首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
58
篇与
zy123
相关的结果
- 第 7 页
2025-03-21
机器学习
机器学习与深度学习 机器学习 监督学习 监督学习(Supervised Learning) 定义:所有训练数据都具有明确的标签,模型通过这些标签进行学习。 特点:模型训练相对直接,性能受限于标注数据的质量和数量。 示例:传统的分类问题,如手写数字识别、垃圾邮件检测等。 无监督学习(Unsupervised Learning) 定义:训练数据完全没有标签,模型需要自己去发现数据中的模式或结构。 特点:常用于聚类、降维、关联规则挖掘等任务,难以直接用于分类任务。 示例:聚类算法(如K-means)和主成分分析(PCA)。 半监督学习(Semi‑supervised Learning) 定义:介于监督学习和无监督学习之间,使用少量带标签的数据和大量未标签的数据共同训练模型,以在标注数据稀缺时提升分类性能。 特点:结合标签信息与数据分布结构,通过利用未标签数据的内在聚类或流形结构降低对标注数据的依赖,从而提高模型泛化能力并降低标注成本;通常依赖平滑假设和聚类假设等前提。 示例:在猫狗图像分类任务中,先使用少量已标记的猫狗图片训练初始模型,再用该模型为大量未标记图片生成“伪标签”,将这些伪标签数据与原有标记数据合并重新训练,从而获得比仅使用有标签数据更高的分类准确率。 在半监督学习中,为了避免将错误的模型预测“伪标签”纳入训练,必须对每个未标注样本的预测结果进行可信度评估,只保留高置信度、准确率更高的伪标签作为新增训练数据。 深度学习 前向传播 Mini Batch梯度下降 Batch Size(批大小) 定义 Batch Size 指在深度学习模型训练过程中,每次迭代送入网络进行前向传播和反向传播的样本数量。 特点 Batch Size 决定了梯度更新的频率和稳定性;较大的 Batch Size 能更好地利用 GPU 并行计算、减少迭代次数、加快训练速度,但会显著增加显存占用且可能降低模型泛化能力;较小的 Batch Size 则带来更大的梯度噪声,有助于跳出局部最优、提高泛化性能,但训练过程更不稳定且耗时更长。 示例:在 PyTorch 中,使用 DataLoader(dataset, batch_size=32, shuffle=True) 表示每次迭代从数据集中抽取 32 个样本进行训练。一个batch的所有样本会被打包成一个张量,一次性并行送入网络进行计算 将完整训练集分割成若干大小相同的小批量(mini‑batch),每次迭代仅使用一个 mini‑batch 来计算梯度并更新模型参数,结合了批量梯度下降(Batch GD)和随机梯度下降(SGD)的优势。 当 batch_size=1 时退化为随机梯度下降;当 batch_size=m(训练集总样本数)时退化为批量梯度下降。 通常选择 2 的幂(如32、64、128、256)以匹配 GPU/CPU 内存布局并提升运算效率。 算法流程 将训练数据随机打乱并按 batch_size 划分成多个 mini‑batch。 对每个 mini‑batch 执行: 前向传播计算输出。 计算 mini‑batch 上的平均损失。 反向传播计算梯度。 按公式更新参数: $$ \theta \leftarrow \theta - \eta \frac{1}{|\text{batch}|}\sum_{i\in \text{batch}} \nabla_\theta \mathcal{L}(x_i,y_i) $$ 遍历所有 mini‑batch 即完成一个 epoch,可重复多轮直到收敛。 Softmax 公式 假设有一个输入向量 $$ z = [z_1, z_2, \dots, z_K], $$ 则 softmax 函数的输出为: $$ \sigma(z)_i = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}, $$ 其中 $i = 1, 2, \dots, K$。 分子:对每个 $z_i$ 取自然指数 $e^{z_i}$,目的是将原始的实数扩展到正数范围。 分母:对所有 $e^{z_j}$ 求和,从而实现归一化,使得所有输出概率和为 1。 交叉熵损失 假设有三个类别,真实标签为第二类,因此用 one-hot 编码表示为: $$ y = [0,\; 1,\; 0]. $$ 假设模型经过 softmax 后输出的预测概率为: $$ \hat{y} = [0.2,\; 0.7,\; 0.1]. $$ 交叉熵损失函数的定义为: $$ L = -\sum_{i=1}^{3} y_i \log \hat{y}_i. $$ 将 $y$ 和 $\hat{y}$ 的对应元素代入公式中: $$ L = -(0 \cdot \log 0.2 + 1 \cdot \log 0.7 + 0 \cdot \log 0.1) = -\log 0.7. $$ 计算 $-\log 0.7$(以自然对数为例): $$ -\log 0.7 \approx -(-0.3567) \approx 0.3567. $$ 因此,这个样本的交叉熵损失大约为 0.3567。 残差连接 假设一个神经网络层(或一组层)的输入为 $x$,传统的设计会期望该层直接学习一个映射 $F(x)$。而采用残差连接的设计,则将输出定义为: $$ \text{Output} = F(x) + x. $$ 这里: $F(x)$ 表示经过几层变换(比如卷积、激活等)后所学到的“残差”部分, $x$ 则是直接通过捷径传递过来的输入。 为什么使用残差连接 缓解梯度消失问题 在深层网络中,梯度往往会在反向传播过程中逐层衰减,而残差连接为梯度提供了一条捷径,使得梯度可以直接从后面的层传递到前面的层,从而使得网络更容易训练。 简化学习任务 网络不必学习从零开始构造一个完整的映射,而只需要学习输入与目标之间的残差。这样可以使得学习任务变得更简单,更易收敛。 提高网络性能 在很多实际应用中(例如图像识别中的 ResNet),引入残差连接的网络能训练得更深,并在多个任务上取得更好的效果。
科研
zy123
1年前
0
13
0
2025-03-21
传统图机器学习
传统图机器学习和特征工程 节点层面的特征工程 目的:描述网络中节点的结构和位置 eg:输入某个节点的D维向量,输出该节点是某类的概率。 节点度 (Node Degree) 定义: 节点度是指一个节点直接连接到其他节点的边数。 无向图中: 节点的度即为与其相邻的节点数。 有向图中: 通常区分为入度(有多少条边指向该节点)和出度(从该节点发出的边的数量)。 意义: 节点度直观反映了节点在网络中的直接连接能力。度高的节点通常在信息传播或资源分配中具有较大作用。 例如,在社交网络中,一个拥有大量好友的用户(高节点度)可能被视为“热门”或者“活跃”的社交人物。 节点中心性 (Node Centrality) 定义: 节点中心性是一类衡量节点在整个网络中“重要性”或“影响力”的指标。其核心思想是,不仅要看节点的直接连接数,还要看它在网络中的位置和在信息流动中的角色。 常见的指标: 介数中心性 (Betweenness Centrality): 衡量节点位于其他节点间最短路径上的频率,反映其作为“桥梁”的作用。 接近中心性 (Closeness Centrality): 衡量节点到网络中其他节点平均距离的倒数,距离越近中心性越高。 特征向量中心性 (Eigenvector Centrality): 除了考虑连接数量外,还考虑邻居节点的“重要性”,连接到重要节点会提升自身的中心性。 举例: 假设有 3 个节点,记为 $1, 2, 3$,它们构成了一条链: $$ 1 \; \leftrightarrow \; 2 \; \leftrightarrow \; 3 $$ 即只有边 $(1,2)$ 和 $(2,3)$,没有直接连接 $(1,3)$。 令邻接矩阵 $A$ 为: $$ A \;=\; \begin{pmatrix} 0 & 1 & 0\\ 1 & 0 & 1\\ 0 & 1 & 0 \end{pmatrix}. $$ 介数中心性(必经之地): $$ \displaystyle c_v \;=\; \sum_{s \neq t}\; \frac{\sigma_{st}(v)}{\sigma_{st}}, $$ 其中 $\sigma_{st}$ 表示从节点 $s$ 到节点 $t$ 的所有最短路径数; $\sigma_{st}(v)$ 表示这些最短路径当中经过节点 $v$ 的条数; 求和一般只考虑 $s \neq t$ 且 $s \neq v \neq t$ 的情形,避免把端点本身算作中间节点。 换言之,节点 $v$ 的介数中心性就是它作为“中间节点”出现在多少对 $(s,t)$ 的最短路径上。 对 3 个节点 ${1,2,3}$,不同的 $(s,t)$ 有: $(s,t)=(1,2)$:最短路径为 $(1,2)$。 路径上节点:1 → 2 中间节点:无 (1、2 是端点) $(s,t)=(1,3)$:最短路径为 $(1,2,3)$。 路径上节点:1 → 2 → 3 中间节点:2 $(s,t)=(2,3)$:最短路径为 $(2,3)$。 路径上节点:2 → 3 中间节点:无 (2、3 是端点) 节点 1 只会出现在路径 (1,2) 或 (1,3) 的端点位置;(2,3) 的最短路径不包含 1。 端点不计作中间节点,所以 $\sigma_{st}(1) = 0$ 对所有 $s\neq t\neq 1$。 因此 $$ c_1 = 0. $$ 节点 2 在 (1,3) 的最短路径 (1,2,3) 中,2 是中间节点。此时 $\sigma_{1,3}(2) = 1$; (1,2) 路径 (1,2) 中 2 是端点,(2,3) 路径 (2,3) 中 2 也是端点,因此不计入中间节点。 所以 $$ c_2 = \underbrace{\frac{\sigma_{1,3}(2)}{\sigma_{1,3}}}_{=1/1=1} ;=; 1. $$ 接近中心性(去哪儿都近): $$ c_v \;=\; \frac{1}{\sum_{u \neq v} d(u,v)}, $$ 其中 $d(u,v)$ 表示节点 $u$ 与节点 $v$ 的最短路径距离。 节点1: 与节点 2 的距离:$d(1,2)=1$。 与节点 3 的距离:$d(1,3)=2$(路径 1→2→3)。 距离和:$;1 + 2 = 3.$ 接近中心性:$; c_1 = \tfrac{1}{3} \approx 0.333.$ 其他两节点同理。 特征向量中心性 特征向量中心性要求我们求解 $$ A\,\mathbf = \lambda\,\mathbf , $$ 并选取对应**最大特征值** $\lambda$ 的特征向量 $\mathbf $ 来代表每个节点的中心性。 记 $\mathbf = (x_1,,x_2,,x_3)^T$ 这里 $x_1$ 是节点 1 的中心性值,$x_2$ 是节点 2 的中心性值,$x_3$ 是节点 3 的中心性值 方程 $A,\mathbf = \lambda,\mathbf $ 具体展开 $$ \begin{pmatrix} 0 & 1 & 0\ 1 & 0 & 1\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} x_1\ x_2\ x_3 \end{pmatrix} ;=; \lambda \begin{pmatrix} x_1\ x_2\ x_3 \end{pmatrix}. $$ 这意味着: $$ \begin{cases} 1.; x_2 = \lambda, x_1, \ 2.; x_1 + x_3 = \lambda, x_2, \ 3.; x_2 = \lambda, x_3. \end{cases} $$ 求解最大特征值 $\lambda$ 及对应的 $\mathbf $ 通过特征多项式可知本矩阵的最大特征值为 $\sqrt{2}$。 最终(若需单位化)可以将向量归一化为 $$ \mathbf = \frac{1}{2},\begin{pmatrix} 1 \ \sqrt{2} \ 1 \end{pmatrix}. $$ 解释 节点 2 的得分最高($\tfrac{\sqrt{2}}{2}\approx 0.707$),因为它连接了节点 1 和 3,两边的贡献都能“传递”到它。 节点 1 和 3 的得分相同且略低($\tfrac{1}{2}=0.5$),因为它们都只与节点 2 相连。 聚类系数 (Clustering Coefficient) 定义: 聚类系数描述一个节点的邻居之间彼此相连的紧密程度。 对于某个节点,其局部聚类系数计算为: $$ C = \frac{2 \times \text{实际邻居间的边数}}{k \times (k-1)} $$ 其中 $k$ 为该节点的度数。 意义: 高聚类系数: 表示节点的邻居往往彼此熟识,形成紧密的小团体。 低聚类系数: 则说明邻居之间联系较少,节点更多处于桥梁位置,可能连接不同的社群。 在很多网络中,聚类系数能揭示局部社区结构和节点的协同效应。 Graphlets 定义: Graphlets 是指网络中规模较小(通常由3至5个节点构成)的非同构子图。 通过统计一个节点参与的各种 graphlet 模式的数量,我们可以构造出该节点的 Graphlet Degree Vector (GDV)。 意义: Graphlets 能捕捉节点在局部网络结构中的精细模式,比单纯的度数或聚类系数提供更丰富的信息。 在很多应用中(如生物网络分析或社交网络挖掘),通过分析节点参与的 graphlet 模式,可以更好地理解节点的功能和在整个网络中的角色。 Graphlets 被视为网络的“结构指纹”,有助于区分功能不同的节点。 连接层面的特征工程 目的:通过已知连接补全未知连接 eg: AB之间有连接,BC之间有连接,那么AC之间是否可能有连接呢? 法一:直接提取连接的特征,把连接变成D维向量(推荐)。 法二:把连接两端节点的D维向量拼接,即上一讲的节点特征拼接(不推荐,损失了连接本身的结构信息。) Distance-based Feature 核心思路: 用两个节点之间的最短路径长度(或加权距离等)作为边的特征,衡量节点对的“接近”程度。 Local Neighborhood Overlap 核心思路: 度量两个节点在其“一阶邻居”层面共享多少共同邻居,或者它们的邻居集合相似度如何。 Common Neighbors $$ \text{CN}(u,v) ;=; \bigl|,N(u),\cap,N(v)\bigr|, $$ 其中 $N(u)$ 是节点 $u$ 的邻居集合,$\cap$ 表示交集。数值越大,表示两节点在局部网络中有更多共同邻居。 Jaccard Coefficient $$ \text{Jaccard}(u,v) ;=; \frac{\bigl|,N(u),\cap,N(v)\bigr|}{\bigl|,N(u),\cup,N(v)\bigr|}. $$ 反映了两个节点邻居集合的交并比,越大则两者邻居越相似。 Adamic-Adar $$ \text{AA}(u,v) ;=; \sum_{w ,\in, N(u),\cap,N(v)} \frac{1}{\log,\bigl|N(w)\bigr|}. $$ 共同邻居数目较多、且这些邻居本身度数越小,贡献越大。常用于社交网络链接预测。(直观理解:如果AB都认识C,且C是个社牛,那么AB之间的友谊就不一定好) Global Neighborhood Overlap 核心思路: 不只看“一阶邻居”,还考虑更大范围(如 2 步、3 步乃至更多跳数)上的共同可达节点,或更广泛的结构相似度。 Katz 指标:累加节点间所有长度的路径并衰减; Random Walk:基于随机游走来度量节点对的全局可达性; Graph Embedding:DeepWalk、node2vec等,都可将多跳结构信息编码到向量表示里,再用向量相似度当作边特征。 真实情况如何编码边的特征? 在一个 边的特征工程 任务中,可以将 Distance-based Feature、Local Neighborhood Overlap 和 Global Neighborhood Overlap 等特征组合起来,形成一个完整的特征向量。 例如:对于每条边 $ (u,v) $,我们提取以下 6 种特征: 最短路径长度 $ d(u,v) $ (Distance-based Feature) 共同邻居数 $ CN(u,v) $ (Local Neighborhood Overlap) Jaccard 系数 $ Jaccard(u,v) $ (Local Neighborhood Overlap) Adamic-Adar 指标 $ AA(u,v) $ (Local Neighborhood Overlap) Katz 指数 $ Katz(u,v) $ (Global Neighborhood Overlap) Random Walk 访问概率 $ RW(u,v) $ (Global Neighborhood Overlap) 对于图中某条边 $ (A, B) $,它的特征向量可能是: $$ \mathbf{f}(A, B) = \big[ 2, 5, 0.42, 0.83, 0.31, 0.45 \big] $$ 图层面的特征工程 目的:网络相似度、图分类(已知分子结构判断是否有xx特性) 当我们要对整张图进行分类或比较(如图分类、图相似度计算等),需要将图转化为可比较的向量或特征。最朴素的想法是: Bag-of-Node-Degrees:统计每个节点的度,然后构建一个“度分布”或“度直方图”。 例如,对图 $G$,我们计算 $\phi(G) = [,\text{count of deg}=1,\ \text{count of deg}=2,\ \dots,]$。 缺点:只关注了节点度,无法区分很多结构不同、但度分布相同的图。 为解决这个不足,人们提出了更精细的“Bag-of-*”方法,把节点周围的更丰富结构(子图、子树、图形)纳入统计,从而形成更有判别力的特征。 Graphlet Kernel Graphlets:指小规模(如 3 节点、4 节点、5 节点)的非同构子图。 做法:枚举或随机采样网络中的所有小型子图(graphlets),并根据其类型计数出现频率。 比如在 4 节点层面,有 6 种不同的非同构结构,就统计每种结构出现多少次。 得到的特征:一个“graphlet type”直方图,即 $\phi(G) = \big[\text{count}(\text{graphlet}_1), \dots, \text{count}(\text{graphlet}_k)\big]$。 优点:比单纯节点度更能捕捉网络的局部模式。 缺点:当图很大时,遍历或采样 graphlet 代价较高;仅依赖小子图也可能忽略更大范围结构。 Weisfeiler–Lehman Kernel Weisfeiler–Lehman (WL) 核是一种基于迭代标签传播的方法,用于图同构测试和图相似度计算。 核心思路: 初始标签:给每个节点一个初始标签(可能是节点的类型或颜色)。 迭代更新:在每一步迭代中,将节点自身标签与其邻居标签拼接后做哈希,得到新的标签。 记录“标签多重集”:每次迭代会产生新的节点标签集合,可视为“节点子树结构”的某种编码。 Bag-of-Labels / Bag-of-Subtrees: 在每一轮迭代后,统计各类标签出现次数,累加到特征向量中。 相当于对节点子树或“局部邻域结构”做词袋统计。 优点:在保留更多结构信息的同时,计算复杂度相对可控。 缺点:仍然可能有一定的“同构测试”盲区;对于非常复杂的图,标签碰撞可能出现。 例子: 假设我们有一个简单的无向图,包含 4 个节点和 4 条边,结构如下: 1 — 2 — 3 | 4 1. 初始化标签 首先,给每个节点一个初始标签。假设我们直接用节点的度数作为初始标签: 初始标签如下: 节点 1: 1 节点 2: 3 节点 3: 1 节点 4: 1 2. 第一次迭代 在第一次迭代中,每个节点的标签会更新为其自身标签和邻居标签的拼接,然后通过哈希函数生成新的标签。 节点 1: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 节点 2: 邻居是节点 1、3、4,标签分别为 1、1、1。 拼接后的标签为 (3, 1, 1, 1)。 假设哈希结果为 B。 节点 3: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 节点 4: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 第一次迭代后的标签如下: 节点 1: A 节点 2: B 节点 3: A 节点 4: A 3. 第二次迭代 节点 1: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 节点 2: 邻居是节点 1、3、4,标签分别为 A、A、A。 拼接后的标签为 (B, A, A, A)。 假设哈希结果为 D。 节点 3: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 节点 4: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 第二次迭代后的标签如下: 节点 1: C 节点 2: D 节点 3: C 节点 4: C 4. 停止条件 通常,WL Kernel 会进行多次迭代,直到节点的标签不再变化(即收敛)。在这个例子中,假设我们只进行两次迭代。 5.统计标签的多重集 在每次迭代后,统计图中所有节点的标签分布(即“标签多重集”),并将其作为图的特征。 初始标签多重集: 标签 1 出现 3 次(节点 1、3、4)。 标签 3 出现 1 次(节点 2)。 第一次迭代后的标签多重集: 标签 A 出现 3 次(节点 1、3、4)。 标签 B 出现 1 次(节点 2)。 第二次迭代后的标签多重集: 标签 C 出现 3 次(节点 1、3、4)。 标签 D 出现 1 次(节点 2)。 $$ \phi(G) = [\text{count}(1), \text{count}(3), \text{count}(A), \text{count}(B), \text{count}(C), \text{count}(D)]. \\ \phi(G) = [3, 1, 3, 1, 3, 1]. $$ 直观理解 初始标签:只关注节点的度数。 第一次迭代:关注节点的度数及其邻居的度数。 第二次迭代:关注节点的度数、邻居的度数,以及邻居的邻居的度数。 随着迭代的进行,WL Kernel 能够捕捉到越来越复杂的局部结构信息。
科研
zy123
1年前
0
13
0
2025-03-21
PID控制器
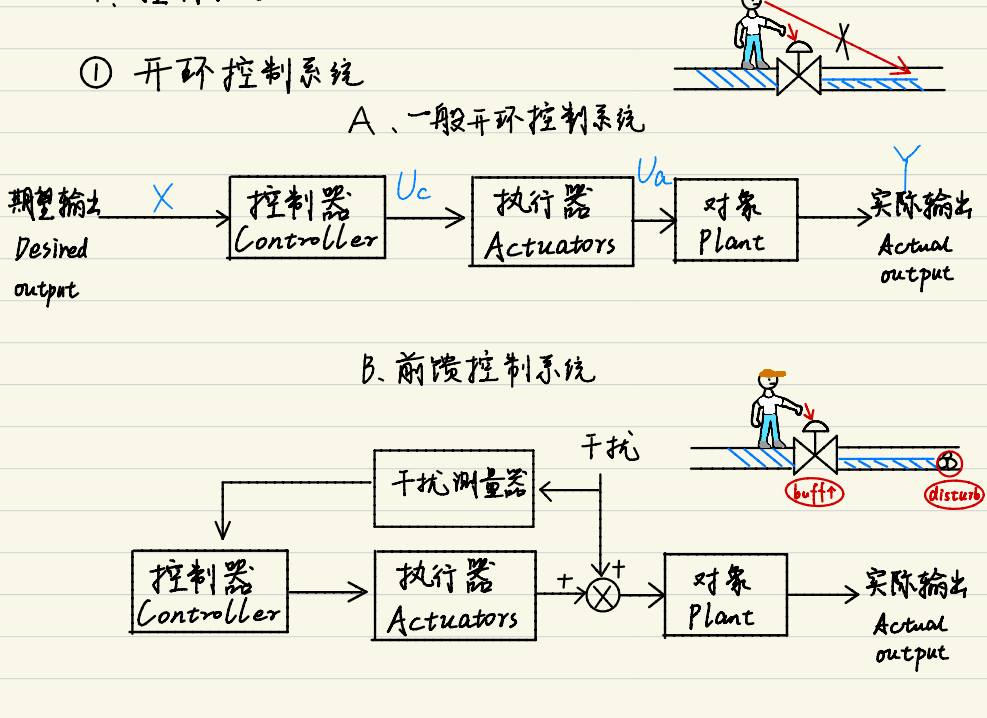
PID控制器 PID控制器是一种常用的反馈控制系统,广泛应用于工业控制系统和各种控制系统中,用来持续调整一个过程的控制输入,以减小系统当前位置和期望位置之间的误差。PID代表比例(Proportional)、积分(Integral)、微分(Derivative)。 控制系统概述 开环控制系统 前馈控制系统尝试预先计算扰动对系统的影响,并在扰动影响系统输出之前调整输入以抵消它。 闭环控制系统 控制器接收误差信号。该系统通过反馈回路来自动调节其输出 复合控制系统 连续与离散信号 从连续信号到离散信号的转换过程涉及以下步骤: 采样:在连续信号上每隔一定时间间隔取一个值。 量化:将每个采样值映射到最接近的量化级上。 积分可以通过求和来近似,微分可以通过相邻样本之间的差分来近似。 PID公式 控制系统中的传感器会连续监测被控制对象的状态(例如,温度、压力、位置等),而PID控制器通过在固定的采样间隔收集输入信号,将其转换为离散信号,计算控制动作,然后输出到控制对象。离散PID控制的优势在于其灵活性和适应性,它可以轻松地与软件算法集成。 直观例子 **仅使用比例(P)控制无法消除稳态误差。**稳态误差是指当系统达到平衡状态时,控制系统的实际输出与期望输出之间的差异。 原因:当系统接近其期望点时,误差减小,进而控制器输出也减小。如果控制器输出减小到无法克服系统内部阻力(如摩擦力)或外部扰动的程度时,系统就无法进一步接近设定点,从而留下稳态误差。 为了解决稳态误差问题,通常会在P控制基础上加入积分(I)控制。积分控制能够累积误差,即使是很小的误差,也会随时间积累,最终产生足够的控制作用以调整系统输出,直到误差为零。 微分控制在PID控制器中的作用主要是提高系统的瞬态响应和稳定性。 $$ {k}_{d}({e}_{i}-{e}_{i-1}) $$ 它通过对误差信号的变化率(即误差的微分)进行响应,来预测系统未来的行为。如果误差在快速变化,微分项会产生一个相对较大的控制作用来尝试减缓这种变化。 相关控制知识 当系统启动时或者遇到大的扰动,会产生大的初始误差。若系统调整缓慢,积分项会在达到目标状态之前累积很大的值。这可导致控制器输出超出了实际的执行器(比如电机、阀门等)可以处理的范围。当这种情况发生时,即使误差减少,由于积分项累积的值太大,控制器的输出可能仍然处于饱和状态。 积分限幅 积分限幅可防止积分项超过预设的上限和下限。 $$ {I}_{clamped}(t)=clamp({I}_{updated(t)},{I}_{max},{I}_{min}) $$ 积分分离 当误差超过某个预定阈值时,禁用积分作用,仅使用比例(P)和微分(D)控制来快速减小误差,避免因积分作用导致的控制器输出过度响应。 if (abs(error) > threshold) { // 积分作用被分离,即暂时禁用积分作用 integral = 0; } else { // 正常积分累积 integral += error * dt; } PID控制器: def update(self, current_value): error = self.set_point - current_value # 实现积分分离逻辑 if abs(error) < self.error_threshold: self.integral += error * self.dt # 应用积分限幅 self.integral = max(min(self.integral, self.integral_limit), -self.integral_limit) else: # 误差过大时重置积分累积 self.integral = 0 derivative = (error - self.prev_error) / self.dt # PID 输出 output = self.Kp * error + self.Ki * self.integral + self.Kd * derivative self.prev_error = error return output
科研
zy123
1年前
0
11
0
2025-03-21
交替方向乘子法(ADMM)
交替方向乘子法(ADMM) Alternating Direction Method of Multipliers (ADMM) 是一种用于求解大规模优化问题的高效算法,结合了拉格朗日乘子法和分裂方法的优点。 基本概念 优化问题分解 ADMM 的核心思想是将复杂优化问题分解为多个较简单的子问题,通过引入辅助变量将原问题转化为约束优化问题,使子问题独立求解。 拉格朗日乘子 利用拉格朗日乘子处理约束条件,构造增强拉格朗日函数,确保子问题求解时同时考虑原问题的约束信息。 交替更新 通过交替更新子问题的解和拉格朗日乘子,逐步逼近原问题的最优解。 算法流程 问题分解 将原问题分解为两个子问题。假设原问题表示为: $\min_{x, z} f(x) + g(z) \quad \text{s.t.} \quad Ax + Bz = c$ 其中 $f$ 和 $g$ 是凸函数,$A$ 和 $B$ 为给定矩阵。 构造增强拉格朗日函数 引入拉格朗日乘子 $y$,构造增强拉格朗日函数: $L_\rho(x, z, y) = f(x) + g(z) + y^T(Ax+Bz-c) + \frac{\rho}{2}|Ax+Bz-c|^2$ 其中 $\rho > 0$ 控制惩罚项的权重。 交替更新 更新 $x$:固定 $z$ 和 $y$,求解 $\arg\min_x L_\rho(x, z, y)$。 更新 $z$:固定 $x$ 和 $y$,求解 $\arg\min_z L_\rho(x, z, y)$。 更新乘子 $y$:按梯度上升方式更新: $y := y + \rho(Ax + Bz - c)$ 迭代求解 重复上述步骤,直到原始残差和对偶残差满足收敛条件(如 $|Ax+Bz-c| < \epsilon$)。 例子 下面给出一个简单的数值例子,展示 ADMM 在求解分解问题时的迭代过程。我们构造如下问题: $$ \begin{aligned} \min_{x, z}\quad & (x-1)^2 + (z-2)^2 \\ \text{s.t.}\quad & x - z = 0. \end{aligned} $$ 注意:由于约束要求 $x=z$,实际问题等价于 $$ \min_ (x-1)^2 + (x-2)^2, $$ 其解析最优解为: $$ 2(x-1)+2(x-2)=4x-6=0\quad\Rightarrow\quad x=1.5, $$ 因此我们希望得到 $x=z=1.5$。 构造 ADMM 框架 将问题写成 ADMM 标准形式: 令 $$ f(x)=(x-1)^2,\quad g(z)=(z-2)^2, $$ 约束写为 $$ x-z=0, $$ 即令 $A=1$、$B=-1$、$c=0$。 增强拉格朗日函数为 $$ L_\rho(x,z,y)=(x-1)^2+(z-2)^2+y(x-z)+\frac{\rho}{2}(x-z)^2, $$ 其中 $y$ 是拉格朗日乘子,$\rho>0$ 是惩罚参数。为简单起见,我们选取 $\rho=1$。 ADMM 的更新公式 针对本问题可以推导出三个更新步骤: 更新 $x$: 固定 $z$ 和 $y$,求解 $$ x^{k+1} = \arg\min_x; (x-1)^2 + y^k(x-z^k)+\frac{1}{2}(x-z^k)^2. $$ 对 $x$ 求导并令其为零: $$ 2(x-1) + y^k + (x-z^k)=0 \quad\Rightarrow\quad (2+1)x = 2 + z^k - y^k, $$ 得到更新公式: $$ x^{k+1} = \frac{2+z^k-y^k}{3}. $$ 更新 $z$: 固定 $x$ 和 $y$,求解 $$ z^{k+1} = \arg\min_z; (z-2)^2 - y^kz+\frac{1}{2}(x^{k+1}-z)^2. $$ 注意:由于 $y(x-z)$ 中关于 $z$ 的部分为 $-y^kz$(常数项 $y^kx$ 可忽略),求导得: $$ 2(z-2) - y^k - (x^{k+1}-z)=0 \quad\Rightarrow\quad (2+1)z = 4 + y^k + x^{k+1}, $$ 得到更新公式: $$ z^{k+1} = \frac{4+y^k+x^{k+1}}{3}. $$ 更新 $y$: 按梯度上升更新乘子: $$ y^{k+1} = y^k + \rho,(x^{k+1}-z^{k+1}). $$ 这里 $\rho=1$,所以 $$ y^{k+1} = y^k + \bigl(x^{k+1}-z^{k+1}\bigr). $$ 数值迭代示例 第 1 次迭代: 更新 $x$: $$ x^1 = \frac{2+z^0-y^0}{3}=\frac{2+0-0}{3}=\frac{2}{3}\approx0.667. $$ 更新 $z$: $$ z^1 = \frac{4+y^0+x^1}{3}=\frac{4+0+0.667}{3}\approx\frac{4.667}{3}\approx1.556. $$ 更新 $y$: $$ y^1 = y^0+(x^1-z^1)=0+(0.667-1.556)\approx-0.889. $$ 第 2 次迭代: 更新 $x$: $$ x^2 = \frac{2+z^1-y^1}{3}=\frac{2+1.556-(-0.889)}{3}=\frac{2+1.556+0.889}{3}\approx\frac{4.445}{3}\approx1.4817. $$ 更新 $z$: $$ z^2 = \frac{4+y^1+x^2}{3}=\frac{4+(-0.889)+1.4817}{3}=\frac{4-0.889+1.4817}{3}\approx\frac{4.5927}{3}\approx1.5309. $$ 更新 $y$: $$ y^2 = y^1+(x^2-z^2)\approx -0.889+(1.4817-1.5309)\approx -0.889-0.0492\approx -0.938. $$ 第 3 次迭代: 更新 $x$: $$ x^3 = \frac{2+z^2-y^2}{3}=\frac{2+1.5309-(-0.938)}{3}=\frac{2+1.5309+0.938}{3}\approx\frac{4.4689}{3}\approx1.4896. $$ 更新 $z$: $$ z^3 = \frac{4+y^2+x^3}{3}=\frac{4+(-0.938)+1.4896}{3}\approx\frac{4.5516}{3}\approx1.5172. $$ 更新 $y$: $$ y^3 = y^2+(x^3-z^3)\approx -0.938+(1.4896-1.5172)\approx -0.938-0.0276\approx -0.9656. $$ 从迭代过程可以看出: $x$ 和 $z$ 的值在不断调整,目标是使两者相等,从而满足约束。 最终随着迭代次数增加,$x$ 和 $z$ 会收敛到约 1.5,同时乘子 $y$ 收敛到 $-1$(这与 KKT 条件相符)。 应用领域 大规模优化 在大数据、机器学习中利用并行计算加速求解。 信号与图像处理 用于去噪、压缩感知等稀疏表示问题。 分布式计算 在多节点协同场景下求解大规模问题。 优点与局限性 优点 局限性 分布式计算能力 小规模问题可能收敛较慢 支持稀疏性和正则化 参数 $\rho$ 需精细调节 收敛性稳定 —
科研
zy123
1年前
0
14
0
2025-03-21
李雅普诺夫稳定性
李雅普诺夫方法 判断系统是否能够在受到扰动后返回平衡状态或维持在稳定状态。 数学基础 雅各比矩阵定义 雅可比矩阵(Jacobian matrix)是一个重要的数学概念,它在向量值函数的微分方面起着关键作用。雅可比矩阵描述了一个向量值函数的局部线性近似。 理解:从n维实向量空间到m维实向量空间的函数f,假设输入为2维,用x,y表示,即二维平面上的一个点;输出为3维,每个点的位置由坐标f1(x,y),f2(x,y),f3(x,y)表示。 求解雅各比矩阵: 状态空间 稳定性的定义 李雅普诺夫第一法(间接方法) 通过分析线性系统的系数矩阵的特征值来判断系统的稳定性 雅各比矩阵使我们能够将非线性系统在平衡点附近的行为近似为线性系统。通过这种局部线性化,我们可以应用线性系统理论来研究非线性系统的稳定性。 特征值的实部决定了系统在这些点附近是趋向平衡点还是远离平衡点。 所有特征值的实部都小于零意味着系统是渐进稳定的; 任何特征值的实部大于零意味着系统在该点是不稳定的。 如果所有特征值的实部都不大于零,并且存在实部正好为零的特征值,李一法失效。 why特征值??? 可以以对角矩阵为例,特征值为对角线上元素,设平衡点x1=0,x2=0; 基变换:将一个向量左乘特征向量矩阵V实际上是在将这个向量从原始坐标系转换到以A的特征向量为基的新坐标系。在新的坐标系中,原始向量的坐标表示由特征向量矩阵V 决定。 原始坐标系:y1、y2, 新坐标系:x1、x2 eg: 希尔维斯特判据 李雅普诺夫第二法(直接法) 关键是构造一个李雅普诺夫函数V(x) eg: 当使用李雅普诺夫的第二方法分析系统稳定性时,直接找到一个合适的李雅普诺夫函数可能很困难。 线性定常连续系统 $$ \dot = Ax $$ A为系统的状态矩阵,应用李雅普诺夫方程可构造李雅普诺夫函数。 eg: 非线性系统 $$ \dot = f(x) $$ 克拉索夫斯基算法 eg:
科研
zy123
1年前
0
20
0
上一页
1
...
6
7
8
...
12
下一页