首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
40 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
8
篇与
论文
相关的结果
2025-09-20
deepwalk
DeepWalk DeepWalk 的最终目标是—— 把图中的每个节点,用一个低维向量表示(embedding)出来,使得结构相似的节点在向量空间中也接近。 也就是说,如果两个节点在图上经常“一起出现”(相连、同社群等),那它们的 embedding 也应该相似。 主要思想 将图结构转化为“序列语料”: 在图上做 随机游走(random walks),生成顶点序列,类似于自然语言中的“句子”。 将随机游走得到的序列输入 Skip-Gram 模型,学习节点的低维嵌入表示。 学到的嵌入能捕捉到 邻居相似性、社区结构,可用于分类、聚类、链路预测等任务。 输入 & 输出 输入:图结构 $G=(V,E)$,随机游走参数(步长 $t$,次数 $\gamma$,窗口大小 $w$),嵌入维度 $d$。 输出:节点嵌入矩阵 $\Phi \in \mathbb{R}^{|V|\times d}$。 关键公式与目标 随机游走生成“句子”: 从某个顶点 $v_i$ 出发,采样一个长度为 $t$ 的随机游走序列: $$ W_{v_i} = (v_i, v_{i+1}, \dots, v_{i+t}) $$ 生成的序列 $W_{v_i}$ 就是一句“话”,用来训练 Skip-Gram 模型。在这些序列中,如果两个节点经常在相邻位置出现,就表示它们关系密切。 ["A", "B", "C", "D"] Skip-Gram 目标函数: 现在我们用 Word2Vec 的思想:对于一句话 ["A", "B", "C", "D"],假设窗口大小 $w = 1$,也就是每个节点只看它的邻居。那么训练样本是这样的: 中心节点 它要预测的邻居 A B B A, C C B, D D C 模型要学的是: “给我节点 B,我要能预测出 A 和 C。” “给我节点 C,我要能预测出 B 和 D。” 于是就有这个公式,给定中心节点 $v_i$,最大化其上下文窗口内邻居节点的条件概率: $$ \max_{\Phi} \sum_{i=1}^{|V|} \sum_{u \in \mathcal{N}_w(v_i)} \log Pr(u \mid \Phi(v_i)) $$ 其中 $\mathcal{N}_w(v_i)$ 表示在随机游走序列中,窗口大小 $w$ 内的上下文节点。 我希望模型能学到这样一种 embedding:中心节点 $v_i$ 能够高概率预测出它周围的邻居 $u$。 优化形式(负对数似然): 就是把上面的最大化目标,改写成一个最小化损失函数。 最大化“好事”(邻居出现的概率)= 最小化“坏事”(邻居预测错误的概率) $$ \min_{\Phi} - \log Pr\big( {v_{i-w},\dots,v_{i+w}} \mid \Phi(v_i) \big) $$ 概率建模(Hierarchical Softmax 或 Negative Sampling): $$ Pr(u \mid \Phi(v_i)) = \frac{\exp\big( \Phi(u) \cdot \Phi(v_i) \big)}{\sum_{v \in V} \exp\big( \Phi(v) \cdot \Phi(v_i) \big)} $$ 这相当于用 Softmax 把所有节点的相似度转成概率分布。 其中: 分子:中心节点和邻居节点的相似度(点积越大越相似); 分母:所有节点的相似度和(用来归一化成概率)。 如果 $u$ 是 $v_i$ 的邻居,那么 $\Phi(u)$ 与 $\Phi(v_i)$ 的点积就应更大。 例子 想象你是个“社交分析师”: 你观察到小明每天都和小红、小刚一起出现; 而小明几乎从不和小李在一起; 那你自然会说:小明和小红、小刚的关系更近。 DeepWalk 就是通过“随机游走 + 预测邻居”这个机制, 自动学出“谁跟谁关系近”的数值表示。 训练逻辑 1)加载 10+1 张图 A_list = [A100, A101, ..., A110] 我们取前 10 张作为输入,最后一张作为真实标签。 2)对每一个时间步的图做 DeepWalk for t in range(100, 110): emb_t = DeepWalk(A_t) 每张图 $A_t$ 都独立训练一个 节点 embedding(比如 400×64)。 400是节点数,64是嵌入维数 embedding 就是每个节点在这一时刻的“语义坐标”。 训练目标是:让在图里常相邻的节点在 embedding 空间也靠得近。 可以理解成: DeepWalk 把图结构变成“节点的向量表示”。 3)拼接成时间序列特征(10步) 对每对节点 (i, j),你把过去10个时间步的 embedding 拿出来,计算每步的 Hadamard积(元素乘): feats = [emb100[i]*emb100[j], emb101[i]*emb101[j], ..., emb109[i]*emb109[j]] X_ij = concatenate(feats) 每个节点对 (i, j) → 一个 10×64 = 640 维的特征; 这 640 维包含了它俩“过去10步的相似度变化轨迹”。 白话理解: 这个特征就像是“节点对关系的时间切片”。 如果两人(节点)经常靠得近 → 向量相似; 如果逐渐靠近 → 特征会呈现变化趋势。 4)第11步图作为真实答案(标签) A_target = A110 y_ij = 1 if 节点i和j在第110步相连 else 0 每个节点对 (i, j) 的标签就是第11步的真相; 如果在第11步有边 → 正样本; 没边 → 负样本。 5)平衡样本(1:1) 因为稀疏图中没连边的太多: 原来是 9,237 个正样本 vs 70,563 个负样本; 现在我们随机保留同样数量的负样本; 所以训练时正负样本平衡:9,237 : 9,237。 这样模型不会再“全猜没边”。 6)训练 MLP 来做预测 MLP(X) → 输出每个节点对在第110步连边的概率 输入:每个节点对的 640 维特征; 输出:一个 [0,1] 概率; Loss:二分类交叉熵(BCELoss); 优化器:Adam。 白话解释: MLP 在学“什么样的历史关系轨迹会导致下一步产生连接”。 7)用真实 A110 对照预测结果 模型预测完后: 它给每对节点一个连边概率; 我们用阈值 0.5 分成「有边/无边」; 然后与真实的 $A_{110}$ 比较,得到: 指标 含义 AUC=0.8279 模型能区分哪些节点会连边、哪些不会(非常好) ACC=0.7223 有约 72% 的节点对被正确分类(相对平衡后的准确率) (1)静态图版本 你只有一张图,比如社交网络的当前关系: DeepWalk 学出 embedding; 然后用 MLP 或逻辑回归,预测那些“目前没边但 embedding 很接近”的节点对; 这些就是「潜在朋友」→ 即未来可能建立连接的边。 📘 所以静态链路预测其实是: 用当前结构的 embedding 相似度,预测将来是否可能连边。 (2)动态图版本 你有多帧图,比如第100~109步(连续的10个时间片): 每一步都用 DeepWalk 得到 embedding; 然后把每个节点对的“10帧特征”拼起来; 喂给 MLP 预测第110步是否连边。 📘 动态版本其实是: 把「节点关系的历史轨迹」作为输入, 预测下一个时间步的关系变化。 DeepWalk 的本质: 是一个 图嵌入算法(Graph Embedding Method), 输入图结构,输出节点的向量表示(embedding)。 也就是说: 每次运行 DeepWalk,相当于重新学习节点的 embedding; embedding 本身就是最终结果,不需要“恢复模型状态”去推理; 它不具备像神经网络那样“泛化到新数据”的功能。 所以: ✅ DeepWalk 的输出 = checkpoint ✅ DeepWalk 的 embedding = 可直接保存 / 复用的结果 ❌ 不需要保存训练中间的模型权重
论文
zy123
1年前
0
6
0
2025-08-29
草稿
这是完全匹配你**第一个代码片段(向量化、时间驱动版本)**的文字描述。 这个模型在学术上通常被称为 Time-Discrete Random Walk 或 Memoryless Random Walk(无记忆随机游走),因为它没有“目标点”的概念,每一步都是独立的。 RW(Random Walk,随机游走 - 向量化/时间驱动版) 空间与时间: 正方形区域 $[0, L] \times [0, L]$(其中 $L$ 为 map_size),时间被离散化为固定的 $T$ 个步长(Steps)。 节点运动规则: 初始位置: 在区域内部均匀随机生成所有节点的起始坐标 $(x, y) \sim U(0, L)$。 瞬时移动(核心差异): 模型不设定任何固定的“目标点”或“行程”。 在每一个时间步 $t$,每个节点都会独立地重新随机选择一个运动方向 $\theta_t \sim U(0, 2\pi)$ 和一个瞬时速度 $v_t \sim U(v_{\min}, v_{\max})$。 位置更新: 根据当前步选定的速度矢量进行位移: $$x_t = x_{t-1} + v_t \cos(\theta_t)$$ $$y_t = y_{t-1} + v_t \sin(\theta_t)$$ 边界处理(物理反射): 代码实现了完全弹性碰撞(Reflection)。当节点试图跨越边界时,就像台球撞击桌边一样,其坐标会被镜像反弹回区域内(例如:若 $x < 0$,则重置为 $-x$;若 $x > L$,则重置为 $2L - x$),从而保证节点始终被限制在区域内部。 邻接生成: 设定通信半径 comm_radius,计算节点间的欧几里得距离。若距离 $\le$ 阈值则判定为连通,逐步构造邻接矩阵序列。 要点: 无记忆性(Memoryless): 这一时刻的运动方向与上一时刻完全无关(马尔科夫性 $\alpha=0$ 的极端情况)。 布朗运动特征: 节点的轨迹呈现高度的锯齿状(Zig-zag),缺乏长距离的直线运动。 扩散特性: 相比于有目标点的模型(如 RWP, RD),这种纯随机游走的节点扩散速度较慢,倾向于在局部区域内徘徊较长时间。
论文
zy123
1年前
0
11
0
2025-06-17
强化学习
强化学习 Q-learning 核心更新公式 $$ \boxed{Q(s,a) \gets Q(s,a) + \alpha\left[r + \gamma\,\max_{a'}Q(s',a') - Q(s,a)\right]} $$ - $s$:当前状态 - $a$:当前动作 - $r$:执行 $a$ 后获得的即时奖励 - $s'$:执行后到达的新状态 - $\alpha\in(0,1]$:学习率,决定“这次新信息”对旧值的影响力度 - $\gamma\in[0,1)$:折扣因子,衡量对“后续奖励”的重视程度 - $\max_{a'}Q(s',a')$:新状态下可选动作的最大估值,表示“后续能拿到的最大预期回报” 一般示例 环境设定 状态集合:${S_1, S_2}$ 动作集合:${a_1, a_2}$ 转移与奖励: 在 $S_1$ 选 $a_1$ → 获得 $r=5$,转到 $S_2$ 在 $S_1$ 选 $a_2$ → 获得 $r=0$,转到 $S_2$ 在 $S_2$ 选 $a_1$ → 获得 $r=0$,转到 $S_1$ 在 $S_2$ 选 $a_2$ → 获得 $r=1$,转到 $S_1$ 超参数:$\alpha=0.5$,$\gamma=0.9$ 初始化:所有 $Q(s,a)=0$ 在 Q-Learning 里,智能体并不是“纯随机”地走,也不是“一开始就全凭 Q 表拿最高值”——而是常用一种叫 $\epsilon$-greedy 的策略来平衡: 探索(Exploration):以概率 $\epsilon$(比如 10%)随机选一个动作,帮助智能体发现还没试过、可能更优的路径; 利用(Exploitation):以概率 $1-\epsilon$(比如 90%)选当前状态下 Q 值最高的动作,利用已有经验最大化回报。 下面按序进行 3 步“试—错”更新,并在表格中展示每一步后的 $Q$ 值。 步骤 状态 $s$ 动作 $a$ 奖励 $r$ 到达 $s'$ $\max_{a'}Q(s',a')$ 更新后 $Q(s,a)$ 当前 Q 表 初始 — — — — — — $Q(S_1,a_1)=0,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=0$ 1 $S_1$ $a_1$ 5 $S_2$ 0 $0+0.5,(5+0-0)=2.5$ $Q(S_1,a_1)=2.5,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=0$ 2 $S_2$ $a_2$ 1 $S_1$ $到达S_1状态后选择最优动作:$$\max{2.5,0}=2.5$ $0+0.5,(1+0.9\cdot2.5-0)=1.625$ $Q(S_1,a_1)=2.5,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=1.625$ 3 $S_1$ $a_1$ 5 $S_2$ $\max{0,1.625}=1.625$ $2.5+0.5,(5+0.9\cdot1.625-2.5)\approx4.481$ $Q(S_1,a_1)\approx4.481,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=1.625$ 第1步:从 $S_1$ 选 $a_1$,立即回报5,更新后 $Q(S_1,a_1)=2.5$。 第2步:从 $S_2$ 选 $a_2$,回报1,加上对 $S_1$ 后续最优值的 $0.9$ 折扣,得到 $1+0.9\times2.5=3.25$,更新后 $Q(S_2,a_2)=1.625$。 第3步:再一次在 $S_1$ 选 $a_1$,这次考虑了 $S_2$ 的最新估值,最终把 $Q(S_1,a_1)$ 提升到约 4.481。 通过这样一步步的“试—错 + 贝尔曼更新”,Q-Learning 能不断逼近最优 $Q^*(s,a)$,从而让智能体在每个状态都学会选出长期回报最高的动作。 训练结束后,表里每个状态 $s$ 下各动作的 Q 值都相对准确了,我们就可以直接读表来决策: $$ \pi(s) = \arg\max_a Q(s,a) $$ 即“在状态 $s$ 时,选 Q 值最高的动作”。 状态 \ 动作 $a_1$ $a_2$ $S_1$ 4.481 0 $S_2$ 0 1.625 DQN 核心思想:用深度神经网络近似 Q 函数来取代表格,在高维输入上直接做 Q-learning,并通过 经验回放(写进缓冲区 + 随机抽样训练”) + 目标网络(Target Network) 两个稳定化技巧,使 时序差分(TD )学习在非线性函数逼近下仍能收敛。 TD 学习 = 用“即时奖励 + 折扣后的未来估值”作为目标,通过 TD 误差持续修正当前估计。 训练过程 1. 初始化 主网络(Online Network) 定义一个 Q 网络 $Q(s,a;\theta)$,随机初始化参数 $\theta$。 目标网络(Target Network) 复制主网络参数,令 $\theta^- \leftarrow \theta$。 目标网络用于计算贝尔曼目标值,短期内保持不变。 经验回放缓冲区(Replay Buffer) 创建一个固定容量的队列 $\mathcal{D}$,用于存储交互样本 $(s,a,r,s')$。 超参数设置 学习率 $\eta$ 折扣因子 $\gamma$ ε-greedy 探索率 $\epsilon$(初始值) 最小训练样本数阈值 $N_{\min}$ 每次训练的小批量大小 $B$ 目标网络同步频率 $C$(梯度更新次数间隔) 2. 与环境交互并存储经验 在每个时间步 $t$: 动作选择 $$ a_t = \begin{cases} \text{随机动作} & \text{以概率 }\epsilon,\ \arg\max_a Q(s_t,a;\theta) & \text{以概率 }1-\epsilon. \end{cases} $$ 环境反馈 执行动作 $a_t$,得到奖励 $r_t$ 和下一个状态 $s_{t+1}$。 (需预先定义奖励函数) 存入缓冲区 将元组 $(s_t, a_t, r_t, s_{t+1})$ 存入 Replay Buffer $\mathcal{D}$。 如果 $\mathcal{D}$ 已满,则丢弃最早的样本。 3. 批量随机采样并训练 当缓冲区样本数 $\ge N_{\min}$ 时,每隔一次或多次环境交互,就进行一次训练更新: 随机抽取小批量 从 $\mathcal{D}$ 中随机采样 $B$ 条过往经验: $$ {(s_i, a_i, r_i, s'i)}{i=1}^B $$ 计算贝尔曼目标 对每条样本,用目标网络 $\theta^-$ 计算: $$ y_i = r_i + \gamma \max_{a'}Q(s'_i, a'; \theta^-) $$ 算的是:当前获得的即时奖励 $r_i$,加上“到了下一个状态后,做最优动作所能拿到的最大预期回报” 预测当前 Q 值 将当前状态-动作对丢给主网络 $\theta$,得到预测值: $$ \hat Q_i = Q(s_i, a_i;\theta) $$ 算的是:在当前状态 $s_i$、选了样本里那个动作 $a_i$ 时,网络现在估计的价值 构造损失函数 均方误差(MSE)损失: $$ L(\theta) = \frac{1}{B}\sum_{i=1}^B\bigl(y_i - \hat Q_i\bigr)^2 $$ 梯度下降更新主网络 $$ \theta \gets \theta - \eta \nabla_\theta L(\theta) $$ 4. 同步/软更新目标网络 硬同步(Fixed Target): 每做 $C$ 次梯度更新,就执行 $$ \theta^- \gets \theta $$ (可选)软更新: 用小步长 $\tau\ll1$ 平滑跟踪: $$ \theta^- \gets \tau \theta + (1-\tau) \theta^-. $$ 5. 重复训练直至收敛 重复步骤 2-4 直至满足终止条件(如最大回合数或性能指标)。 训练过程中可逐步衰减 $\epsilon$(ε-greedy),从更多探索过渡到更多利用。 示例 假设设定 动作空间:两个动作 ${a_1,a_2}$。 状态向量维度:2 维,记作 $s=(s_1,s_2)$。 目标网络结构(极简线性网络): $$ Q(s;\theta^-) = W^-s + b^-, $$ $W^-$ 是 $2\times2$ 的权重矩阵 (行数为动作数,列数为状态向量维数) $b^-$ 是长度 2 的偏置向量 网络参数(假定已初始化并被冻结): $$ W^- = \begin{pmatrix} 0.5 & -0.2\ 0.1 & ;0.3 \end{pmatrix},\quad b^- = \begin{pmatrix}0.1\-0.1\end{pmatrix}. $$ 折扣因子 $\gamma=0.9$。 样本数据 假设我们抽到的一条经验是 $$ (s_i,a_i,r_i,s'_i) = \bigl((0.0,\;1.0),\;a_1,\;2,\;(1.5,\,-0.5)\bigr). $$ 当前状态 $s_i=(0.0,1.0)$,当时选了动作 $a_1$ 并得到奖励 $r_i=2$。 到达新状态 $s'_i=(1.5,-0.5)$。 计算过程 前向计算目标网络输出 $$ Q(s'_i;\theta^-) = W^-,s'_i + b^- \begin{pmatrix} 0.5 & -0.2\ 0.1 & ;0.3 \end{pmatrix} \begin{pmatrix}1.5\-0.5\end{pmatrix} + \begin{pmatrix}0.1\-0.1\end{pmatrix} \begin{pmatrix} 0.5\cdot1.5 + (-0.2)\cdot(-0.5) + 0.1 \[4pt] 0.1\cdot1.5 + ;0.3\cdot(-0.5) - 0.1 \end{pmatrix} \begin{pmatrix} 0.75 + 0.10 + 0.1 \[3pt] 0.15 - 0.15 - 0.1 \end{pmatrix} \begin{pmatrix} 0.95 \[3pt] -0.10 \end{pmatrix}. $$ 因此, $$ Q(s'_i,a_1;\theta^-)=0.95,\quad Q(s'_i,a_2;\theta^-)= -0.10. $$ 取最大值 $$ \max_{a'}Q(s'_i,a';\theta^-) = \max{0.95,,-0.10} = 0.95. $$ 计算目标 $y_i$ $$ y_i = r_i + \gamma \times 0.95 = 2 + 0.9 \times 0.95 = 2 + 0.855 = 2.855. $$ 这样,我们就得到了 DQN 中训练主网络时的"伪标签" $y_i=2.855$,后续会用它与主网络预测值 $Q(s_i,a_i;\theta)$ 计算均方误差,进而更新 $\theta$。 改进DQN: 一、构造 n-step Transition 维护一个长度为 n 的滑动队列 每步交互(状态 → 动作 → 奖励 → 新状态)后,都向队列里添加这条"单步经验"。 当队列中积累到 n 条经验时,就可以合并成一条"n-step transition"了。 合并过程(一步一步累加) 起始状态:取队列里第 1 条记录中的状态 $s_t$ 起始动作:取第 1 条记录中的动作 $a_t$ 累积奖励:把队列中前 n 条经验的即时奖励按折扣因子 $\gamma$ 一步步加权累加: $$ G_t^{(n)} = r_t + \gamma,r_{t+1} + \gamma^2,r_{t+2} + \cdots + \gamma^{n-1}r_{t+n-1} $$ 形成一条新样本 最终你得到一条合并后的样本: $$ \bigl(s_t,;a_t,;G_t^{(n)},;s_{t+n},;\text{done}_{t+n}\bigr) $$ 然后把它存入主 Replay Buffer。 接着,把滑动队列的最早一条经验丢掉,让它向前滑一格,继续接收下一步新经验。 二、批量随机采样与训练 随机抽取 n-step 样本 训练时,不管它是来自哪一段轨迹,都从 Replay Buffer 里随机挑出一批已经合好的 n-step transition。 每条样本就封装了"从 $s_t$ 出发,执行 $a_t$,经历 n 步后所累积的奖励加 bootstrap"以及到达的末状态。 计算训练目标 对于每条抽出的 n-step 样本 $(s_t,a_t,G_t^{(n)},s_{t+n},\text{done}_{t+n})$, 如果 $\text{done}{t+n}=\text{False}$,则 $$ y = G_t^{(n)} + \gamma^n,\max{a'}Q(s_{t+n},a';\theta^-); $$ 如果 $\text{done}_{t+n}=\text{True}$,则 $$ y = G_t^{(n)}. $$ 主网络给出预测 把样本中的起始状态-动作对 $(s_t,a_t)$ 丢给在线的 Q 网络,得到当前估计的 $\hat{Q}(s_t,a_t)$。 更新网络 用"目标值 $y$"和"预测值 $\hat{Q}$"之间的平方差,构造损失函数。 对损失做梯度下降,调整在线网络参数,使得它的预测越来越贴近那条合并后的真实回报。 VDN 核心思路:将团队 Q 函数写成各智能体局部 Q 的线性和 $Q_{tot}=\sum_{i=1}^{N}\tilde{Q}_i$,在训练时用全局奖励反传梯度,在执行时各智能体独立贪婪决策。 CTDE 指 Centralized Training, Decentralized Execution —— 在训练阶段使用集中式的信息或梯度(可以看到全局状态、联合奖励、各智能体的隐藏变量等)来稳定、加速学习;而在执行阶段,每个智能体只依赖自身可获得的局部观测来独立决策。 采用 CTDE 的好处: 部署高效、可扩展:运行时每个体只需本地观测,无需昂贵通信和同步,适合大规模或通信受限场景。 降低非平稳性:每个智能体看到的“环境”里不再包含 其他正在同时更新的智能体——因为所有参数其实在同一次反向传播里被一起更新,整体策略变化保持同步;对单个智能体而言,环境动态就不会呈现出随机漂移。 避免“懒惰智能体”:只要某个行动对团队回报有正贡献,它在梯度里就能拿到正向信号,不会因为某个体率先学到高收益行为而使其他个体“无所事事”。 核心公式与训练方法 值分解假设 $$ Q\bigl((h_1,\dots,h_d),(a_1,\dots,a_d)\bigr);\approx;\sum_{i=1}^{d},\tilde{Q}_i(h_i,a_i) $$ 其中 $h_i$ 为第 $i$ 个智能体的历史观测,$a_i$ 为其动作。每个 $\tilde{Q}_i$ 只使用局部信息;训练时通过对联合 $Q$ 的 TD 误差求梯度,再"顺着求和"回传到各 $\tilde{Q}_i$ 。这样既避免了为各智能体手工设计奖励,又天然解决了联合动作空间呈指数爆炸的问题。 Q-learning 更新 $$ Q_{t+1}(s_t,a_t);=;(1-\eta_t),Q_{t}(s_t,a_t);+;\eta_t\bigl[r_t+\gamma\max_{a}Q_{t}(s_{t+1},a)\bigr] $$ 论文沿用经典 DQN 的 Q-learning 目标,对 联合 Q 值 计算 TD 误差,然后按上式更新;全局奖励 $r_t$ 会在反向传播时自动分摊到各 $\tilde{Q}_i$ 。 训练过程 使用LSTM:让智能体在「只有局部、瞬时观测」的环境中记住并利用过去若干步的信息。 1. 初始化 组件 说明 在线网络 为每个智能体 $i=1\ldots d$ 建立局部 $Q$ 网络 $\widetilde Q_i(h^i,a^i;\theta_i)$。最后一层是 值分解层:把所有 $\widetilde Q_i$ 相加得到联合 $Q=\sum_i\widetilde Q_i$ 目标网络 为每个体复制参数:$\theta_i^- \leftarrow \theta_i$,用于计算贝尔曼目标。 经验回放缓冲区 存储元组 $(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$,其中 $\mathbf a_t=(a_t^1,\dots,a_t^d)$。 超参数 Adam 学习率 $1\times10^{-4}$,折扣 $\gamma$,BPTT 截断长度 8,Eligibility trace $\lambda=0.9$ ;小批量 $B$、目标同步周期 $C$、$\varepsilon$-greedy 初始值等。 网络骨架:Linear (32) → ReLU → LSTM (32) → Dueling (Value + Advantage) 头产生 $\widetilde Q_i$ 。 2. 与环境交互并存储经验 局部隐藏状态更新(获得 $h_t^i$) 采样观测 $o_t^i \in \mathbb R^{3\times5\times5}$(RGB × 5 × 5 视野) 线性嵌入 + ReLU $x_t^i = \mathrm{ReLU}(W_o,\text{vec}(o_t^i)+b_o),; W_o!\in!\mathbb R^{32\times75}$ 递归更新 LSTM $h_t^i,c_t^i = \text{LSTM}{32}(x_t^i,;h{t-1}^i,c_{t-1}^i)$ (初始 $h_0^i,c_0^i$ 置零;执行期只用本体状态即可) 动作选择(分散执行) $$ a_t^i=\begin{cases} \text{随机动作}, & \text{概率 } \varepsilon,\ \arg\max_{a}\widetilde Q_i(h_t^i,a;\theta_i), & 1-\varepsilon. \end{cases} $$ 环境反馈:执行联合动作 $\mathbf a_t$,获得单条 团队奖励 $r_t$ 以及下一组局部观测 $o_{t+1}^i$。 重要:此处不要直接把 $h_{t+1}^i$ 写入回放池,而是存下 $(h_t^i, a_t^i, r_t, o_{t+1}^i)$。 之后在训练阶段再用同样的“Step 0” 方式,离线地把 $o_{t+1}^i\rightarrow h_{t+1}^i$。 这样可避免把梯度依赖塞进经验池。 写入回放池:$(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$。 3. 批量随机采样并联合训练 对缓冲区达到阈值后,每次更新步骤: 采样 $B$ 条长度为 $L$ 的序列。 假设抽到第 $k$ 条序列的第一个索引是 $t$。 依次取出连续的 $(h_{t+j}, a_{t+j}, r_{t+j}, o_{t+j+1}), j=0, \ldots, L-1$。 先用存储的 $o_{t+j+1}$ 离线重放"Step 0"得到 $h_{t+j+1}$,这样序列就拥有 $(h_{t+j}, h_{t+j+1})$ 前向计算 $$ \hat Q_i^{(k)} = \widetilde Q_i(h^{i,(k)}_t,a^{i,(k)}t;\theta_i), \quad \hat Q^{(k)}=\sum{i}\hat Q_i^{(k)} . $$ 贝尔曼目标(用目标网络) $$ y^{(k)} = r^{(k)} + \gamma \sum_{i}\max_{a}\widetilde Q_i(h^{i,(k)}_{t+1},a;\theta_i^-). $$ 损失 $$ L=\frac1B\sum_{k=1}^{B}\bigl(y^{(k)}-\hat Q^{(k)}\bigr)^2 . $$ 梯度反传(自动信用分配) 因为 $\hat Q=\sum_i\widetilde Q_i$,对每个 $\widetilde Q_i$ 的梯度系数恒为 1, 整个 团队 TD 误差 直接回流到各体网络,无需个体奖励设计 。 参数更新:$\theta_i \leftarrow \theta_i-\eta\nabla_{\theta_i}L$。 4. 同步 / 软更新目标网络 硬同步:每 $C$ 次梯度更新后执行 $\theta_i^- \leftarrow \theta_i$。 软更新:可选 $\theta_i^- \leftarrow \tau\theta_i+(1-\tau)\theta_i^-$。 5. 重复直到收敛 持续循环步骤 2–4,逐步衰减 $\varepsilon$。 训练完成后,每个体只需本地 $\widetilde Q_i$ 就能独立决策,与中心最大化 $\sum_i\widetilde Q_i$ 等价 。
论文
zy123
1年前
0
9
0
2025-05-05
动态图神经网络
动态图神经网络 如何对GAT的权重($W$)和注意力参数($a$)进行增量更新(邻居偶尔变化) 1. 核心思想 局部更新:邻居变化的节点及其直接邻域的权重和注意力参数需要调整,其他部分冻结。 梯度隔离:反向传播时,仅计算受影响节点的梯度,避免全局参数震荡。 2. 数学实现步骤 (1) 识别受影响的节点 设邻居变化后的新邻接矩阵为 $\tilde{A}$,原邻接矩阵为 $A$,受影响节点集合 $\mathcal{V}_{\text{affected}}$ 包括: 新增或删除边的两端节点(直接受影响)。 这些节点的1-hop邻居(间接受影响,根据GAT层数决定)。 (2) 损失函数局部化 仅对 $\mathcal{V}_{\text{affected}}$ 中的节点计算损失: $$ \mathcal{L}_{\text{incremental}} = \sum_{i \in \mathcal{V}_{\text{affected}}} \ell(y_i, \hat{y}_i) $$ 其中 $\ell$ 为交叉熵损失,$y_i$ 为标签,$\hat{y}_i$ 为模型输出。 (3) 梯度计算与参数更新 梯度掩码: 反向传播时,非受影响节点的梯度强制置零: $$ \nabla_{W,a} \mathcal{L}{\text{incremental}} = \left{ \begin{array}{ll} \nabla{W,a} \ell(y_i, \hat{y}i) & \text{if } i \in \mathcal{V}{\text{affected}} \ 0 & \text{otherwise} \end{array} \right. $$ 参数更新: 使用优化器(如Adam)仅更新有梯度的参数: $$ W \leftarrow W - \eta \nabla_W \mathcal{L}{\text{incremental}}, \quad a \leftarrow a - \eta \nabla_a \mathcal{L}{\text{incremental}} $$ 其中 $\eta$ 为较小的学习率(防止过拟合)。 (4) 注意力权重的动态适应 GAT的注意力机制会自动适应新邻居: $$ \alpha_{ij} = \text{softmax}\left(\text{LeakyReLU}\left(a^T [W h_i \| W h_j]\right)\right) $$ 由于 $W$ 和 $a$ 已局部更新,新邻居 $j \in \tilde{\mathcal{N}}(i)$ 的权重 $\alpha_{ij}$ 会重新计算。 3. 适用场景 低频变化:如社交网络每天新增少量边、论文引用网络月度更新。 局部变化:每次变化仅影响图中少量节点(<10%)。 若邻居高频变化(如秒级更新),需改用动态GNN(如TGAT)或时间序列建模。 EvolveGCN EvolveGCN-H 1. EvolveGCN-H核心思想 EvolveGCN-H 通过 GRU(门控循环单元) 动态更新 GCN 每一层的权重矩阵 $W_t^{(l)}$,将权重矩阵视为 GRU 的 隐藏状态,并利用当前时间步的 节点嵌入(特征) 作为输入来驱动演化。 关键特点: 输入依赖:利用节点嵌入 $H_t^{(l)}$ 指导权重更新。 时序建模:通过 GRU 隐式捕捉参数演化的长期依赖。 2. 动态更新流程(以第 $l$ 层为例) 输入: 当前节点嵌入矩阵 $H_t^{(l)} \in \mathbb{R}^{n \times d}$: 上一时间步的权重矩阵 $W_{t-1}^{(l)} \in \mathbb{R}^{d \times d'}$: 邻接矩阵 $A_t \in \mathbb{R}^{n \times n}$: 输出: 更新后的权重矩阵 $W_t^{(l)} \in \mathbb{R}^{d \times d'}$。 下一层节点嵌入 $H_t^{(l+1)} \in \mathbb{R}^{n \times d'}$。 3. 动态更新示意图 Time Step t-1 Time Step t +-------------------+ +-------------------+ | Weight Matrix | | Weight Matrix | | W_{t-1}^{(l)} | --(GRU更新)--> | W_t^{(l)} | +-------------------+ +-------------------+ ^ ^ | | +-------------------+ +-------------------+ | Node Embeddings | | Node Embeddings | | H_t^{(l)} | --(GCN计算)--> | H_t^{(l+1)} | +-------------------+ +-------------------+ ^ ^ | | +-------------------+ +-------------------+ | 邻接矩阵 A_t | | 邻接矩阵 A_{t+1} | | (显式输入) | | (下一时间步输入) | +-------------------+ +-------------------+ $$ \begin{align*} W_t^{(l)} &
论文
zy123
1年前
0
40
0
2025-03-31
KAN
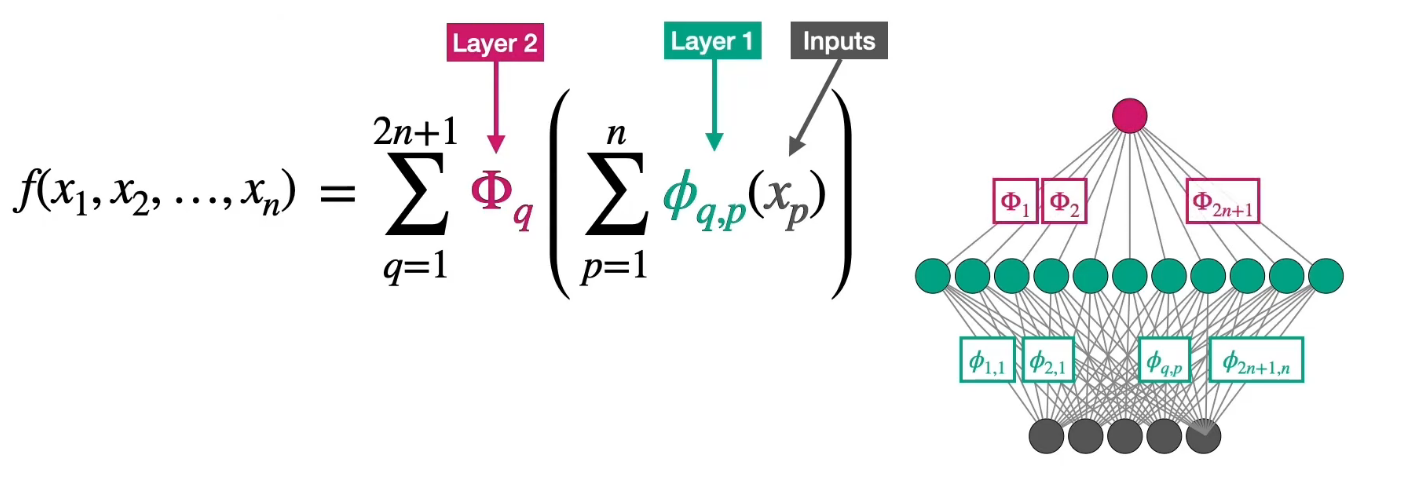
KAN Kolmogorov-Arnold表示定理 该定理表明,任何多元连续函数都可以表示为有限个单变量函数的组合。 对于任意一个定义在$[0,1]^n$上的连续多元函数: $$ f(x_1, x_2, \ldots, x_n), $$ 存在**单变量连续函数** $\phi_{q}$ 和 $\psi_{q,p}$(其中 $q = 1, 2, \ldots, 2n+1$,$p = 1, 2, \ldots, n$),使得: $$ f(x_1, \ldots, x_n) = \sum_{q=1}^{2n+1} \phi_{q}\left( \sum_{p=1}^{n} \psi_{q,p}(x_p) \right). $$ 即,$f$可以表示为$2n+1$个“外层函数”$\phi_{q}$和$n \times (2n+1)$个“内层函数”$\psi_{q,p}$的组合。 和MLP的联系 Kolmogorov-Arnold定理 神经网络(MLP) 外层函数 $\phi_q$ 的叠加 输出层的加权求和(线性组合) + 激活函数 内层函数 $\psi_{q,p}$ 的线性组合 隐藏层的加权求和 + 非线性激活函数 固定 $2n+1$ 个“隐藏单元” 隐藏层神经元数量可以自由设计,依赖于网络的深度和宽度 严格的数学构造(存在性证明) 通过数据驱动的学习(基于梯度下降等方法)来优化参数 和MLP的差异 浅层结构(一个隐藏层)的数学表达与模型设计 模型 数学公式 模型设计 MLP $f(x) \approx \sum_{i=1}^{N} a_i \sigma(w_i \cdot x + b_i)$ 线性变换后再跟非线性激活函数(RELU) KAN $f(x) = \sum_{q=1}^{2n+1} \Phi_q \left( \sum_{p=1}^n \phi_{q,p}(x_p) \right)$ 可学习激活函数(如样条)在边上,求和操作在神经元上 边上的可学习函数: $\phi_{q,p}(x_p)$(如B样条) 求和操作:$\sum_{p=1}^n \phi_{q,p}(x_p)$ 深层结构的数学表达与模型设计 模型 数学公式 模型设计 MLP $\text{MLP}(x) = (W_3 \circ \sigma_2 \circ W_2 \circ \sigma_1 \circ W_1)(x)$ 交替的线性层($W_i$)和固定非线性激活函数($\sigma_i$)。 KAN $\text{KAN}(x) = (\Phi_3 \circ \Phi_2 \circ \Phi_1)(x)$ 每一层都是单变量函数的组合($\Phi_i$),每一层的激活函数都可以进行学习 传统MLP的缺陷 梯度消失和梯度爆炸: 与其他传统的激活函数(如 Sigmoid 或 Tanh)一样,MLP 在进行反向传播时有时就会遇到梯度消失/爆炸的问题,尤其当网络层数过深时。当它非常小或为负大,网络会退化;连续乘积会使得梯度慢慢变为 0(梯度消失)或变得异常大(梯度爆炸),从而阻碍学习过程。 参数效率: MLP 常使用全连接层,每层的每个神经元都与上一层的所有神经元相连。尤其是对于大规模输入来说,这不仅增加了计算和存储开销,也增加了过拟合的风险。效率不高也不够灵活。 处理高维数据能力有限:MLP 没有利用数据的内在结构(例如图像中的局部空间相关性或文本数据的语义信息)。例如,在图像处理中,MLP 无法有效地利用像素之间的局部空间联系,这很典型在图像识别等任务上的性能不如卷积神经网络(CNN)。 长依赖问题: 虽然 MLP 理论上可以逼近任何函数,但在实际应用中,它们很难捕捉到序列中的长依赖关系(例如句子跨度很长)。这让人困惑:如何把前后序列的信息互相处理?而自注意力(如 transformer)在这类任务中表现更好。 但无论CNN/RNN/transformer怎么改进,都躲不掉MLP这个基础模型根上的硬伤,即线性组合+激活函数的模式。 KAN网络 主要贡献: 过去的类似想法受限于原始的Kolmogorov-Arnold表示定理(两层网络,宽度为2n+12n+1),未能利用现代技术(如反向传播)进行训练。 KAN通过推广到任意宽度和深度的架构,解决了这一限制,同时通过实验验证了KAN在“AI + 科学”任务中的有效性,兼具高精度和可解释性。 B样条(B-spline) 是一种通过分段多项式函数的线性组合构造的光滑曲线,其核心思想是利用局部基函数(称为B样条基函数)来表示整个曲线。 形式上,一个B样条函数通常表示为基函数的线性组合: $$ S(t) = \sum_{i=0}^{n} c_i \cdot B_i(t) $$ 其中: $B_i(t)$ 是 B样条基函数(basis functions); $c_i$ 是 控制点 或系数(可以来自数据、拟合、插值等); $S(t)$ 是最终的 B样条曲线 或函数。 每个基函数只在某个局部区间内非零,改变一个控制点只会影响曲线的局部形状。 示例:基函数定义 $B_0(t)$ - 支撑区间[0,1] $$ B_0(t) = \begin{cases} 1 - t, & 0 \leq t < 1,\\ 0, & \text{其他区间}. \end{cases} $$ $B_1(t)$ - 支撑区间[0,2] $$ B_1(t) = \begin{cases} t, & 0 \leq t < 1, \\ 2 - t, & 1 \leq t < 2, \\ 0, & \text{其他区间}. \end{cases} $$ $B_2(t)$ - 支撑区间[1,3] $$ B_2(t) = \begin{cases} t - 1, & 1 \leq t < 2, \\ 3 - t, & 2 \leq t < 3, \\ 0, & \text{其他区间}. \end{cases} $$ $B_3(t)$ - 支撑区间[2,4] $$ B_3(t) = \begin{cases} t - 2, & 2 \leq t < 3, \\ 4 - t, & 3 \leq t \leq 4, \\ 0, & \text{其他区间}. \end{cases} $$ 假设用该基函数对$f(t) = \sin\left(\dfrac{\pi t}{4}\right)$在[0,4]区间上拟合 $$ S(t) = 0 \cdot B_0(t) + 0.7071 \cdot B_1(t) + 1 \cdot B_2(t) + 0.7071 \cdot B_3(t) $$ 网络结构: 左图: 节点(如$x_{l,i}$)表示第$l$层第$i$个神经元的输入值 边(如$\phi_{l,j,i}$)表示可学习的激活函数(权重) 下一层节点的值计算: $$x_{l+1,j} = \sum_i \phi_{l,j,i}(x_{l,i})$$ 右图:
论文
zy123
1年前
0
18
0
1
2
下一页