,此时的版本如下 此时最新版本的记录上 trx_id 为 5,比 min_trx_id 小,说明事务已经提交了,是可以访问的,因此返回结果 name 为 NO。 可重复读下的MVCC 可重复读和读已提交的 MVCC 判断版本的过程是一样的,唯一的差别在生成 readView 上。 上面的读已提交每次查询都会重新生成一个新的 readView,而可重复读在第一次生成 readView 之后的所有查询都共用同一个 readView。 套用上面的情境,差别就在第二次执行 select name where id = 1,不会生成新的 readView,而是用之前的 readView,所以第二次查询时: m_ids 还是为 [5,6],虽说事务 5 此时已经提交了,但是这个 readView 是在事务 5 提交之前生成的,所以当前还是认为这两个事务都未提交,为活跃的。 此时 min_trx_id 为 5。 Mysql如何解决幻读 在标准 SQL 隔离级别中,可重复读(REPEATABLE READ)理论上仍可能出现幻读,但在 MySQL 的 InnoDB 引擎中,它“额外”解决了幻读问题。 在 InnoDB 的实现里,可重复读级别下结合了两种机制: MVCC(多版本并发控制) + Next-Key Lock(间隙锁) 普通 SELECT(非锁定读) 使用 MVCC(快照读)。 快照读是通过 ReadView 实现的:事务第一次查询时生成一个一致性视图,之后所有查询都基于这个 ReadView。 因此,即使别的事务插入了新行,当前事务的 ReadView 里看不到它们。 锁定读 如 SELECT ... FOR UPDATE 或 UPDATE、DELETE,也即当前读,能用快照,因为要修改数据。 此时 InnoDB 使用 Next-Key Lock(行锁 + 间隙锁) 来防幻读。 它不仅锁住已存在的记录,还锁住记录之间的“间隙”。 SELECT * FROM user WHERE age BETWEEN 20 AND 30 FOR UPDATE; InnoDB 会加锁: 记录本身(20、30)→ Record Lock 区间 (10,20)、(20,30)、(30,∞) → Gap Lock 这样其他事务: 不能在这些区间内插入新记录; 从而避免“幻影行”出现在当前事务的查询结果里。 Explain查询优化 EXPLAIN 会展示执行计划的关键信息,常见字段有: id:查询中执行步骤的顺序和嵌套关系,id 越大优先级越高。 select_type:查询的类型,比如 SIMPLE、PRIMARY、SUBQUERY、DERIVED 等。 table:当前访问的表。 type:最关键,表示表的访问方式,也就是执行效率。 possible_keys / key:优化器认为可能使用的索引、实际使用的索引。 rows:预计扫描的行数,越少越好。 filtered:返回记录的百分比。 Extra:额外信息,比如 Using index(覆盖索引)、Using where、Using filesort(额外排序)、Using temporary(临时表)。 type 的性能排序(从好到差,大致顺序) system:表只有一行(特殊情况)。 const:通过主键/唯一索引等一次命中。(单表直接查唯一值。) CREATE TABLE user ( id INT PRIMARY KEY, email VARCHAR(100) UNIQUE, name VARCHAR(50) ); EXPLAIN SELECT * FROM user WHERE id = 1; -- type = const eq_ref:唯一索引等值连接。(多表 join 时) ref:普通索引等值匹配,返回多行。 CREATE TABLE product ( id INT PRIMARY KEY, category_id INT, KEY idx_category(category_id) ); EXPLAIN SELECT * FROM product WHERE category_id = 10; -- type = ref range:索引范围扫描(BETWEEN、> < 等)。 EXPLAIN SELECT * FROM product WHERE category_id BETWEEN 1 AND 5; -- type = range index:全索引扫描(比全表稍好)。 EXPLAIN SELECT category_id FROM product; -- 如果只扫索引列,不回表,type = index ALL:全表扫描(最差)。 mysql查询优化 如果查询性能出现问题,我会分层次地进行优化: 首先是 单库层面 的优化,我会通过慢查询日志配合 EXPLAIN 分析执行计划,定位慢 SQL 的具体瓶颈。 针对问题语句,会从 索引设计 入手,比如调整索引结构(如建立组合索引、覆盖索引),避免索引失效,或者通过 SQL 改写减少全表扫描和不必要的排序、临时表。 其次,在业务层面,我会引入 缓存机制(如 Redis),对热点数据进行缓存,降低数据库的读压力,并合理设置缓存策略防止缓存穿透和雪崩。 如果单库性能已达到上限,我会考虑 架构层面的优化,例如: 通过 读写分离 提升并发读性能;(主从集群) 使用 分库分表 或 冷热数据拆分,解决数据量和并发量增长带来的性能瓶颈; 必要时配合异步化、消息队列等手段削峰填谷,进一步提升系统整体吞吐能力。 Mysql删除数据的三种方法 命令 示例 结果 结构是否还在 是否可回滚 DELETE DELETE FROM demo WHERE name='A'; 只删除 name='A' 的那行,剩下 B、C ✅ 保留 ✅ 可回滚(事务内) TRUNCATE TRUNCATE TABLE demo; 表中数据全部清空,B、C 也没了 ✅ 保留 ❌ 不可回滚 DROP DROP TABLE demo; 整个 demo 表被删掉,表结构和数据都没了 ❌ 删除 ❌ 不可回滚 DELETE:删行,可加条件,事务可回滚。 TRUNCATE:清空表,比 DELETE 快,不能回滚。 DROP:连表带结构一起删。 MySQL InnoDB 常见锁对比 锁类型 粒度 作用 是否互斥 常见触发场景 示例 表级锁(Table Lock) 整个表 锁住整张表,其他事务无法并发写 强互斥 LOCK TABLES,DDL 操作(ALTER TABLE) LOCK TABLE t1 WRITE; 行锁(Record Lock) 单条记录 锁住已有的一行,保证行级并发一致性 与同一行冲突 基于索引的 SELECT ... FOR UPDATE、UPDATE SELECT * FROM user WHERE id=1 FOR UPDATE; 间隙锁(Gap Lock) 记录之间的区间 锁住一个范围内的“空隙”,防止幻读 不允许别的事务在该间隙插入 RR 隔离级别下范围查询加锁 SELECT * FROM user WHERE id BETWEEN 10 AND 20 FOR UPDATE; 临键锁(Next-Key Lock) 记录本身 + 前面的间隙 行锁 + 间隙锁组合,防止幻读 会阻止在该范围插入/修改 RR 隔离级别下的范围条件 SELECT * FROM user WHERE id=10 FOR UPDATE;(锁住 id=10 以及 (前一条,10) 间隙) 插入意向锁(Insert Intention Lock) 间隙(特殊) 插入前声明要往某个间隙插入,允许并发插入 不互斥(不同插入位置可并发) INSERT 语句,自动加 INSERT INTO user(id) VALUES(15);(加在 (10,20) 间隙上) 意向锁(Intention Lock) 表级 标记事务准备在某些行加共享/排他锁 与表锁冲突,不与行锁冲突 InnoDB 内部自动加 SELECT * FROM user WHERE id=1 FOR UPDATE; 会自动加 意向排他锁 IX 插入意向锁 之间一般不冲突,与间隙锁/临键锁会冲突。 什么是乐观锁? 乐观锁是一种“并发控制策略”。 核心思想: “我认为别人不会改数据,所以我不加锁,更新时再检查一下数据有没有被改过。” 这个思想可以应用在不同层面上: 数据库层(通过 SQL + version 字段) Java 应用层(通过 CAS、版本号、时间戳等) 数据库层: 在表里加一个字段(version 或 update_time),在 UPDATE 语句时加上版本检查条件 UPDATE user SET balance = balance - 100, version = version + 1 WHERE id = 1 AND version = 5; Java 层 AtomicInteger counter = new AtomicInteger(0); counter.compareAndSet(expectedValue, newValue); compareAndSet() 方法就是典型的乐观锁: 它假设没有其他线程改过值; 如果值没被改(expectedValue 一致),就更新成功; 否则失败(需要重试)。 数据库连接池的底层原理 数据库连接是重量级资源,创建一次 TCP 连接 + 认证 + 分配资源的开销很大,如果每个请求都新建/销毁连接,性能会非常差。因此我们用连接池事先创建好一定数量的连接,后续请求直接复用,减少连接建立开销。 1)预创建与池管理 启动时按配置创建一定数量的连接放到池子里(最小空闲连接数) 用一个容器保存这些连接(常见是阻塞队列)。 2)连接借出与归还 当业务线程需要访问数据库时: 若池中有空闲连接 → 直接取出使用; 若没有空闲连接但尚未达到最大连接数 → 动态创建新连接; 若已达上限 → 等待连接归还或超时报错。 3)并发控制 连接池内部通过 锁(ReentrantLock) 或 CAS + 队列机制 实现高并发下的借还操作安全。 某些连接池(如 HikariCP)采用 无锁队列 + 原子操作 来提升并发性能。 4)健康检查与回收 连接池会周期性地检测空闲连接是否可用: 若连接失效(网络断开、超时) → 自动销毁并重建; 若连接长期空闲 → 主动回收,避免“僵尸连接”; 同时维持池中连接数在配置的最小/最大区间内,防止资源浪费或过载。 5)超时和泄露检测 设置获取连接超时,防止线程长时间阻塞; 某些连接池(如 Druid、HikariCP)支持 连接泄露检测,当连接长期未归还时,会自动打印警告日志,帮助排查潜在问题。 多表查询 students(学生表) student_id name class_id 1 张三 101 2 李四 102 3 王五 101 classes(班级表) class_id class_name teacher_id 101 一年级一班 1001 102 一年级二班 1002 teachers(教师表) teacher_id teacher_name 1001 王老师 1002 李老师 问:想查询每个学生的姓名、班级名称,以及对应的教师姓名。 SELECT s.name AS student_name, c.class_name, t.teacher_name FROM students AS s JOIN classes AS c ON s.class_id = c.class_id JOIN teachers AS t ON c.teacher_id = t.teacher_id; 杂项 UTF-8 名称 类型 作用 类比 Unicode 字符集(标准) 定义“每个字符的唯一编号” “所有语言的字典” UTF-8 / UTF-16 / UTF-32 编码方式(实现) 把 Unicode 的编号存进文件或内存的方式 “字典的存储格式” ASCII 早期的字符集(也是编码) 只有英文和控制符号(共 128 个) “字典最早的简化版” 1)UTF-8是编码规则,本身与编程语言无关。 也就是说:“你” 在 UTF-8 下一定是 E4 BD A0(3 个字节);不会因为语言不同而改变。 2)UTF-8 对于前 128 个字符(U+0000~U+007F)与 ASCII 完全相同。 UTF-8 是“可变长度”的编码 字节数 二进制前缀 说明 示例 1 字节 0xxxxxxx 英文、数字(ASCII) A → 0x41 2 字节 110xxxxx 10xxxxxx 拉丁文扩展 é 3 字节 1110xxxx 10xxxxxx 10xxxxxx 中文、日文、韩文等 你 4 字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx emoji、冷僻字 😊 一个英文字符串:Hello 共5个字节。 中文:你好 共6个字节。 UTF-8和JAVA中的Char有关系吗 UTF-8 是“编码规则”,规定一个字符对应的字节序列(1~4 字节) char 是“Java 的数据类型”,决定的是“Java 内存里一个字符占多大空间”。在java中,char 类型在 内存中永远占用 2 个字节(16 位);它存储的是 Unicode 编码值的 UTF-16 单元。 中文在 UTF-8 编码下是 3 个字节,但那是外部存储格式; Java 内部使用 UTF-16,每个 char 是 2 字节的 Unicode 码单元, 中文(U+4E00–U+9FFF)都在基本平面范围内,用一个 char 就能表示。 例1️⃣ 英文字母 字符:A 层级 表示 占用 UTF-8 0x41 1 字节 Java char 0x0041 2 字节 例2️⃣ 中文字符 字符:你 (Unicode U+4F60) 层级 表示 占用 UTF-8 E4 BD A0 3 字节 Java char 0x4F60 2 字节 MyBatis JDBC 与 MyBatis 的关系 层次 内容 举例 最底层 JDBC 原生 API Connection, Statement, ResultSet 中间层封装 Spring JDBC Template 自动管理连接、关闭资源 ORM 框架 MyBatis / Hibernate 提供 SQL 映射、对象封装、事务管理 简单说: MyBatis 的底层就是在帮你自动调用 JDBC 接口(包括 Statement、Connection、ResultSet)。 例如: @Select("SELECT * FROM user WHERE id = #{id}") User selectById(int id); MyBatis 实际做的就是: 从连接池拿到一个 Connection 创建一个 PreparedStatement(预编译语句对象) 执行 SQL 并拿到 ResultSet 映射结果到 User 对象 关闭资源 PreparedStatement(预编译语句对象): 是 JDBC 提供的一种 预先编译好 SQL 模板、可重复执行 的对象。 防止 SQL 注入 ResultSet(结果集对象) 数据库返回的数据表(查询结果)的 Java 视图。 MyBatis的缓存机制 怎样算在同一个sqlsession: 1.同一个对象实例 SqlSession session = sqlSessionFactory.openSession(); UserMapper mapper1 = session.getMapper(UserMapper.class); UserMapper mapper2 = session.getMapper(UserMapper.class); // mapper1 和 mapper2 使用的是同一个 SqlSession 2.在同一个事务范围内 @Transactional public void processOrders(List<Order> orders) { for (Order order : orders) { User user = userMapper.findById(order.getUserId()); // 处理订单逻辑 } } 一级缓存(本地缓存) 作用范围:SqlSession 级别(默认开启) 特点: 同一个 SqlSession 中执行相同的 SQL 查询时,会直接从缓存中获取结果 执行 INSERT/UPDATE/DELETE 操作或调用 commit()、close()、clearCache()时会清空一级缓存 生命周期:与 SqlSession 相同 二级缓存(全局缓存) 存储位置:JVM 堆内存(SqlSession 内部的一个 HashMap) 作用范围:Mapper 命名空间级别(需要手动配置开启) 配置方式: <mapper namespace="..."> <cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/> <select id="queryGroupBuyProgress" resultType="GroupBuyOrder"> SELECT * FROM group_buy WHERE team_id = #{teamId} </select> </mapper> 特点: 多个 SqlSession 可以共享缓存 缓存数据存储在内存中,可以配置存储到硬盘或其他存储介质 执行 INSERT/UPDATE/DELETE 操作会清空对应命名空间的二级缓存 缓存工作流程 查询顺序:二级缓存 → 一级缓存 → 数据库 更新顺序:数据库 → 清空相关缓存 二级缓存的数据不一致情况: SqlSession1 读取了数据A,并将其缓存 SqlSession2 将数据更新为B(这会清除二级缓存) 但当SqlSession1再次读取时,如果配置不当,可能仍然从自己的缓存中获取到旧的A数据 Redis Redis 是单线程的还是多线程的 Redis 6.0 之前 单线程模型:核心的网络 I/O 和命令执行都在一个主线程里完成。 while (true) { # 1. 监听多个 socket 事件 active_fds = epoll_wait(); # 2. 依次处理每个就绪的 socket for fd in active_fds: readRequest(fd); // 读网络数据 processCommand(fd); // 解析 + 执行命令 sendReply(fd); // 写回响应 } 为什么单线程也快? 纯内存操作; 使用高效的 I/O 多路复用(epoll/kqueue); 数据结构高度优化; 避免了线程切换和锁竞争。 多线程存在的位置:并不是彻底“单线程”,比如: AOF 日志刷盘、RDB 持久化、复制等后台任务本来就是单独线程/子进程。 但核心逻辑——请求解析、命令执行、结果返回——只有一个主线程。 Redis 6.0 之后 引入了 I/O 多线程,但本质上还是 “单线程为主 + 多线程辅助”: 多线程做什么? 主要用于 网络 I/O 的读写,即把请求数据从网络读入内存、把结果写回客户端。 读 socket:从客户端读取数据到内存缓冲区。 写 socket:把执行结果写回客户端。 单线程仍然做什么? 命令解析、数据结构操作、业务逻辑执行依然在主线程完成。 好处:解决高并发场景下,网络读写成为瓶颈的问题。 Redis 的过期删除策略 基本策略 ① 定时删除(Timer) 每个 key 设置过期时间时,都会创建一个定时器,到时间就立刻删除。 优点:内存能及时释放,不会有“脏数据”。 缺点:要维护大量定时器,CPU 消耗大,不适合 Redis 这种高性能场景。 Redis 实际上并没有采用纯定时删除。 ② 惰性删除(Lazy) 客户端访问 key 时,Redis 会先检查它是否过期。 如果过期了,就先删除再返回“不存在”;如果没过期就正常返回。 优点:对 CPU 友好,只有访问时才检查。 缺点:如果有些 key 过期后从未被访问,就会一直占用内存。 ③ 定期删除(Periodic) Redis 会定期(默认每 100ms)随机抽样部分设置了过期时间的 key,检查是否过期,如果过期就清理掉。 优点:在性能和内存之间折中,避免内存被过期 key 堆满。 缺点:清理不一定及时,依赖随机抽样,可能有遗漏。 实际采用的策略 Redis 实际上是 惰性删除 + 定期删除 两种策略结合: 惰性删除保证了“访问时不会读到脏数据”。 定期删除保证了“即便没人访问,也会逐渐释放内存”。 内存淘汰机制(兜底措施) 如果过期 key 清理不及时,导致内存占满,Redis 会触发 内存淘汰策略(7种): noeviction:默认,直接报错,不再写入新数据。 allkeys-lru:所有 key 中淘汰最久未使用的。 volatile-lru:只在设置了过期时间的 key 中淘汰最久未使用的。 allkeys-random:所有 key 中随机淘汰。 volatile-random:只在设置了过期时间的 key 中随机淘汰。 volatile-ttl:淘汰即将过期的 key(TTL 最短)。 Redis主从集群 Redis 主从架构通常用于 数据备份 和 读写分离 场景,非常适合 读多写少 的业务模型。 主节点(Master):负责写操作和数据同步。 从节点(Slave):负责读操作,数据由主节点异步复制过来。 1)如果判断redis从节点是第一次来建立连接? Redis 主从同步依靠一个 复制 ID(replid) 来区分是否为第一次连接: 每个节点在启动时都会生成一个唯一的 replid,默认认为自己是主节点。 当执行 SLAVEOF 或 REPLICAOF 时,从节点会向主节点发起复制请求。 这时主节点会生成一个新的 replid,并把它同步给从节点。 之后: 如果从节点再次发起连接请求,携带的 replid 与主节点一致 → 表示是断线重连(增量复制); 如果 replid 不一致 → 表示是第一次连接(全量复制)。 2)第一次来建立连接,怎么全量复制? 主节点执行 BGSAVE,生成一个 RDB 快照文件。 主节点将 RDB 文件发送给从节点,从节点清空现有数据,加载 RDB。 在加载完成后,主节点会把在此期间新增的命令日志(增量部分)发送给从节点, 确保数据最终同步。 3)Slave如果宕机,少执行一些命令咋办? 如果从节点中途宕机或网络短暂中断,不一定需要重新全量同步。 Redis 通过 复制偏移量 和 复制积压缓冲区 实现 增量复制: 复制偏移量(offset): 主从双方各自维护一个偏移量,表示当前同步到的位置。 复制积压缓冲区(backlog): 主节点在内存中保留一段最近写命令的缓存(默认大小 1MB)。 同步过程: 从节点重连时会携带上次同步的 replid 和 offset; 主节点检查 backlog 中是否包含这段缺失数据; 若包含 → 增量复制:只发送缺失部分; 若不包含(数据太久被覆盖) → 回退到全量复制。 RDB(快照) 方式:某个时间点,把 Redis 整个内存的数据写成一个二进制文件。 记录的是某一时刻的全量状态(snapshot)。 快照之间的所有写入操作不会被记录。 AOF(写日志) 方式:把 Redis 执行的每一条写命令,按顺序追加到日志文件(appendonly.aof)。 特点: 记录的是操作过程,几乎每条写入都能还原。 根据 appendfsync 配置: always → 每次写命令都落盘,理论上不会丢任何写。 everysec(默认)→ 最多丢 1 秒内的写。 no → 可能丢更多,取决于 OS 缓冲。 backlog(复制积压缓冲区) 本质:Redis 主从复制用的一个内存环形缓冲区。 位置:只存在于 Master 节点的内存里。 内容:存放最近一段时间 Master 执行的 写命令流,不是持久化文件。 Redis主从+哨兵 哨兵本质是一个独立运行的进程,可以部署多个实例,形成一个哨兵集群。 它的作用有三个: 监控:定期向主从节点发心跳,判断是否存活。 通知:发现节点宕机,会通知客户端或者其他服务。 自动故障转移:主节点宕机时,选举出一个新的主节点,并让其他从节点改为复制它。 工作流程 正常运行 主节点负责写,从节点负责读,哨兵不断检测主从的健康状态。 主节点故障 哨兵集群通过投票机制确认主节点不可用(超过一定数量的哨兵认为它下线)。 选举出一个从节点作为新的主节点。 故障转移 通知其他从节点去复制新的主节点。 通知客户端更新主节点地址,继续访问。 主观下线:某个 哨兵 觉得主节点不可达(可能是网络原因误判)。 客观下线:当 多数哨兵 都认为主节点不可达时,就进入“客观下线”状态,这个时候,才会真正发起故障转移流程。 Redis分片集群 分片集群可以看作多个主从集群+分片路由机制 哈希槽 Redis Cluster 并不是随便把 key 平均分到节点上,而是用 16384 个固定的哈希槽 (slot) 来管理。 每个 key 先经过哈希计算,然后被分配到某个槽,槽再映射到对应的节点。 路由机制: 计算槽号 算法:CRC16(key) % 16384 即用 CRC16 算法对 key 做哈希,再取模 16384。 得到一个槽号(范围 0 ~ 16383)。 槽到节点的映射 集群启动时,先看有几个主节点,会把 16384 个槽分配给不同的主节点。 比如: 节点 A 管理槽 0 ~ 5460 节点 B 管理槽 5461 ~ 10922 节点 C 管理槽 10923 ~ 16383 定位节点 客户端要访问一个 key 时,先算出槽号。 然后根据槽分布表,找到负责这个槽的主节点,直接发请求过去。 缓存一致性 什么是Cache Aside Pattern? 更新数据库的同时更新缓存。 先删缓存再删数据库 线程A(右边)删除数据,先删Redis;此时换到线程B来查询,发现Redis为空,它去查mysql,查到了旧数据(线程A还没来得及删mysql),然后回写到redis中;此时A缓过神来,把mysql旧数据删除了。这样redis中有数据,但mysql中无,造成了数据的不一致。这种情况出现的概率比较大,因为线程B查询操作一般比线程A更新操作速度快!!! 先删数据库,再删缓存 线程A(左边)先查询redis,未命名,查mysql,查到了数据;此时换到线程B来删除数据,它先删mysql,再删缓存;再轮到A执行,它回写Redis。此时又出现了数据的不一致:redis中有脏数据,mysql中该数据被删了。但这种概率比较低,因此推荐该方法。 默认情况下这种出现概率极低,尽管出现也可以依靠TTL过期来达到最终一致性。如果实在想避免这种短暂的不一致,可以使用延迟双删策略,就是过一段时间后,再主动把缓存删除。 压缩列表 zlbytes(4字节) 作用:记录整个压缩列表占用的总字节数。 目的:用于内存重分配时,无需遍历整个列表即可知道需要分配多少内存。 zltail(4字节) 作用:记录从压缩列表起始地址到最后一个节点(entry)的起始地址的偏移量。 目的:允许程序直接定位到列表尾部,从而在尾部进行 push或 pop操作时非常高效,时间复杂度为 O(1)。 zllen(2字节) 作用:记录压缩列表中包含的节点(entry)数量。 注意:由于它只有 2 字节(16 位),最大能表示 2^16 - 1 = 65535。当节点数超过这个值时,这个字段的值会置为 65535,此时如果需要获取真实节点数,必须遍历整个列表。 entryX(可变长度) 作用:存储实际数据的节点。每个节点可以存储一个字节数组或一个整数值。 特点:为了节省内存,每个节点的长度是可变的,其结构设计得非常精巧(下文详述)。 zlend(1字节) 作用:一个特殊的标记,用于标识压缩列表的结束。 值:恒定为 0xFF(十进制 255)。 每个 entry由三部分组成,其长度都是可变的: previous_entry_length encoding content 1字节或5字节 1字节、2字节或5字节 实际存储的数据 previous_entry_length(前一个节点的长度) 目的:有了这个字段,程序可以从列表的任意位置(特别是尾部)向前遍历。当前节点的地址减去这个长度,就能找到前一个节点的起始地址。 encoding(编码) 作用:这个字段非常关键,它同时编码了两方面信息: content 中存储的数据类型(是整数还是字节数组?) content 的数据长度(如果是字节数组)或整数值的具体类型(如果是整数)。 content(内容) 作用:实际存储节点的值,可以是一个字节数组(如字符串 "hello")或一个整数值(如整数 10086)。 压缩列表是 “时间换空间” 的经典设计。它通过精巧的结构设计,用 CPU 计算时间来换取极致的内存节省。 在 Redis 中,它被用于存储少量、小体积的数据元素。例如: 当 Hash 类型的所有键值对都较小时,底层使用 ziplist。 当 List 的元素都是小字符串时,底层使用 ziplist。 当 Sorted Set 的元素数量和值都较小时,底层使用 ziplist。 跳表 跳表是一种 基于链表的多层有序数据结构,可以看作是“加了多层索引的有序链表”。 普通有序链表查找某个元素需要从头开始,时间复杂度是 O(n)。 跳表在链表基础上增加多级“跳跃索引”,让查找平均复杂度降低到 O(log n),与平衡树接近。 查找 1.从最高层索引开始向右移动,直到下一个节点大于目标值。 2.向下一层继续搜索,重复以上过程。 3.最终在底层链表找到目标元素或确认不存在。 范围查询[x, y]:先定位起点x,再在底层链表顺序遍历,直至超过y。 注意:最底层完整链表被称为 第 0 层(Level 0),是必定存在的底层,包含所有元素。 插入 1.查找新元素应插入的位置。 2.在底层链表插入新节点。 3.通过随机算法(比如抛硬币)决定该节点是否“晋升”为上层索引。 晋升概率常设为 1/2,这样平均每层节点数减半,层数大约是 log n。 Zset底层数据结构 Redis 的 有序集合(ZSet) 就是通过 跳表(SkipList)+ 哈希表(HashMap) 组合实现的 哈希表:擅长根据 key 快速查找(O(1))。 跳表:擅长根据 score 做排序、区间查找(O(log n) + O(k))。 ZSet 的需求既要支持: 通过成员名快速查分数(ZSCORE), 根据分数范围排序输出(ZRANGEBYSCORE、ZREVRANGE 等)。 分布式锁 用什么命令实现锁? SET key value NX EX seconds NX:只有 key 不存在时才设置,避免被覆盖。 EX seconds:设置过期时间,防止死锁。 补充: PX 单位是毫秒 锁过期了怎么办? 看门狗机制: 获取锁时设置默认过期时间(比如 30s)。 后台启动一个定时任务(“看门狗”),每隔一段时间(如 10s)检查持锁线程是否还活着。 如果还在执行,就自动延长锁的过期时间,避免任务没跑完锁就过期。 如果线程挂了,看门狗也会消失,锁自然到期释放。 RedLock算法 1.Redis 使用 主从架构;线程 A 在 主节点(Master) 上执行: SET lock_key mylock NX PX 10000 → 成功获得锁; 2.Redis 异步复制机制下,主节点将这个写操作 异步发送 给从节点; 3.主节点宕机 💥,还没来得及把这条写命令同步给从节点; 4.Sentinel 或其他机制把从节点提升为新的 Master; 5.线程 B 在新的 Master 上执行: GET lock_key → 发现这个锁不存在(因为没有复制过来)。 根本原因:Redis 主从复制是 异步 的,如果主节点在复制完成前宕机,从节点就会丢失那部分数据。 解决方案: RedLock 红锁算法 不依赖主从复制,而是在**多个独立的 Redis 实例(推荐 5 个)**上分别加锁。只要在半数以上节点成功加锁(≥3),就认为加锁成功。 这样即使部分实例宕机,也能保证锁的可靠性。 RabbitMq Rabbit mq怎么保证消息消费的顺序性? 想要最简单的严格顺序:单队列 + 单线程 + prefetch=1 就行,但吞吐拉胯、易被卡。 想要既有顺序又要并发:把 Key 做 hash→shard,每个 shard 单线程消费,不同 shard 并行,既保同 Key 有序,又能扩展。 消息顺序错乱的原因 1)多并发消费 多个消费者同时从一个队列拉消息执行(配置同一个queue),顺序就不可控了 队列中的消息 消费者1 执行耗时 消费者2 执行耗时 最终结果 msg1 1000ms ✔️ msg2 100ms ✔️ 虽然 msg1 在前面,但由于 msg2 执行更快,先被确认,所以“处理顺序”乱了。 2)重试回退(requeue) 失败的消息重新放回队列头或尾,扰乱原有顺序 3)批量预取(prefetch > 1) 消费者一次拿多个消息,哪条先被处理完就先 ack,顺序不再可靠。因为既然消费者批量拉取了,大概率是使用多线程来处理,那么多线程的话就不能保证顺序了!!! 分片 + 单线程消费 在高并发业务中,“要求顺序处理”的通常不是全部消息,而是同一个业务 key 的消息。按 key 有序的原理:“分片 + 单线程消费” 要求: 同一个 key(比如 userId = 123)内的消息,必须按照发送顺序处理 不同 key(userId = 123 vs 456)之间可以并行处理,不要求顺序 举例:假设你要处理 userId 相关消息,希望同一个用户按顺序消费 发消息时: int shard = userId.hashCode() % 4; 发送到:queue.user.shard.0~3 之一 消费时: queue.user.shard.0 → consumer0(串行处理) queue.user.shard.1 → consumer1(串行处理) ... 效果: userId=101 落到 shard 1,所有与之相关的消息在 consumer1 串行处理 userId=202 落到 shard 2,由 consumer2 处理,互不影响 但是以上简单 %N 改 N 会导致大规模迁移,可以使用一致性哈希来解决! 一致性哈希 1)环形空间,假设哈希函数输出的范围是一个 0~2³² 的整数,把它想象成一个“环”,把每个分片(或节点)映射到环上的一个点。 2)每个消息 key 也通过哈希函数算出位置,从该 key 的位置顺时针找到的第一个节点,就是它的归属节点。 3)如果增加一个新节点,只会接管它在环上“前一个节点 → 自己”区间的 key,其它区间的 key 不受影响。 核心步骤 分片路由 生产者按 key → shard 路由到不同队列:queue.user.shard.N。 避免手写 % 带来的重分片风暴,优先考虑: 一致性哈希交换器(x-consistent-hash 插件):只需设置队列权重=分片数,按 routing key 的 hash 自动路由。 每分片单线程消费 每个队列仅 1 个活跃消费者。 设 prefetch=1,同一队列串行处理,避免并发导致“完成顺序≠入队顺序”。 重试/失败处理(关键) 不要直接 requeue 回原队列(会打乱顺序,甚至阻塞后续)。 用 DLX + 延迟(TTL/延迟交换器) 做“定时重试”。同一 key 的失败消息最好: 要么“停到旁路队列”并报警(跳过这条,继续处理其它 key), 要么“阻塞该分片直到重试成功/超时熔断”,以维持该 key 的顺序一致性。 明确“毒丸消息”策略:重试 N 次后送到 死信队列,避免永久卡住分片。 幂等与去重 消费端必须幂等(包括重投递/重复确认场景)。为每条消息携带 msgId/版本号,落库前做去重/比序。 可观测性 监控每个分片队列的堆积、处理时延、失败率;对“热点分片”做自动告警。 注意: 1)数据库侧幂等,利用msgId唯一约束 2)redis侧幂等,SETNX msg:{msgId} 1 EX 86400 3)版本号比序(保证顺序),每条消息携带业务 key(比如 userId)+ 版本号(比如 orderVersion);消费时,查库里该 key 的最新版本 背压机制 背压是一种 流量控制机制,当下游(消费者 / 处理器)处理不过来时,通知上游(生产者)减速或暂停,从而避免系统过载。 常见的背压机制 1)阻塞生产者 生产者往队列放消息,如果队列满了,阻塞等待。 BlockingQueue<String> queue = new ArrayBlockingQueue<>(1000); queue.put("msg"); // 队列满时阻塞 2)丢弃或拒绝策略 队列满了,直接丢弃新消息,或者返回错误给生产者。RabbitMQ 中可以配置: .overflow(QueueBuilder.OverflowPolicy.rejectPublish) 3)生产者端处理 publish 被拒绝 当队列满时,如果用了 rejectPublish 策略,生产者会收到异常: try { rabbitTemplate.convertAndSend("order-queue", orderMessage); } catch (AmqpException e) { // 背压触发:队列已满,生产者需要降速 or 丢弃 Thread.sleep(100); // 简单降速 } 4)限流 (Rate Limit / Prefetch) 默认情况下,消费者会一次性接收尽可能多的消息 开发者需要显式设置: channel.basicQos(50); // 每次最多取 50 条 表示消费者告诉 MQ:一次只给我 N 条,避免自己被压垮。这样消息会堆积在MQ的消息队列中!! Git git merge和git rebase的区别 git merge 把两个分支合并在一起,产生一个新的 merge commit。 保留了两个分支的提交历史。 历史可能会有「分叉」和「合并点」。 git rebase 把一个分支的提交“挪到”另一个分支上,好像在新的基底上重新提交一遍。 没有 merge commit,历史会更干净。 实质上是「修改历史」。 示例: main: A --- B --- C \ feature: D --- E 1)使用merge git checkout main git merge feature Git 会生成一个 新的合并提交(merge commit),把两个分支的历史接到一起: main: A --- B --- C ------- F (merge commit) \ / feature: D --- E --- 历史完整保留(能看到分支是怎么分叉和合并的)。 但历史中会有很多「叉路」,可能显得比较乱。 2)使用 rebase git checkout feature git rebase main Git 会把 feature 的提交 D、E 拿下来,重新放到 main 的最新提交后面,好像是“重新提交”一遍: main: A --- B --- C \ feature: D' --- E'
后端学习
zy123
1年前
0
19
0
2025-04-01
凸优化问题求解
凸优化 核心概念 凸函数 定义:$f(x)$ 是凸函数当且仅当 $$ f(\theta x_1 + (1-\theta)x_2) \leq \theta f(x_1) + (1-\theta)f(x_2), \quad \forall x_1,x_2 \in \text{dom}(f), \theta \in [0,1] $$ 示例:$f(x)=x^2$, $f(x)=e^x$ 验证 $f(x) = x^2$ 是凸函数: 代入 $f(x) = x^2$: $$ (\theta x_1 + (1-\theta) x_2)^2 \leq \theta x_1^2 + (1-\theta) x_2^2 $$ 展开左边: $$ (\theta x_1 + (1-\theta) x_2)^2 = \theta^2 x_1^2 + 2\theta(1-\theta)x_1x_2 + (1-\theta)^2 x_2^2 $$ 右边: $$ \theta x_1^2 + (1-\theta) x_2^2 $$ 计算差值(右边减左边): $$ \theta x_1^2 + (1-\theta) x_2^2 - \theta^2 x_1^2 - 2\theta(1-\theta)x_1x_2 - (1-\theta)^2 x_2^2 $$ 化简: $$ = \theta(1-\theta)x_1^2 + (1-\theta)\theta x_2^2 - 2\theta(1-\theta)x_1x_2 $$ $$ = \theta(1-\theta)(x_1^2 + x_2^2 - 2x_1x_2) $$ $$ = \theta(1-\theta)(x_1 - x_2)^2 \geq 0 $$ 结论: 因为 $\theta \in [0,1]$,所以 $\theta(1-\theta) \geq 0$,且 $(x_1 - x_2)^2 \geq 0$。 因此,右边减左边 $\geq 0$,即: $$ (\theta x_1 + (1-\theta) x_2)^2 \leq \theta x_1^2 + (1-\theta) x_2^2 $$ $f(x)=x^2$ 满足凸函数的定义。 凸集 集合中任意两点的连线仍然完全包含在该集合内。换句话说,这个集合没有“凹陷”的部分。 定义:集合$X$是凸集当且仅当 $$ \forall x_1,x_2 \in X, \theta \in [0,1] \Rightarrow \theta x_1 + (1-\theta)x_2 \in X $$ 示例:超平面、球体 凸优化问题标准形式 $$ \min_x f(x) \quad \text{s.t.} \quad \begin{cases} g_i(x) \leq 0 & (凸不等式约束) \\ h_j(x) = 0 & (线性等式约束) \\ x \in X & (凸集约束) \end{cases} $$ 交替方向乘子法(ADMM) Alternating Direction Method of Multipliers (ADMM) 是一种用于求解大规模优化问题的高效算法,结合了拉格朗日乘子法和分裂方法的优点。 基本概念 优化问题分解 ADMM 的核心思想是将复杂优化问题分解为多个较简单的子问题,通过引入辅助变量将原问题转化为约束优化问题,使子问题独立求解。 拉格朗日乘子 利用拉格朗日乘子处理约束条件,构造增强拉格朗日函数,确保子问题求解时同时考虑原问题的约束信息。 交替更新 通过交替更新子问题的解和拉格朗日乘子,逐步逼近原问题的最优解。 算法流程 问题分解 将原问题分解为两个子问题。假设原问题表示为: $\min_{x, z} f(x) + g(z) \quad \text{s.t.} \quad Ax + Bz = c$ 其中 $f$ 和 $g$ 是凸函数,$A$ 和 $B$ 为给定矩阵。 构造增强拉格朗日函数 引入拉格朗日乘子 $y$,构造增强拉格朗日函数: $L_\rho(x, z, y) = f(x) + g(z) + y^T(Ax+Bz-c) + \frac{\rho}{2}|Ax+Bz-c|^2$ 其中 $\rho > 0$ 控制惩罚项的权重。 交替更新 更新 $x$:固定 $z$ 和 $y$,求解 $\arg\min_x L_\rho(x, z, y)$。 更新 $z$:固定 $x$ 和 $y$,求解 $\arg\min_z L_\rho(x, z, y)$。 更新乘子 $y$:按梯度上升方式更新: $y := y + \rho(Ax + Bz - c)$ 迭代求解 重复上述步骤,直到原始残差和对偶残差满足收敛条件(如 $|Ax+Bz-c| < \epsilon$)。 例子 下面给出一个简单的数值例子,展示 ADMM 在求解分解问题时的迭代过程。我们构造如下问题: $$ \begin{aligned} \min_{x, z}\quad & (x-1)^2 + (z-2)^2 \\ \text{s.t.}\quad & x - z = 0. \end{aligned} $$ 注意:由于约束要求 $x=z$,实际问题等价于 $$ \min_ (x-1)^2 + (x-2)^2, $$ 其解析最优解为: $$ 2(x-1)+2(x-2)=4x-6=0\quad\Rightarrow\quad x=1.5, $$ 因此我们希望得到 $x=z=1.5$。 构造 ADMM 框架 将问题写成 ADMM 标准形式: 令 $$ f(x)=(x-1)^2,\quad g(z)=(z-2)^2, $$ 约束写为 $$ x-z=0, $$ 即令 $A=1$、$B=-1$、$c=0$。 增强拉格朗日函数为 $$ L_\rho(x,z,y)=(x-1)^2+(z-2)^2+y(x-z)+\frac{\rho}{2}(x-z)^2, $$ 其中 $y$ 是拉格朗日乘子,$\rho>0$ 是惩罚参数。为简单起见,我们选取 $\rho=1$。 ADMM 的更新公式 针对本问题可以推导出三个更新步骤: $\arg\min_x; $表示在变量 $x$ 的可行范围内,找到使目标函数 $f(x)$ 最小的 $x$ 的具体值。 $k$ 代表当前的迭代次数 更新 $x$: 固定 $z$ 和 $y$,求解 $$ x^{k+1} = \arg\min_x; (x-1)^2 + y^k(x-z^k)+\frac{1}{2}(x-z^k)^2. $$ 对 $x$ 求导并令其为零: $$ 2(x-1) + y^k + (x-z^k)=0 \quad\Rightarrow\quad (2+1)x = 2 + z^k - y^k, $$ 得到更新公式: $$ x^{k+1} = \frac{2+z^k-y^k}{3}. $$ 更新 $z$: 固定 $x$ 和 $y$,求解 $$ z^{k+1} = \arg\min_z; (z-2)^2 - y^kz+\frac{1}{2}(x^{k+1}-z)^2. $$ 注意:由于 $y(x-z)$ 中关于 $z$ 的部分为 $-y^kz$(常数项 $y^kx$ 可忽略),求导得: $$ 2(z-2) - y^k - (x^{k+1}-z)=0 \quad\Rightarrow\quad (2+1)z = 4 + y^k + x^{k+1}, $$ 得到更新公式: $$ z^{k+1} = \frac{4+y^k+x^{k+1}}{3}. $$ 更新 $y$: 按梯度上升更新乘子: $$ y^{k+1} = y^k + \rho,(x^{k+1}-z^{k+1}). $$ 这里 $\rho=1$,所以 $$ y^{k+1} = y^k + \bigl(x^{k+1}-z^{k+1}\bigr). $$ 数值迭代示例 第 1 次迭代: 更新 $x$: $$ x^1 = \frac{2+z^0-y^0}{3}=\frac{2+0-0}{3}=\frac{2}{3}\approx0.667. $$ 更新 $z$: $$ z^1 = \frac{4+y^0+x^1}{3}=\frac{4+0+0.667}{3}\approx\frac{4.667}{3}\approx1.556. $$ 更新 $y$: $$ y^1 = y^0+(x^1-z^1)=0+(0.667-1.556)\approx-0.889. $$ 第 2 次迭代: 更新 $x$: $$ x^2 = \frac{2+z^1-y^1}{3}=\frac{2+1.556-(-0.889)}{3}=\frac{2+1.556+0.889}{3}\approx\frac{4.445}{3}\approx1.4817. $$ 更新 $z$: $$ z^2 = \frac{4+y^1+x^2}{3}=\frac{4+(-0.889)+1.4817}{3}=\frac{4-0.889+1.4817}{3}\approx\frac{4.5927}{3}\approx1.5309. $$ 更新 $y$: $$ y^2 = y^1+(x^2-z^2)\approx -0.889+(1.4817-1.5309)\approx -0.889-0.0492\approx -0.938. $$ 第 3 次迭代: 更新 $x$: $$ x^3 = \frac{2+z^2-y^2}{3}=\frac{2+1.5309-(-0.938)}{3}=\frac{2+1.5309+0.938}{3}\approx\frac{4.4689}{3}\approx1.4896. $$ 更新 $z$: $$ z^3 = \frac{4+y^2+x^3}{3}=\frac{4+(-0.938)+1.4896}{3}\approx\frac{4.5516}{3}\approx1.5172. $$ 更新 $y$: $$ y^3 = y^2+(x^3-z^3)\approx -0.938+(1.4896-1.5172)\approx -0.938-0.0276\approx -0.9656. $$ 从迭代过程可以看出: $x$ 和 $z$ 的值在不断调整,目标是使两者相等,从而满足约束。 最终随着迭代次数增加,$x$ 和 $z$ 会收敛到约 1.5,同时乘子 $y$ 收敛到 $-1$(这与 KKT 条件相符)。 应用领域 大规模优化 在大数据、机器学习中利用并行计算加速求解。 信号与图像处理 用于去噪、压缩感知等稀疏表示问题。 分布式计算 在多节点协同场景下求解大规模问题。 优点与局限性 优点 局限性 分布式计算能力 小规模问题可能收敛较慢 支持稀疏性和正则化 参数 $\rho$ 需精细调节 收敛性稳定 — KKT 条件 KKT 条件是用于求解约束优化问题的一组必要条件,特别适用于非线性规划问题。当目标函数是非线性的,并且存在约束时,KKT 条件提供了优化问题的最优解的必要条件。 一般形式 考虑优化问题: $$ \min_x f(x) $$ 约束条件: $$ g_i(x) \leq 0, \quad i = 1, 2, \dots, m $$ $$ h_j(x) = 0, \quad j = 1, 2, \dots, p $$ KKT 条件 1. 拉格朗日函数 构造拉格朗日函数: $$ \mathcal{L}(x, \lambda, \mu) = f(x) + \sum_{i=1}^m \lambda_i g_i(x) + \sum_{j=1}^p \mu_j h_j(x) $$ 其中: $\lambda_i$ 是不等式约束的拉格朗日乘子 $\mu_j$ 是等式约束的拉格朗日乘子 2. 梯度条件(驻点条件) $$ \nabla_x \mathcal{L}(x, \lambda, \mu) = 0 $$ 即: $$ \nabla f(x) + \sum_{i=1}^m \lambda_i \nabla g_i(x) + \sum_{j=1}^p \mu_j \nabla h_j(x) = 0 $$ 3. 原始可行性条件 $$ g_i(x) \leq 0, \quad i = 1, 2, \dots, m $$ $$ h_j(x) = 0, \quad j = 1, 2, \dots, p $$ 4. 对偶可行性条件 $$ \lambda_i \geq 0, \quad i = 1, 2, \dots, m $$ 5. 互补松弛性条件 $$ \lambda_i g_i(x) = 0, \quad i = 1, 2, \dots, m $$ (即:$\lambda_i > 0 \Rightarrow g_i(x) = 0$,或 $g_i(x) < 0 \Rightarrow \lambda_i = 0$) 示例: 我们有以下优化问题: $$ \min_x \quad f(x) = x^2 \\ \text{s.t.} \quad g(x) = x - 1 \leq 0 $$ 首先,我们可以直观地理解这个问题: 目标函数f(x)=x²是一个开口向上的抛物线,无约束时最小值在x=0 约束条件x-1≤0意味着x≤1 所以我们需要在x≤1的范围内找f(x)的最小值 显然,无约束最小值x=0已经满足x≤1的约束,因此x=0就是最优解。但让我们看看KKT条件如何形式化地得出这个结论。 1. 构造拉格朗日函数 拉格朗日函数为: $$ \mathcal{L}(x, \lambda) = x^2 + \lambda(x-1), \quad \lambda \geq 0 $$ 这里λ是拉格朗日乘子,必须非负(因为是不等式约束)。 2. KKT条件 KKT条件包括: 平稳性条件:∇ₓℒ = 0 原始可行性:g(x) ≤ 0 对偶可行性:λ ≥ 0 互补松弛性:λ·g(x) = 0 平稳性条件 对x求导: $$ \frac{\partial \mathcal{L}}{\partial x} = 2x + \lambda = 0 \quad (1) $$ 互补松弛性 $$ \lambda(x-1) = 0 \quad (2) $$ 这意味着有两种情况: 情况1:λ=0 情况2:x-1=0(即x=1) 情况1:λ=0 步骤 计算过程 结果 平稳性条件 $2x + 0 = 0 \Rightarrow x = 0$ $x = 0$ 原始可行性 $g(0) = 0 - 1 = -1 \leq 0$ 满足 对偶可行性 $\lambda = 0 \geq 0$ 满足 互补松弛性 $0 \cdot (-1) = 0$ 满足 情况2:x=1 步骤 计算过程 结果 平稳性条件 $2(1) + \lambda = 0 \Rightarrow \lambda = -2$ $\lambda = -2$ 对偶可行性 $\lambda = -2 \geq 0$ 不满足(乘子为负) 唯一满足所有KKT条件的解是x=0, λ=0。 总结 KKT 条件通过拉格朗日乘子法将约束和目标函数结合,为求解约束优化问题提供了必要的最优性条件。其核心是: 拉格朗日函数的梯度为零 原始约束和对偶约束的可行性 互补松弛性
科研
zy123
1年前
0
11
0
2025-03-31
KAN
KAN Kolmogorov-Arnold表示定理 该定理表明,任何多元连续函数都可以表示为有限个单变量函数的组合。 对于任意一个定义在$[0,1]^n$上的连续多元函数: $$ f(x_1, x_2, \ldots, x_n), $$ 存在**单变量连续函数** $\phi_{q}$ 和 $\psi_{q,p}$(其中 $q = 1, 2, \ldots, 2n+1$,$p = 1, 2, \ldots, n$),使得: $$ f(x_1, \ldots, x_n) = \sum_{q=1}^{2n+1} \phi_{q}\left( \sum_{p=1}^{n} \psi_{q,p}(x_p) \right). $$ 即,$f$可以表示为$2n+1$个“外层函数”$\phi_{q}$和$n \times (2n+1)$个“内层函数”$\psi_{q,p}$的组合。 和MLP的联系 Kolmogorov-Arnold定理 神经网络(MLP) 外层函数 $\phi_q$ 的叠加 输出层的加权求和(线性组合) + 激活函数 内层函数 $\psi_{q,p}$ 的线性组合 隐藏层的加权求和 + 非线性激活函数 固定 $2n+1$ 个“隐藏单元” 隐藏层神经元数量可以自由设计,依赖于网络的深度和宽度 严格的数学构造(存在性证明) 通过数据驱动的学习(基于梯度下降等方法)来优化参数 和MLP的差异 浅层结构(一个隐藏层)的数学表达与模型设计 模型 数学公式 模型设计 MLP $f(x) \approx \sum_{i=1}^{N} a_i \sigma(w_i \cdot x + b_i)$ 线性变换后再跟非线性激活函数(RELU) KAN $f(x) = \sum_{q=1}^{2n+1} \Phi_q \left( \sum_{p=1}^n \phi_{q,p}(x_p) \right)$ 可学习激活函数(如样条)在边上,求和操作在神经元上 边上的可学习函数: $\phi_{q,p}(x_p)$(如B样条) 求和操作:$\sum_{p=1}^n \phi_{q,p}(x_p)$ 深层结构的数学表达与模型设计 模型 数学公式 模型设计 MLP $\text{MLP}(x) = (W_3 \circ \sigma_2 \circ W_2 \circ \sigma_1 \circ W_1)(x)$ 交替的线性层($W_i$)和固定非线性激活函数($\sigma_i$)。 KAN $\text{KAN}(x) = (\Phi_3 \circ \Phi_2 \circ \Phi_1)(x)$ 每一层都是单变量函数的组合($\Phi_i$),每一层的激活函数都可以进行学习 传统MLP的缺陷 梯度消失和梯度爆炸: 与其他传统的激活函数(如 Sigmoid 或 Tanh)一样,MLP 在进行反向传播时有时就会遇到梯度消失/爆炸的问题,尤其当网络层数过深时。当它非常小或为负大,网络会退化;连续乘积会使得梯度慢慢变为 0(梯度消失)或变得异常大(梯度爆炸),从而阻碍学习过程。 参数效率: MLP 常使用全连接层,每层的每个神经元都与上一层的所有神经元相连。尤其是对于大规模输入来说,这不仅增加了计算和存储开销,也增加了过拟合的风险。效率不高也不够灵活。 处理高维数据能力有限:MLP 没有利用数据的内在结构(例如图像中的局部空间相关性或文本数据的语义信息)。例如,在图像处理中,MLP 无法有效地利用像素之间的局部空间联系,这很典型在图像识别等任务上的性能不如卷积神经网络(CNN)。 长依赖问题: 虽然 MLP 理论上可以逼近任何函数,但在实际应用中,它们很难捕捉到序列中的长依赖关系(例如句子跨度很长)。这让人困惑:如何把前后序列的信息互相处理?而自注意力(如 transformer)在这类任务中表现更好。 但无论CNN/RNN/transformer怎么改进,都躲不掉MLP这个基础模型根上的硬伤,即线性组合+激活函数的模式。 KAN网络 主要贡献: 过去的类似想法受限于原始的Kolmogorov-Arnold表示定理(两层网络,宽度为2n+12n+1),未能利用现代技术(如反向传播)进行训练。 KAN通过推广到任意宽度和深度的架构,解决了这一限制,同时通过实验验证了KAN在“AI + 科学”任务中的有效性,兼具高精度和可解释性。 B样条(B-spline) 是一种通过分段多项式函数的线性组合构造的光滑曲线,其核心思想是利用局部基函数(称为B样条基函数)来表示整个曲线。 形式上,一个B样条函数通常表示为基函数的线性组合: $$ S(t) = \sum_{i=0}^{n} c_i \cdot B_i(t) $$ 其中: $B_i(t)$ 是 B样条基函数(basis functions); $c_i$ 是 控制点 或系数(可以来自数据、拟合、插值等); $S(t)$ 是最终的 B样条曲线 或函数。 每个基函数只在某个局部区间内非零,改变一个控制点只会影响曲线的局部形状。 示例:基函数定义 $B_0(t)$ - 支撑区间[0,1] $$ B_0(t) = \begin{cases} 1 - t, & 0 \leq t < 1,\\ 0, & \text{其他区间}. \end{cases} $$ $B_1(t)$ - 支撑区间[0,2] $$ B_1(t) = \begin{cases} t, & 0 \leq t < 1, \\ 2 - t, & 1 \leq t < 2, \\ 0, & \text{其他区间}. \end{cases} $$ $B_2(t)$ - 支撑区间[1,3] $$ B_2(t) = \begin{cases} t - 1, & 1 \leq t < 2, \\ 3 - t, & 2 \leq t < 3, \\ 0, & \text{其他区间}. \end{cases} $$ $B_3(t)$ - 支撑区间[2,4] $$ B_3(t) = \begin{cases} t - 2, & 2 \leq t < 3, \\ 4 - t, & 3 \leq t \leq 4, \\ 0, & \text{其他区间}. \end{cases} $$ 假设用该基函数对$f(t) = \sin\left(\dfrac{\pi t}{4}\right)$在[0,4]区间上拟合 $$ S(t) = 0 \cdot B_0(t) + 0.7071 \cdot B_1(t) + 1 \cdot B_2(t) + 0.7071 \cdot B_3(t) $$ 网络结构: 左图: 节点(如$x_{l,i}$)表示第$l$层第$i$个神经元的输入值 边(如$\phi_{l,j,i}$)表示可学习的激活函数(权重) 下一层节点的值计算: $$x_{l+1,j} = \sum_i \phi_{l,j,i}(x_{l,i})$$ 右图:
论文
zy123
1年前
0
18
0
2025-03-23
线性代数
线性代数 线性变换 每列代表一个基向量,行数代码这个基向量所张成空间的维度,二行三列表示二维空间的三个基向量。 二维标准基矩阵(单位矩阵): $$ \begin{bmatrix} 1 & 0 \ 0 & 1 \end{bmatrix} = \begin{bmatrix} | & | \ \mathbf{i} & \mathbf{j} \ | & | \end{bmatrix} $$ 三维标准基矩阵(单位矩阵): $$ \begin{bmatrix} 1 & 0 & 0 \ 0 & 1 & 0 \ 0 & 0 & 1 \end{bmatrix} = \begin{bmatrix} | & | & | \ \mathbf{i} & \mathbf{j} & \mathbf{k} \ | & | & | \end{bmatrix} $$ 矩阵乘向量 在 3blue1brown 的“线性代数的本质”系列中,他把矩阵乘向量的运算解释为线性组合和线性变换的过程。具体来说: 计算方法 给定一个 $ m \times n $ 的矩阵 $ A $ 和一个 $ n $ 维向量 $ \mathbf = [x_1, x_2, \dots, x_n]^T $,矩阵与向量的乘积可以表示为: $$ A\mathbf = x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 + \cdots + x_n \mathbf{a}_n $$ 其中,$\mathbf{a}_i$ 表示 $ A $ 的第 $ i $ 列向量。也就是说,我们用向量 $\mathbf $ 的各个分量作为权重,对矩阵的各列进行线性组合。 例如:矩阵 $ A $ 是一个二阶矩阵: $$ A = \begin{bmatrix} a & b \ c & d \end{bmatrix} $$ 向量 $ \mathbf $ 是一个二维列向量: $$ \mathbf = \begin{bmatrix} x \ y \end{bmatrix} $$ 可以将这个乘法看作是用 $ x $ 和 $ y $ 这两个数,分别对矩阵的两列向量进行加权: $$ A\mathbf = x \cdot \begin{bmatrix} a \ c \end{bmatrix} + y \cdot \begin{bmatrix} b \ d \end{bmatrix} $$ 也就是说,矩阵乘向量的结果,是“矩阵每一列”乘以“向量中对应的分量”,再把它们加起来。 背后的思想 分解为基向量的组合: 任何向量都可以看作是标准基向量的线性组合。矩阵 $ A $ 在几何上代表了一个线性变换,而标准基向量在这个变换下会分别被映射到新的位置,也就是矩阵的各列。 构造变换: 当我们用 $\mathbf $ 的分量对这些映射后的基向量加权求和时,就得到了 $ \mathbf $ 在变换后的结果。这种方式不仅方便计算,而且直观地展示了线性变换如何“重塑”空间——每一列告诉我们基向量被如何移动,然后这些移动按比例组合出最终向量的位置。 矩阵乘矩阵 当你有两个矩阵 $ A $ 和 $ B $,矩阵乘法 $ AB $ 实际上代表的是: 先对向量应用 $ B $ 的线性变换,再应用 $ A $ 的线性变换。 也就是说: $$ (AB)\vec{v} = A(B\vec{v}) $$ 3blue1brown 的直觉解释: 矩阵 B:提供了新的变换后基向量 记住:矩阵的每一列,表示标准基向量 $ \mathbf{e}_1, \mathbf{e}_2 $ 在变换后的样子。 所以: $ B $ 是一个变换,它把空间“拉伸/旋转/压缩”成新的形状; $ A $ 接着又对这个已经变形的空间进行变换。 例: $$ A = \begin{bmatrix} 2 & 0 \\ 0 & 3 \end{bmatrix}, \quad B = \begin{bmatrix} 1 & -1 \\ 1 & 1 \end{bmatrix} $$ $ B $ 的列是: $ \begin{bmatrix} 1 \ 1 \end{bmatrix} $ → 第一个标准基向量变形后的位置 $ \begin{bmatrix} -1 \ 1 \end{bmatrix} $ → 第二个标准基向量变形后的位置 我们计算: $ A \cdot \begin{bmatrix} 1 \ 1 \end{bmatrix} = \begin{bmatrix} 2 \ 3 \end{bmatrix} $ $ A \cdot \begin{bmatrix} -1 \ 1 \end{bmatrix} = \begin{bmatrix} -2 \ 3 \end{bmatrix} $ 所以: $$ AB = \begin{bmatrix} 2 & -2 \\ 3 & 3 \end{bmatrix} $$ 这个新矩阵 $ AB $ 的列向量,表示标准基向量在经历了 “先 B 再 A” 的变换后,落在了哪里。 行列式 3blue1brown讲解行列式时,核心在于用几何直观来理解行列式的意义: 缩放比例!!! 体积(或面积)的伸缩因子 对于二维空间中的2×2矩阵,行列式的绝对值表示该矩阵作为线性变换时,对单位正方形施加变换后得到的平行四边形的面积。类似地,对于三维空间中的3×3矩阵,行列式的绝对值就是单位立方体变换后的平行六面体的体积。也就是说,行列式告诉我们这个变换如何“拉伸”或“压缩”空间。 方向的指示(有向面积或体积) 行列式不仅仅给出伸缩倍数,还通过正负号反映了变换是否保持了原来的方向(正)还是发生了翻转(负)。例如,在二维中,如果行列式为负,说明变换过程中存在翻转(类似镜像效果)。 变换的可逆性 当行列式为零时,说明该线性变换把空间压缩到了低维(例如二维变一条线,三维变成一个平面或线),这意味着信息在变换过程中丢失,变换不可逆。 逆矩阵、列空间、零空间 逆矩阵 逆矩阵描述了一个矩阵所代表的线性变换的**“反过程”**。假设矩阵 $A$ 对空间做了某种变换(比如旋转、拉伸或压缩),那么 $A^{-1}$ 就是把这个变换“逆转”,把变换后的向量再映射回原来的位置。 前提是$A$ 是可逆的,即它对应的变换不会把空间压缩到更低的维度。 秩 秩等于矩阵列向量(或行向量)所生成的空间的维数。例如,在二维中,如果一个 $2 \times 2$ 矩阵的秩是 2,说明这个变换把平面“充满”;如果秩为 1,则所有输出都落在一条直线上,说明变换“丢失”了一个维度。 列空间 列空间是矩阵所有列向量的线性组合所构成的集合(也可以说所有可能的输出向量$A\mathbf $所构成的集合)。 比如一个二维变换的列空间可能是整个平面,也可能只是一条直线,这取决于矩阵的秩。 零空间 零空间(又称核、kernel)是所有在该矩阵作用(线性变换$A$)下变成零向量的输入向量的集合。 它展示了变换中哪些方向被“压缩”成了一个点(原点)。例如,在三维中,如果一个矩阵将所有向量沿某个方向压缩到零,那么这个方向构成了零空间。 零空间解释了$Ax=0$的解的集合,就是齐次的通解。如果满秩,零空间只有唯一解零向量。 求解线性方程 设线性方程组写作 $$ A\mathbf = \mathbf{b} $$ 这相当于在问:“有没有一个向量 $\mathbf $ ,它经过矩阵 $A$ 的变换后,恰好落在 $\mathbf{b}$ 所在的位置?” 如果 $\mathbf{b}$ 落在 $A$ 的列空间内,那么就存在解。解可能是唯一的(当矩阵满秩时)或无穷多(当零空间非平凡时)。 如果 $\mathbf{b}$ 不在列空间内,则说明 $\mathbf{b}$ 不可能由 $A$ 的列向量线性组合得到,这时方程组无解。 唯一解对应于所有这些几何对象在一点相交; 无限多解对应于它们沿着某个方向重合; 无解则说明这些对象根本没有公共交点。 基变换 新基下的变换矩阵 $A_C$ 为: $$ A_C = P^{-1} A P $$ $P$:从原基到新基的基变换矩阵(可逆),$P$的每一列代表了新基中的一个基向量 $A$:线性变换 $T$ 在原基下的矩阵表示 原来空间中进行$A$线性变换等同于新基的视角下进行 $A_C$ 变换 点积、哈达马积 向量点积(Dot Product) 3blue1brown认为,两个向量的点乘就是将其中一个向量转为线性变换。 假设有两个向量 $$ \mathbf{v} = \begin{bmatrix} v_1 \\ v_2 \end{bmatrix}, \quad \mathbf{w} = \begin{bmatrix} w_1 \\ w_2 \end{bmatrix}. $$ $$ \mathbf{v} \cdot \mathbf{w} =\begin{bmatrix} v_1 & v_2 \end{bmatrix}\begin{bmatrix} w_1 \\ w_2 \end{bmatrix}=v_1w_1 + v_2w_2.. $$ 结果: 点积的结果是一个标量(即一个数)。 几何意义: 点积可以衡量两个向量的相似性,或者计算一个向量在另一个向量方向上的投影。 哈达马积(Hadamard Product) 定义: 对于两个向量 $\mathbf{u} = [u_1, u_2, \dots, u_n]$ 和 $\mathbf{v} = [v_1, v_2, \dots, v_n]$,它们的哈达马积定义为: $$ \mathbf{u} \circ \mathbf{v} = [u_1 v_1, u_2 v_2, \dots, u_n v_n]. $$ 结果: 哈达马积的结果是一个向量,其每个分量是对应位置的分量相乘。 几何意义: 哈达马积通常用于逐元素操作,比如在神经网络中对两个向量进行逐元素相乘。 矩阵也有哈达马积!。 特征值和特征向量 设矩阵: $$ A = \begin{bmatrix} 2 & 1 \\ 0 & 3 \end{bmatrix} $$ 步骤 1:求特征值 构造特征方程: $$ \det(A - \lambda I) = \det\begin{bmatrix} 2-\lambda & 1 \\ 0 & 3-\lambda \end{bmatrix} = (2-\lambda)(3-\lambda) - 0 = 0 $$ 解得: $$ (2-\lambda)(3-\lambda) = 0 \quad \Longrightarrow \quad \lambda_1 = 2,\quad \lambda_2 = 3 $$ 步骤 2:求特征向量 对于 $\lambda_1 = 2$: 解方程: $$ (A - 2I)\mathbf = \begin{bmatrix} 2-2 & 1 \\ 0 & 3-2 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} 0 & 1 \\ 0 & 1 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} x_2 \\ x_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} $$ 从第一行 $x_2 = 0$。因此特征向量可以写成: $$ \mathbf{v}_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix} \quad (\text{任意非零常数倍}) $$ 对于 $\lambda_2 = 3$: 解方程: $$ (A - 3I)\mathbf = \begin{bmatrix} 2-3 & 1 \\ 0 & 3-3 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} -1 & 1 \\ 0 & 0 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} -x_1+x_2 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} $$ 从第一行得 $-x_1 + x_2 = 0$ 或 $x_2 = x_1$。因此特征向量可以写成: $$ \mathbf{v}_2 = \begin{bmatrix} 1 \\ 1 \end{bmatrix} \quad (\text{任意非零常数倍}) $$ 设一个对角矩阵: $$ D = \begin{bmatrix} d_1 & 0 \\ 0 & d_2 \end{bmatrix} $$ $$ \lambda_1 = d_1,\quad \lambda_2 = d_2 $$ 对角矩阵的特征方程为: $$ \det(D - \lambda I) = (d_1 - \lambda)(d_2 - \lambda) = 0 $$ 因此特征值是: $$ \lambda_1 = d_1,\quad \lambda_2 = d_2 $$ 对于 $\lambda_1 = d_1$,方程 $(D-d_1I)\mathbf =\mathbf{0}$ 得到: $$ \begin{bmatrix} 0 & 0 \\ 0 & d_2-d_1 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} 0 \\ (d_2-d_1)x_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} $$ 若 $d_1 \neq d_2$,则必须有 $x_2=0$,而 $x_1$ 可任意取非零值,因此特征向量为: $$ \mathbf{v}_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix} $$ 对于 $\lambda_2 = d_2$,类似地解得: $$ \mathbf{v}_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix} $$ 矩阵乘法 全连接神经网络 其中: $a^{(0)}$ 是输入向量,表示当前层的输入。 $\mathbf{W}$ 是权重矩阵,表示输入向量到输出向量的线性变换。 $b$ 是偏置向量,用于调整输出。 $\sigma$ 是激活函数(如 ReLU、Sigmoid 等),用于引入非线性。 输入向量 $a^{(0)}$: $$ a^{(0)} = \begin{pmatrix} a_0^{(0)} \\ a_1^{(0)} \\ \vdots \\ a_n^{(0)} \end{pmatrix} $$ 这是一个 $n+1$ 维的列向量,表示输入特征。 权重矩阵 $\mathbf{W}$: $$ \mathbf{W} = \begin{pmatrix} w_{0,0} & w_{0,1} & \cdots & w_{0,n} \\ w_{1,0} & w_{1,1} & \cdots & w_{1,n} \\ \vdots & \vdots & \ddots & \vdots \\ w_{k,0} & w_{k,1} & \cdots & w_{k,n} \\ \end{pmatrix} $$ 这是一个 $k \times (n+1)$ 的矩阵,其中 $k$ 是输出向量的维度,$n+1$ 是输入向量的维度。 偏置向量 $b$: $$ b = \begin{pmatrix} b_0 \\ b_1 \\ \vdots \\ b_k \end{pmatrix} $$ 这是一个 $k$ 维的列向量,用于调整输出。 在传统的连续时间 RNN 写法里,常见的是 $$ \sum_{j} W_{ij} \, \sigma(x_j), $$ 这代表对所有神经元 $j$ 的激活 $\sigma(x_j)$ 做加权求和,再求和到神经元 $i$。 如果拆开来看,每个输出分量也都含一个求和 $\sum_{j}$: 输出向量的第 1 个分量(记作第 1 行的结果): $$ (W_r x)_1 = 0.3 \cdot x_1 + (-0.5) \cdot x_2 = 0.3 \cdot 2 + (-0.5) \cdot 1 = 0.6 - 0.5 = 0.1. $$ 输出向量的第 2 个分量(第 2 行的结果): $$ (W_r x)_2 = 1.2 \cdot x_1 + 0.4 \cdot x_2 = 1.2 \cdot 2 + 0.4 \cdot 1 = 2.4 + 0.4 = 2.8. $$ 在使用矩阵乘法时,你可以写成 $$ y = W_r \, \sigma(x), $$ 其中 $\sigma$ 表示对 $x$ 的各分量先做激活,接着用 $W_r$ 乘上去。这就是把“$\sum_j \dots$”用矩阵乘法隐藏了。 $$ \begin{pmatrix} 0.3 & -0.5\\ 1.2 & \;\,0.4 \end{pmatrix} \begin{pmatrix} 2\\ 1 \end{pmatrix} = \begin{pmatrix} 0.3 \times 2 + (-0.5) \times 1\\[6pt] 1.2 \times 2 + 0.4 \times 1 \end{pmatrix} = \begin{pmatrix} 0.6 - 0.5\\ 2.4 + 0.4 \end{pmatrix} = \begin{pmatrix} 0.1\\ 2.8 \end{pmatrix}. $$ 奇异值 定义 对于一个 $m \times n$ 的矩阵 $A$,其奇异值是非负实数 $\sigma_1, \sigma_2, \ldots, \sigma_r$($r = \min(m, n)$),满足存在正交矩阵 $U$ 和 $V$,使得: $$ A = U \Sigma V^T $$ 其中,$\Sigma$ 是对角矩阵,对角线上的元素即为奇异值。 主要特点 非负性:奇异值总是非负的。 对角矩阵的奇异值是对角线元素的绝对值。 降序排列:通常按从大到小排列,即 $\sigma_1 \geq \sigma_2 \geq \ldots \geq \sigma_r \geq 0$。 矩阵分解:奇异值分解(SVD)将矩阵分解为三个矩阵的乘积,$U$ 和 $V$ 是正交矩阵,$\Sigma$ 是对角矩阵。 应用广泛:奇异值在数据降维、噪声过滤、图像压缩等领域有广泛应用。 奇异值求解 奇异值可以通过计算矩阵 $A^T A$ 或 $A A^T$ 的特征值的平方根得到。 步骤 1:计算 $A^T A$ 首先,我们计算矩阵 $A$ 的转置 $A^T$: $$ A^T = \begin{pmatrix} 3 & 0 \\ 0 & -4 \end{pmatrix} $$ 然后,计算 $A^T A$: $$ A^T A = \begin{pmatrix} 3 & 0 \\ 0 & -4 \end{pmatrix} \begin{pmatrix} 3 & 0 \\ 0 & -4 \end{pmatrix} = \begin{pmatrix} 9 & 0 \\ 0 & 16 \end{pmatrix} $$ 步骤 2:计算 $A^T A$ 的特征值 接下来,我们计算 $A^T A$ 的特征值。特征值 $\lambda$ 满足以下特征方程: $$ \det(A^T A - \lambda I) = 0 $$ 即: $$ \det \begin{pmatrix} 9 - \lambda & 0 \\ 0 & 16 - \lambda \end{pmatrix} = (9 - \lambda)(16 - \lambda) = 0 $$ 解这个方程,我们得到两个特征值: $$ \lambda_1 = 16, \quad \lambda_2 = 9 $$ 步骤 3:计算奇异值 奇异值是特征值的平方根,因此我们计算: $$ \sigma_1 = \sqrt{\lambda_1} = \sqrt{16} = 4 $$ $$ \sigma_2 = \sqrt{\lambda_2} = \sqrt{9} = 3 $$ 结果 矩阵 $A$ 的奇异值为 4 和 3。 奇异值分解 给定一个实矩阵 $A$(形状为 $m \times n$),SVD 是将它分解为: $$ A = U \Sigma V^T $$ 构造 $A^T A$ 计算对称矩阵 $A^T A$($n \times n$) 求解 $A^T A$ 的特征值和特征向量 设特征值为 $\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_n \geq 0$ 对应特征向量为 $\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_n$ 计算奇异值 $\sigma_i = \sqrt{\lambda_i}$ 构造矩阵 $V$ 将正交归一的特征向量作为列向量:$V = [\mathbf{v}_1 | \mathbf{v}_2 | \dots | \mathbf{v}_n]$ 求矩阵 $U$ 对每个非零奇异值:$\mathbf{u}_i = \frac{A \mathbf{v}_i}{\sigma_i}$ 标准化(保证向量长度为 1)后组成 $U = [\mathbf{u}_1 | \mathbf{u}_2 | \dots | \mathbf{u}_m]$ 构造 $\Sigma$ 对角线放置奇异值:$\Sigma = \text{diag}(\sigma_1, \sigma_2, \dots, \sigma_p)$,$p=\min(m,n)$ 范数 L2范数定义: 对于一个向量 $\mathbf{w} = [w_1, w_2, \dots, w_n]$,L2 范数定义为 $$ \|\mathbf{w}\|_2 = \sqrt{w_1^2 + w_2^2 + \dots + w_n^2} $$ 假设一个权重向量为 $\mathbf{w} = [3, -4]$,则 $$ \|\mathbf{w}\|_2 = \sqrt{3^2 + (-4)^2} = \sqrt{9+16} = \sqrt{25} = 5. $$ 用途: 正则化(L2正则化/权重衰减):在训练过程中,加入 L2 正则项有助于防止模型过拟合。正则化项通常是权重的 L2 范数的平方,例如 $$ \lambda \|\mathbf{w}\|_2^2 $$ 其中 $\lambda$ 是正则化系数。 梯度裁剪:在 RNN 等深度网络中,通过计算梯度的 L2 范数来判断是否需要对梯度进行裁剪,从而防止梯度爆炸。 具体例子: 假设我们有一个简单的线性回归模型,损失函数为均方误差(MSE): $$ L(\mathbf{w}) = \frac{1}{2N} \sum_{i=1}^N (y_i - \mathbf{w}^T \mathbf _i)^2 $$ 其中,$N$ 是样本数量,$y_i$ 是第 $i$ 个样本的真实值,$\mathbf _i$ 是第 $i$ 个样本的特征向量,$\mathbf{w}$ 是权重向量。 加入 L2 正则项后,新的损失函数为: $$ L_{\text{reg}}(\mathbf{w}) = \frac{1}{2N} \sum_{i=1}^N (y_i - \mathbf{w}^T \mathbf _i)^2 + \lambda \|\mathbf{w}\|_2^2 $$ 在训练过程中,优化算法会同时最小化原始损失函数和正则项,从而在拟合训练数据的同时,避免权重值过大。 梯度更新 在梯度下降算法中,权重 $\mathbf{w}$ 的更新公式为: $$ \mathbf{w} \leftarrow \mathbf{w} - \eta \nabla L_{\text{reg}}(\mathbf{w}) $$ 其中,$\eta$ 是学习率,$\nabla L_{\text{reg}}(\mathbf{w})$ 是损失函数关于 $\mathbf{w}$ 的梯度。 对于加入 L2 正则项的损失函数,梯度为: $$ \nabla L_{\text{reg}}(\mathbf{w}) = \nabla L(\mathbf{w}) + 2\lambda \mathbf{w} $$ 因此,权重更新公式变为: $$ \mathbf{w} \leftarrow \mathbf{w} - \eta (\nabla L(\mathbf{w}) + 2\lambda \mathbf{w}) $$ 通过加入 L2 正则项,模型在训练过程中不仅会最小化原始损失函数,还会尽量减小权重的大小,从而避免过拟合。正则化系数 $\lambda$ 控制着正则化项的强度,较大的 $\lambda$ 会导致权重更小,模型更简单,但可能会欠拟合;较小的 $\lambda$ 则可能无法有效防止过拟合。因此,选择合适的 $\lambda$ 是使用 L2 正则化的关键。 矩阵的元素级范数 L0范数(但它 并不是真正的范数): $$ \|A\|_0 = \text{Number of non-zero elements in } A = \sum_{i=1}^{m} \sum_{j=1}^{n} \mathbb{I}(a_{ij} \neq 0) $$ 其中: $\mathbb{I}(\cdot)$ 是指示函数(若 $a_{ij} \neq 0$ 则取 1,否则取 0)。 如果矩阵 $A$ 有 $k$ 个非零元素,则 $|A|_0 = k$。 衡量稀疏性: $|A|_0$ 越小,矩阵 $A$ 越稀疏(零元素越多)。 在压缩感知、低秩矩阵恢复、稀疏编码等问题中,常用 $L_0$ 范数来 约束解的稀疏性。 非凸、非连续、NP难优化: $L_0$ 范数是 离散的,导致优化问题通常是 NP难 的(无法高效求解)。 因此,实际应用中常用 $L_1$ 范数(绝对值之和)作为凸松弛替代: $$ |A|1 = \sum{i,j} |a_{ij}| $$ NP难问题: 可以在多项式时间内 验证一个解是否正确,但 不一定能在多项式时间内找到解。 L1范数:元素绝对值和 $$ \|A\|_1 = \sum_{i=1}^{m} \sum_{j=1}^{n} |a_{ij}| $$ 范数类型 定义 性质 优化难度 用途 $L_0$ $\sum_{i,j} \mathbb{I}(a_{ij} \neq 0)$ 非凸、离散、不连续 NP难 精确稀疏性控制 $L_1$ $\sum_{i,j} a_{ij} $ 凸、连续 矩阵的核范数 核范数,又称为迹范数(trace norm),是矩阵范数的一种,定义为矩阵所有奇异值之和。对于一个矩阵 $A$(假设其奇异值为 $\sigma_1, \sigma_2, \dots, \sigma_r$),其核范数定义为: $$ \|A\|_* = \sum_{i=1}^{r} \sigma_i, $$ 其中 $r$ 是矩阵 $A$ 的秩。 核范数的主要特点 凸性 核范数是一个凸函数,因此在优化问题中常用作替代矩阵秩的惩罚项(因为直接最小化矩阵秩是一个NP困难的问题)。 低秩逼近 在矩阵补全、低秩矩阵恢复等应用中,核范数被用来鼓励矩阵解具有低秩性质,因其是矩阵秩的凸松弛。 与SVD的关系 核范数直接依赖于矩阵的奇异值,计算时通常需要奇异值分解(SVD)。 Frobenius 范数 对于一个矩阵 $A \in \mathbb{R}^{m \times n}$,其 Frobenius 范数定义为 $$ \|A\|_F = \sqrt{\sum_{i=1}^{m}\sum_{j=1}^{n} a_{ij}^2} $$ 这个定义与向量 $L2$ 范数类似,只不过是对矩阵中所有元素取平方和后再开平方。 对于归一化的向量$\mathbf _m$ ,其外积矩阵 $\mathbf _m \mathbf _m^T$,其元素为 $(\mathbf _m \mathbf m^T){ij} = x_i x_j$,因此: $$ \|\mathbf _m \mathbf _m^T\|_F = \sqrt{\sum_{i=1}^n \sum_{j=1}^n |x_i x_j|^2 } = \sqrt{\left( \sum_{i=1}^n x_i^2 \right) \left( \sum_{j=1}^n x_j^2 \right) } = \|\mathbf _m\|_2 \cdot \|\mathbf _m\|_2 = 1. $$ 例: 设归一化向量 $\mathbf = \begin{bmatrix} \frac{1}{\sqrt{2}} \ \frac{1}{\sqrt{2}} \end{bmatrix}$,其外积矩阵为: $$ \mathbf \mathbf ^T = \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix} \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} = \begin{bmatrix} \frac{1}{2} & \frac{1}{2} \\ \frac{1}{2} & \frac{1}{2} \end{bmatrix} $$ 计算 Frobenius 范数: $$ \|\mathbf \mathbf ^T\|_F = \sqrt{ \left( \frac{1}{2} \right)^2 + \left( \frac{1}{2} \right)^2 + \left( \frac{1}{2} \right)^2 + \left( \frac{1}{2} \right)^2 } = \sqrt{4 \cdot \frac{1}{4}} = 1. $$ 如果矩阵 $A$ 的奇异值为 $\sigma_1, \sigma_2, \ldots, \sigma_n$,则: $$ \|A\|_F = \sqrt{\sum_{i=1}^n \sigma_i^2} $$ 这使得 Frobenius 范数在低秩近似和矩阵分解(如 SVD)中非常有用。 设矩阵 $A$ 为: $$ A = \begin{bmatrix} 1 & 0 \\ 0 & 2 \\ 1 & 1 \end{bmatrix} $$ 定义: $$ \|A\|_F = \sqrt{1^2 + 0^2 + 0^2 + 2^2 + 1^2 + 1^2 } = \sqrt{1 + 0 + 0 + 4 + 1 + 1} = \sqrt{7} $$ 验证: 计算 $A^T A$: $$ A^T A = \begin{bmatrix} 1 & 0 & 1 \ 0 & 2 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 \ 0 & 2 \ 1 & 1 \end{bmatrix} = \begin{bmatrix} 2 & 1 \ 1 & 5 \end{bmatrix} $$ 求 $A^T A$ 的特征值(即奇异值的平方): $$ \det(A^T A - \lambda I) = \lambda^2 - 7\lambda + 9 = 0 \implies \lambda = \frac{7 \pm \sqrt{13}}{2} $$ 因此: $$ \sigma_1 = \sqrt{\frac{7 + \sqrt{13}}{2}}, \quad \sigma_2 = \sqrt{\frac{7 - \sqrt{13}}{2}} $$ 验证 Frobenius范数: $$ \sigma_1^2 + \sigma_2^2 = \frac{7 + \sqrt{13}}{2} + \frac{7 - \sqrt{13}}{2} = 7 $$ 所以: $$ |A|_F = \sqrt{7} $$ 公式正确! 迹和 Frobenius 范数的关系: $$ \|A\|_F^2 = \text{tr}(A^* A) $$ 这表明 Frobenius 范数的平方就是 $A^* A$ 所有特征值之和。而 $A^* A$ 的特征值开方就是A的奇异值。 最大范数 矩阵的最大范数(也称为 元素级无穷范数 或 一致范数)定义为矩阵所有元素绝对值的最大值: $$ \|A\|_{\max} = \max_{i,j} |A_{ij}| $$ 它衡量的是矩阵中绝对值最大的元素,适用于逐元素(element-wise)分析。 如果比较两个矩阵 $A$ 和 $B$,它们的误差矩阵 $E = A - B$ 的最大范数为: $$ \|A - B\|_{\max} = \max_{i,j} |A_{ij} - B_{ij}| $$ 意义: 如果 $|A - B|_{\max} \leq \epsilon$,说明 $A$ 和 $B$ 的所有对应元素的误差都不超过 $\epsilon$。 对于任意 $m \times n$ 的矩阵 $A$,以下不等式成立: $$ \|A\|_{\max} \leq \|A\|_F \leq \sqrt{mn} \cdot \|A\|_{\max} $$ 矩阵的迹 迹的定义 对于一个 $n \times n$ 的矩阵 $B$,其迹(trace)定义为矩阵对角线元素之和: $$ \text{tr}(B) = \sum_{i=1}^n B_{ii} $$ 迹与特征值的关系 对于一个 $n \times n$ 的矩阵 $B$,其迹等于其特征值之和。即: $$ \text{tr}(B) = \sum_{i=1}^n \lambda_i $$ 其中 $\lambda_1, \lambda_2, \ldots, \lambda_n$ 是矩阵 $B$ 的特征值。 应用到 $A^ A$* 对于矩阵 $A^* A$(如果 $A$ 是实矩阵,则 $A^* = A^T$),它是一个半正定矩阵,其特征值是非负实数。 $A^* A$ 的迹还与矩阵 $A$ 的 Frobenius 范数有直接关系。具体来说: $$ \|A\|_F^2 = \text{tr}(A^* A) $$ 迹的基本性质 迹是一个线性运算,即对于任意标量 $c_1, c_2$ 和矩阵 $A, B$,有: $$ \text{tr}(c_1 A + c_2 B) = c_1 \text{tr}(A) + c_2 \text{tr}(B) $$ 对于任意矩阵 $A, B, C$,迹满足循环置换性质: $$ \text{tr}(ABC) = \text{tr}(CAB) = \text{tr}(BCA) $$ 注意:迹的循环置换性不意味着 $\text{tr}(ABC) = \text{tr}(BAC)$,除非矩阵 $A, B, C$ 满足某些特殊条件(如对称性)。 酉矩阵 酉矩阵是一种复矩阵,其满足下面的条件:对于一个 $n \times n$ 的复矩阵 $U$,如果有 $$ U^* U = U U^* = I, $$ 其中 $U^*$ 表示 $U$ 的共轭转置(先转置再取复共轭),而 $I$ 是 $n \times n$ 的单位矩阵,那么 $U$ 就被称为酉矩阵。简单来说,酉矩阵在复内积空间中保持内积不变,相当于在该空间中的“旋转”或“反射”。 如果矩阵的元素都是实数,那么 $U^*$ 就等于 $U^T$(转置),这时酉矩阵就退化为正交矩阵。 考虑二维旋转矩阵 $$ U = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix}. $$ 当 $\theta$ 为任意实数时,这个矩阵满足 $$ U^T U = I, $$ 所以它是一个正交矩阵,同时也属于酉矩阵的范畴。 例如,当 $\theta = \frac{\pi}{4}$(45°)时, $$ U = \begin{bmatrix} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{bmatrix}. $$ 正定\正半定矩阵 正定矩阵(PD) $$ A \text{ 正定} \iff \forall, x \in \mathbb{R}^n \setminus {0}, \quad x^T A x > 0. $$ 正半定矩阵(PSD) $$ A \text{ 正半定} \iff \forall, x \in \mathbb{R}^n, \quad x^T A x \ge 0. $$ PD:所有特征值都严格大于零。 $\lambda_i(A)>0,;i=1,\dots,n$。 PSD:所有特征值都非负。 $\lambda_i(A)\ge0,;i=1,\dots,n$。 拉普拉斯矩阵是正半定矩阵! 对于任意实矩阵 $A$(大小为 $m\times n$),矩阵 $B = A^T A\quad(\text{大小为 }n\times n).$是半正定矩阵 显然 $$ B^T = (A^T A)^T = A^T (A^T)^T = A^T A = B, $$ 所以 $B$ 是对称矩阵。 对任意向量 $x\in\mathbb R^n$,有 $$ x^T B,x = x^T (A^T A) x = (Ax)^T (Ax) = |Ax|^2 ;\ge;0. $$ 因此 $B$ 总是 正半定(PSD) 的。 对称非负矩阵分解 $$ A≈HH^T $$ 1. 问题回顾 给定一个对称非负矩阵 $A\in\mathbb{R}^{n\times n}$,我们希望找到一个非负矩阵 $H\in\mathbb{R}^{n\times k}$ 使得 $$ A \approx HH^T. $$ 为此,我们可以**最小化目标函数(损失函数)** $$ f(H)=\frac{1}{2}\|A-HH^T\|_F^2, $$ 其中 $\|\cdot\|_F$ 表示 Frobenius 范数,定义为矩阵所有元素的平方和的平方根。 $| A - H H^T |_F^2$ 表示矩阵 $A - H H^T$ 的所有元素的平方和。 2. 梯度下降方法 2.1 计算梯度 目标函数(损失函数)是 $$ f(H)=\frac{1}{2}\|A-HH^T\|_F^2. $$ $$ \|M\|_F^2 = \operatorname{trace}(M^T M), $$ 因此,目标函数可以写成: $$ f(H)=\frac{1}{2}\operatorname{trace}\Bigl[\bigl(A-HH^T\bigr)^T\bigl(A-HH^T\bigr)\Bigr]. $$ 注意到 $A$ 和$HH^T$ 都是对称矩阵,可以简化为: $$ f(H)=\frac{1}{2}\operatorname{trace}\Bigl[\bigl(A-HH^T\bigr)^2\Bigr]. $$ 展开后得到 $$ f(H)=\frac{1}{2}\operatorname{trace}\Bigl[A^2 - 2AHH^T + (HH^T)^2\Bigr]. $$ 其中 $\operatorname{trace}(A^2)$ 与 $H$ 无关,可以看作常数,不影响梯度计算。 计算 $\nabla_H \operatorname{trace}(-2 A H H^T)$ $$ \nabla_H \operatorname{trace}(-2 A H H^T) = -4 A H $$ 计算 $\nabla_H \operatorname{trace}((H H^T)^2)$ $$ \nabla_H \operatorname{trace}((H H^T)^2) = 4 H H^T H $$ 将两部分梯度合并: $$ \nabla_H f(H) = \frac{1}{2}(4 H H^T H - 4 A H )= 2(H H^T H - A H) $$ 2.2 梯度下降更新 设学习率为 $\eta>0$,则梯度下降的基本更新公式为: $$ H \leftarrow H - \eta\, \nabla_H f(H) = H - 2\eta\Bigl(HH^T H - A H\Bigr). $$ 由于我们要求 $H$ 中的元素保持非负,所以每次更新之后通常需要进行投影: $$ H_{ij} \leftarrow \max\{0,\,H_{ij}\}. $$ 这种方法称为投影梯度下降,保证每一步更新后 $H$ 满足非负约束。 3. 举例说明 设对称非负矩阵: $$ A = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix}, \quad k=1, \quad H \in \mathbb{R}^{2 \times 1} $$ 初始化 $H^{(0)} = \begin{bmatrix} 1 \\ 1 \end{bmatrix}$,学习率 $\eta = 0.01$。 迭代步骤: 初始 ( H^{(0)} ): $$ H^{(0)} = \begin{bmatrix} 1 \\ 1 \end{bmatrix}, \quad H^{(0)}(H^{(0)})^T = \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}. $$ 目标函数值: $$ f(H^{(0)}) = \frac{1}{2} \left( (2-1)^2 + 2(1-1)^2 + (2-1)^2 \right) = 1. $$ 计算梯度: $$ HH^T H = \begin{bmatrix} 2 \\ 2 \end{bmatrix}, \quad AH = \begin{bmatrix} 3 \\ 3 \end{bmatrix}, $$ $$ \nabla_H f(H^{(0)}) = 2 \left( \begin{bmatrix} 2 \\ 2 \end{bmatrix} - \begin{bmatrix} 3 \\ 3 \end{bmatrix} \right) = \begin{bmatrix} -2 \\ -2 \end{bmatrix}. $$ 更新 ( H ): $$ H^{(1)} = H^{(0)} - 2 \cdot 0.01 \cdot \begin{bmatrix} -2 \\ -2 \end{bmatrix} = \begin{bmatrix} 1.04 \\ 1.04 \end{bmatrix}. $$ 更新后目标函数: $$ H^{(1)}(H^{(1)})^T = \begin{bmatrix} 1.0816 & 1.0816 \\ 1.0816 & 1.0816 \end{bmatrix}, $$ $$ f(H^{(1)}) = \frac{1}{2} \left( (2-1.0816)^2 + 2(1-1.0816)^2 + (2-1.0816)^2 \right) \approx 0.8464. $$ 一次迭代后目标函数值从 $1.0$ 下降至 $0.8464$
科研
zy123
1年前
0
20
0
2025-03-22
同步本地Markdown至Typecho站点
同步本地Markdown至Typecho站点 本项目基于https://github.com/Sundae97/typecho-markdown-file-publisher 实现效果: 将markdown发布到typecho 发布前将markdown中的公式块和代码块进行格式化,确保能适配md解析器。 发布前将markdown的图片资源上传到自己搭建的图床Easyimage中(自行替换成阿里云OSS等), 并替换markdown中的图片链接。 将md所在的文件夹名称作为post的category(mysql发布可以插入category, xmlrpc接口暂时不支持category操作)。 以title和category作为文章的唯一标识,如果数据库中已有该数据,将会更新现有文章,否则新增文章。 环境:Typecho1.2.1 php8.1.0 项目目录 typecho_markdown_upload/main.py是上传md文件到站点的核心脚本 transfer_md/transfer.py是对md文件进行预处理的脚本。 核心思路 一、预先准备 图床服务器 本人自己在服务器上搭建了私人图床——easyimage,该服务能够实现图片上传并返回公网 URL,这对于在博客中正常显示 Markdown 文件中的图片至关重要。 当然,也可以选择使用公共图床服务,如阿里云 OSS,但这里不做详细介绍。 需手动修改transfer_md/upload_img.py,配置url、token等信息。 参考博客:【好玩儿的Docker项目】10分钟搭建一个简单图床——Easyimage-我不是咕咕鸽 github地址:icret/EasyImages2.0: 简单图床 - 一款功能强大无数据库的图床 2.0版 picgo安装: 使用 Typora + PicGo + Easyimage 组合,可以实现将本地图片直接粘贴到 Markdown 文件中,并自动上传至图床。 下载地址:Releases · Molunerfinn/PicGo 操作步骤如下: 打开 PicGo,点击右下角的小窗口。 进入插件设置,搜索并安装 web-uploader 1.1.1 插件(注意:旧版本可能无法搜索到,建议直接安装最新版本)。 配置插件:在设置中填写 API 地址,该地址可在 Easyimage 的“设置-API设置”中获取。 配置完成后,即可实现图片自动上传,提升 Markdown 编辑体验。 Typora 设置 为了确保在博客中图片能正常显示,编辑 Markdown 文档时必须将图片上传至图床,而不是保存在本地。请按以下步骤进行配置: 在 Typora 中,打开 文件 → 偏好设置 → 图像 选项。 在 “插入图片时” 选项中,选择 上传图片。 在 “上传服务设定” 中选择 PicGo,并指定 PicGo 的安装路径。 文件结构统一: md_files ├── category1 │ ├── file1.md │ └── file2.md ├── category2 │ ├── file3.md │ └── file4.md └── output ├── assets_type ├── pics └── updated_files 注意:category对应上传到typecho中的文章所属的分类。 如果你现有的图片分散在系统中,可以使用 transfer_md/transfer.py 脚本来统一处理。该脚本需要传入三个参数: input_path: 指定包含 Markdown 文件的根目录(例如上例中的 md_files)。 output_path: 输出文件夹(例如上例中的 output)。 type_value: 1:扫描 input_path 下所有 Markdown 文件,将其中引用的本地图片复制到 output_path 中,同时更新 Markdown 文件中的图片 URL 为 output_path 内的路径; 2:为每个 Markdown 文件建立单独的文件夹(以文件名命名),图片存放在文件夹下的 assets 子目录中,整体存入assets_type文件夹中,; 3:扫描 Markdown 文件中的本地图片,将其上传到图床(获取公网 URL),并将 Markdown 文件中对应的图片 URL 替换为公网地址。 4:预处理Markdown 文件,将公式块和代码块格式化,以便于Markdown解析器解析(本地typora编辑器对于md格式比较宽容,但博客中使用的md解析器插件不一定能正确渲染!) 二、使用Git进行版本控制 假设你在服务器上已经搭建了 Gitea (Github、Gitee都行)并创建了一个名为 md_files 的仓库,那么你可以在 md_files 文件夹下通过 Git Bash 执行以下步骤将本地文件提交到远程仓库: 初始化本地仓库: git init 添加远程仓库: 将远程仓库地址添加为 origin(请将 http://xxx 替换为你的实际仓库地址): git remote add origin http://xxx 添加文件并提交: 注意,写一个.gitignore文件将output排除版本控制 git add . git commit -m "Initial commit" 推送到远程仓库: git push -u origin master 后续更新(可写个.bat批量执行): git add . git commit -m "更新了xxx内容" git push 三、在服务器上部署该脚本 1. 确保脚本能够连接到 Typecho 使用的数据库 本博客使用 docker-compose 部署 Typecho(参考:【好玩儿的Docker项目】10分钟搭建一个Typecho博客|太破口!念念不忘,必有回响!-我不是咕咕鸽)。为了让脚本能访问 Typecho 的数据库,我将 Python 应用pyapp也通过 docker-compose 部署,这样所有服务均在同一网络中,互相之间可以直接通信。 参考docker-compose.yml如下: services: nginx: image: nginx ports: - "4000:80" # 左边可以改成任意没使用的端口 restart: always environment: - TZ=Asia/Shanghai volumes: - ./typecho:/var/www/html - ./nginx:/etc/nginx/conf.d - ./logs:/var/log/nginx depends_on: - php networks: - web php: build: php restart: always expose: - "9000" # 不暴露公网,故没有写9000:9000 volumes: - ./typecho:/var/www/html environment: - TZ=Asia/Shanghai depends_on: - mysql networks: - web pyapp: build: ./markdown_operation # Dockerfile所在的目录 restart: "no" volumes: - /home/zy123/md_files:/markdown_operation/md_files networks: - web env_file: - .env depends_on: - mysql mysql: image: mysql:5.7 restart: always environment: - TZ=Asia/Shanghai expose: - "3306" # 不暴露公网,故没有写3306:3306 volumes: - ./mysql/data:/var/lib/mysql - ./mysql/logs:/var/log/mysql - ./mysql/conf:/etc/mysql/conf.d env_file: - mysql.env networks: - web networks: web: 注意:如果你不是用docker部署的typecho,只要保证脚本能连上typecho所使用的数据库并操纵里面的表就行! 2. 将 md_files 挂载到容器中,保持最新内容同步 这样有几个优势: 不需要每次构建镜像或进入容器手动拉取; 本地更新 md_files 后,容器内自动同步,无需额外操作; 保持了宿主机上的 Git 版本控制和容器内的数据一致性。 3.仅针对 pyapp 服务进行重构和启动,不影响其他服务的运行: pyapp是本Python应用在容器内的名称。 1.构建镜像: docker-compose build pyapp 2.启动容器并进入 Bash: docker-compose run --rm -it pyapp /bin/bash 3.在容器内运行脚本: python typecho_markdown_upload/main.py 2、3两步可合并为: docker-compose run --rm pyapp python typecho_markdown_upload/main.py 此时可以打开博客验证一下是否成功发布文章了! 如果失败,可以验证mysql数据库: 1️⃣ 进入 MySQL 容器: docker-compose exec mysql mysql -uroot -p # 输入你的 root 密码 2️⃣ 切换到 Typecho 数据库并列出表: USE typecho; SHOW TABLES; 3️⃣ 查看 typecho_contents 表结构(文章表): DESCRIBE typecho_contents; mysql> DESCRIBE typecho_contents; +--------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+------------------+------+-----+---------+----------------+ | cid | int(10) unsigned | NO | PRI | NULL | auto_increment | | title | varchar(150) | YES | | NULL | | | slug | varchar(150) | YES | UNI | NULL | | | created | int(10) unsigned | YES | MUL | 0 | | | modified | int(10) unsigned | YES | | 0 | | | text | longtext | YES | | NULL | | | order | int(10) unsigned | YES | | 0 | | | authorId | int(10) unsigned | YES | | 0 | | | template | varchar(32) | YES | | NULL | | | type | varchar(16) | YES | | post | | | status | varchar(16) | YES | | publish | | | password | varchar(32) | YES | | NULL | | | commentsNum | int(10) unsigned | YES | | 0 | | | allowComment | char(1) | YES | | 0 | | | allowPing | char(1) | YES | | 0 | | | allowFeed | char(1) | YES | | 0 | | | parent | int(10) unsigned | YES | | 0 | | | views | int(11) | YES | | 0 | | | agree | int(11) | YES | | 0 | | +--------------+------------------+------+-----+---------+----------------+ 4️⃣ 查询当前文章数量(确认执行前后有无变化): SELECT COUNT(*) AS cnt FROM typecho_contents; 自动化 1.windows下写脚本自动/手动提交每日更新 2.在 Linux 服务器上配置一个定时任务,定时执行 git pull 命令和启动脚本更新博客的命令。 创建脚本/home/zy123/typecho/deploy.sh #!/bin/bash cd /home/zy123/md_files || exit git pull cd /home/zy123/typecho || exit docker compose run --rm pyapp python typecho_markdown_upload/main.py 赋予可执行权限chmod +x /home/zy123/deploy.sh 编辑 Crontab 安排任务(每天0点10分执行) 打开 crontab 编辑器:$crontab -e$ 10 0 * * * /home/zy123/typecho/deploy.sh >> /home/zy123/typecho/deploy.log 2>&1 3.注意md_files文件夹所属者和deploy.sh的所属者需要保持一致。否则会报: fatal: detected dubious ownership in repository at '/home/zy123/md_files' To add an exception for this directory, call: git config --global --add safe.directory /home/zy123/md_files TODO typecho_contents表中的slug字段代表链接中的日志缩略名,如wordpress风格 /archives/{slug}.html,目前是默认int自增,有需要的话可以在插入文章时手动设置该字段。
项目
zy123
1年前
0
146
0
上一页
1
...
5
6
7
...
12
下一页