首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
40 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
1年前
0
12
0
推荐
拼团交易系统
项目
1年前
0
41
1
推荐
Smile云图库
项目
1年前
0
60
0
热门文章
146 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
146
0
47 ℃
微服务
后端学习
1年前
0
47
0
43 ℃
苍穹外卖
项目
1年前
0
43
0
最新发布
2025-03-21
git基本操作
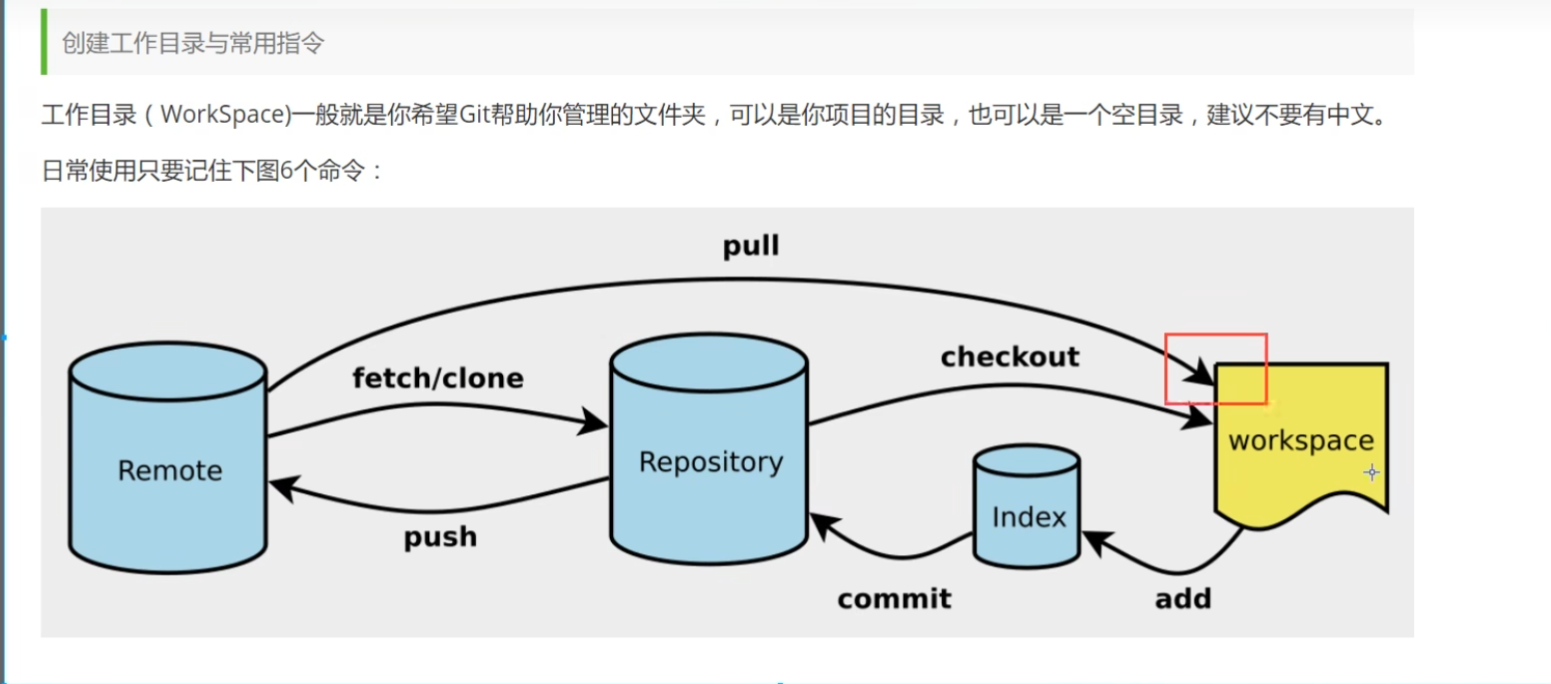
Git linux上安装Git sudo apt update sudo apt install git Git Bash:与linux风格接近,使用最多,推荐 Git CMD:windows风格 Git GUI:图形界面,不推荐 查看配置 git config -l :查看所有配置 git config --global --list 查看用户配置的 git config --system --list :系统配置的 核心原理 index是暂存区 respository 是本地代码仓库,保存着本地的各个版本代码 remote是远程仓库,通常是github/gitee码云 如何克隆别人已有的项目 获取项目地址http 打开本地文件系统,选择你需要保存项目的位置并打开cmd git clone xxx,这个过程可能需要验证身份,输入用户名密码 如何将本地仓库与远程仓库连接?从零开始 法1: 首先在Github上新建一个代码仓库,拷贝地址 eg:https://github.com/zhangww-web/JianShu.git 在你本地文件夹下鼠标右键git bash here git init 新建本地仓库,生成.git隐藏文件,点进去有head文件。 git remote add origin url,可以绑定远程仓库 继续输入git pull origin master(若你远程仓库为空,不需要这一步) git add .(.表示所有的,注意这个‘点’)—将本地文件提交至暂存区 git commit -m '提交信息' git push origin master 法2: 第2种方法比较简单,直接用把远程仓库拉到本地,然后再把自己本地的项目拷贝到仓库中去。然后push到远程仓库上去即可。要求远程仓库为新建的空仓库!!! 在空文件夹中git bash here(不用init!) 首先git clone https://github.com/zhangww-web/JianShu.git 然后复制自己项目的所有文件到刚刚克隆下来的仓库中 git push -u origin master 法3:在android studio中集成 配置Git 关联自己的github 对于任何安卓项目,前两步都是通用的!!! 这里的Remote填远程仓库地址,eg: https://github.com/zhangww-web/JianShu.git IDEA 方法类似,先init本地仓库, 点击顶部菜单栏的 Git -> Manage Remotes。 如果Share project on github一直失败,可以这样: 前面步骤不变,现在去github上新建一个空白仓库,获得一个remote url,然后本地仓库提交到该空白仓库,即可建立链接。 迁移代码仓库 法一(推荐):访问令牌(Access Token)获取:点击右上角头像,选择“Settings”(设置)。 在左侧菜单中找到“Developer settings”(开发者设置),然后点击“Personal access tokens”(个人访问令牌)。点击“Generate new token”(生成新令牌),按照需要选择相应的权限(通常建议勾选 repo、read:org 等,根据你的实际需求)。生成后将令牌复制下来,填入 Gitea 的迁移界面中。 直接推完整git信息,推荐 法二: 本地有完整的代码已经git提交记录,不想丢失,推送到新的远程仓库: 在本地文件夹下git bash here git remote add origin <新仓库地址> git push -u origin --all 注意:只会将你本地仓库已经 checkout 出来的所有分支(即本地存在的分支)推送到新远程仓库中。 Git 常用命令 提交代码 git add--> git commit --> git push git add . 提交所有文件到暂存区,此时git status显示changes to be commited git commit -m "describe描述性内容" 提交到本地仓库 分支操作 git banch -a 可以查看所有分支 git branch dev 可以新建dev分支 git checkout dev 可以切换到dev分支 git branch -d dev 删除dev分支 git branch -m dev cs :将dev分支修改名称为cs分支 Git配置代理 首先,科学上网一定能打开github的官网,但是idea中仍然无法push 此时查看你的代理服务器的端口,发现是7890 然后打开git bash,输入以下代码: 使用http代理 git config --global http.proxy http://127.0.0.1:7890 git config --global https.proxy https://127.0.0.1:7890 使用socks5代理 git config --global http.proxy socks5://127.0.0.1:7890 git config --global https.proxy socks5://127.0.0.1:7890 取消代理 git config --global --unset http.proxy git config --global --unset https.proxy 或者使用国产的gitee或者自己服务器上搭建gitea进行代码托管!!! 拉取代码与解决冲突 git pull 命令用于从远程仓库拉取(fetch)并合并(merge)最新的更改到本地仓库。它实际上执行了两个操作: git fetch: 这个操作会从远程仓库下载最新的更改到本地仓库,但不会自动合并到当前分支。它将远程仓库的更改存储在本地仓库中,使你能够查看它们,但不会更改你当前工作目录中的文件。 git merge: 这个操作将远程仓库的更改合并到当前分支。如果有冲突,你需要解决冲突后再次提交合并的结果 情况1:本地修改代码未提交,拉取代码的时候就会报错: 错误:您对下列文件的本地修改将被合并操作覆盖: docker-compose.yaml 请在合并前提交或贮藏您的修改。 正在终止 暂存未提交的更改(git stash) 如果还不想提交本地修改,可以将更改暂存起来: git stash git pull git stash pop git stash 会将当前工作区的改动保存到一个栈中,拉取完成后通过 git stash pop 恢复修改。如果恢复过程中出现冲突,同样需要手动解决。 舍弃本地修改 如果确定不需要这些修改,可以放弃它们: git reset --hard git pull 但是推荐先提交本地的代码!!! git add . git commit -m "描述本次修改的提交信息" git pull 情况2:权限校验问题 一般可以保持git网页端账号的登录状态,再pull,会有弹窗出来输入git的用户名和密码,成功后即可拉取。 情况3 合并冲突,以pycharm为例 1.触发冲突解决界面 当你执行 git pull 后如果出现冲突,PyCharm 会在右下角或版本控制工具窗口中提醒有冲突文件。你可以点击提示信息或在版本控制面板中找到冲突文件。 2.启动合并工具 双击冲突文件后,PyCharm 会自动打开三方合并工具。界面通常分为三部分: 左侧:本地修改(当前分支的更改) 右侧:远程修改(要合并进来的更改) 中间:合并结果(你需要编辑的区域) 3.手动选择并合并代码 在合并工具中,你可以逐个查看冲突部分: 点击左侧或右侧的按钮来选择保留哪部分内容。 如果需要,你也可以手动编辑中间的合并结果区域,直接输入合适的代码。 合并工具通常会有跳转到下一个冲突的按钮,方便你逐个解决。 4.保存合并结果并标记解决 合并完成后,点击工具窗口上的“Apply”或“Accept Merge”按钮,保存你的修改。此时,冲突文件会标记为已解决。 5.提交合并后的更改 返回主界面后,你可以在版本控制面板中看到已解决的文件。检查确认无误后,通过 VCS 菜单或直接点击工具栏中的提交按钮,将合并结果提交到仓库。 其他Git相关 SSH公私钥 公私钥生成 在linux中,使用账号密码链接github报错如下: remote: Support for password authentication was removed on August 13, 2021. remote: Please see https://docs.github.com/get-started/getting-started-with-git/about-remote-repositories#cloning-with-https-urls for information on currently recommended modes of authentication. 致命错误:'https://github.com/zhangww-web/reptile.git/' 鉴权失败 原因是linux不支持账号密码链接!! 配置ssh,可以在git push的时候直接推送,github会通过ssh来验证你的身份。 如何在linux中配置私钥? 生成 SSH 密钥: 如果你还没有 SSH 密钥,可以使用以下命令生成: ssh-keygen -t rsa -b 4096 -C "your_email@example.com" 按照提示保存密钥文件。 添加 SSH 密钥到 GitHub: 复制生成的公钥内容(通常在 ~/.ssh/id_rsa.pub 文件中)。 登录到 GitHub。 进入 SSH and GPG keys 页面。 点击 "New SSH key" 按钮,粘贴公钥内容并保存。 使用 SSH URL 克隆仓库: git clone git@github.com:zhangww-web/reptile.git SSH 连接 GitHub 并触发身份验证,流程如下: GitHub 发送一个随机挑战(Challenge) GitHub 服务器会向你的 Linux 服务器发送一个随机字符串,并用 你的公钥 进行加密。 你的 Linux 服务器用私钥解密 你的 SSH 客户端(ssh 命令或 git)会自动使用本地的 私钥(id_rsa) 进行解密。如果解密成功,证明你拥有匹配的私钥。 返回解密后的数据 你的客户端将解密后的数据返回给 GitHub。 GitHub 验证解密结果 GitHub 服务器检查解密结果是否匹配它最初发送的随机挑战。如果匹配,则认证成功。 身份验证逻辑:GitHub 发送加密数据 → 你的私钥解密 → 返回结果 → GitHub 确认一致性 → 认证成功。 如果避免每次git pull都要验证身份? git config --global credential.helper store //将凭据保存到磁盘上(明文存储): .gitignore(忽略某些文件) .gitignore 的生效规则 对未跟踪的文件: 被标记的文件会被忽略,不会出现在 Git 提交列表中(IDEA 中会显示为灰色或隐藏)。 对已跟踪的文件: 如果 application-local.yml 之前已经被 Git 跟踪过(即曾经提交过),.gitignore 不会自动将其从版本控制中移除。它仍会出现在提交列表中。 如果不小心commit了或者git add(暂存但未提交)如何撤销? 例:如果在添加.gitignore文件前不小心提交了.idea文件夹,到项目根目录,git bash here git rm -r --cached -f .idea git commit -m "Remove .idea from tracking" git rm:从版本控制中删除文件 -r:递归删除指定目录下的所有文件。 --cached:关键选项,指定操作只针对暂存区,不动工作目录 为什么.gitignore文件不放在.git文件夹中? 便于版本控制:.gitignore文件放在项目的根目录中,可以和项目代码一起被版本控制,这样其他协作开发者也能看到和使用相同的忽略规则。如果把.gitignore放在.git文件夹中,它就不会被版本控制系统追踪到。 撤销Git版本控制 1.直接把项目文件夹中的.git文件夹删除即可(开启查看隐藏文件夹可看到) 2:使用 Git 命令(保留文件,仅移除版本控制) git init # 重新初始化(可选,非必须) git rm -r --cached . # 移除所有文件的跟踪状态 添加协作者 协作者权限 如果不使用组织的话,你也可以单独为每个仓库添加协作者。这样做的话,公钥仍然应该添加到你的个人设置中,但是你可以在每个仓库的设置中单独管理协作者访问权限。 设置步骤包括: 打开你想要添加协作者的仓库。 导航到仓库设置中的“Manage access”(管理访问)或“Collaborators”(协作者)部分。 添加协作者的GitHub用户名,并设置他们的访问级别。
杂项
zy123
1年前
0
15
0
2025-03-21
linux服务器
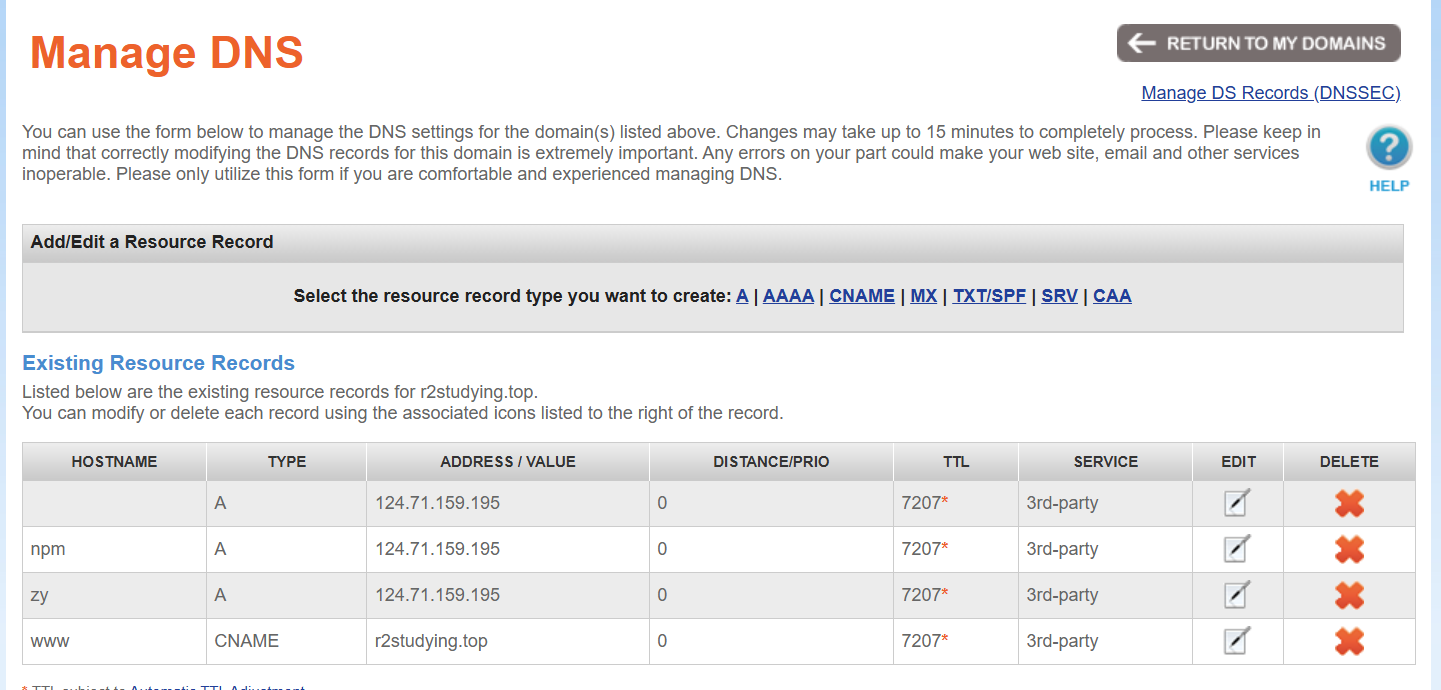
llinux服务器(以debian为例) 预先准备 域名购买与解析 购买:Low-Cost Domain Names & Hosting from $0.99 | NameSilo 教程:【服务器、域名购买】Namesilo优惠码和域名解析教程(附带服务器购买推荐和注意事项) | 爱玩实验室 DNS解析:可能需等待几分钟生效 买的域名的r2studying.top 这里的HOSTNAME相当于二级域名,如npm.r2studying.top 现改为CloudFlare来做DNS解析,不用namesilo,它有两种模式: Proxied(橙色云朵):当你将某个 DNS 记录设置为 Proxied 时,Cloudflare 会作为反向代理服务器处理该域名的 HTTP/HTTPS 流量。这样做有几个效果: 隐藏真实 IP:用户访问时看到的是 Cloudflare 的 Anycast IP,而不是你服务器的真实 IP,从而提高安全性。 提供 CDN 加速:Cloudflare 会缓存静态资源,并通过全球节点加速内容传输,提升网站响应速度。 附加安全防护:包括 DDoS 防护和 Web 应用防火墙等功能。 DNS Only(灰色云朵):如果你设置为 DNS Only,Cloudflare 只负责 DNS 解析,不会对流量进行代理或处理。也就是说,用户访问时会直接获取并连接到你服务器的真实 IP。 安全组设置 登录云服务器的控制台设置 入站规则 入站规则(Inbound Rules)是指防火墙中用来控制外部流量进入服务器的规则。通过这些规则,你可以指定允许或拒绝哪些类型的网络流量(例如特定协议、端口号、IP地址等)进入你的服务器。 类型 协议端口 源地址 描述 IPv4 TCP : 22 0.0.0.0/0 允许外部访问安全组内实例的SSH(22)端口,用于远程登录Linux实例。 IPv4 TCP : 3389 0.0.0.0/0 允许外部访问安全组内实例的RDP(3389)端口,用于远程登录Windows实例。 IPv4 TCP : 80 0.0.0.0/0 允许外部访问安全组内实例的HTTP(80)端口,用于通过HTTP协议访问网站。 IPv4 TCP : 443 0.0.0.0/0 允许外部访问安全组内实例的HTTPS(443)端口,用于通过HTTPS协议访问网站。 IPv4 TCP : 20-21 0.0.0.0/0 允许通过FTP上传和下载文件。 IPv4 ICMP: 全部 0.0.0.0/0 允许外部使用ping命令验证安全组内实例的网络连通性。 出站规则 出站规则(Outbound Rules)则是指控制服务器向外部发送流量的规则。你可以通过出站规则来限制服务器发出的数据包,比如限制服务器访问某些外部服务或 IP 地址。 凡是服务正常启动但是浏览器上无法访问的,都首先想想防火墙端口是否打开!!! 常用的命令 cat 用于查看文本文件的内容 head 查看前n行 head -n 100 文件名 tail 查看后n行 tail -n 3 file wc (word count )统计行数、单词数 Hello world Linux is great wc -l file #统计行数: 2 file wc -w file #统计单词数:5 file touch 新建文本文件,如touch /home/hello.py 将在home 文件夹下新建hello.py ls 列出所有文件,但默认只是显示出最基础的文件和文件夹,如果需要更详细的信息,则使用ls -la,这将列出包括隐藏文件在内的所有文件和文件夹,并且给出对应的权限、大小和日期等信息。 zy123@hcss-ecs-588d:~$ ls -la total 44 drwxr-xr-x 6 zy123 zy123 4096 Feb 26 08:53 . drwxr-xr-x 3 root root 4096 Feb 24 16:33 .. -rw------- 1 zy123 zy123 6317 Feb 25 19:41 .bash_history -rw-r--r-- 1 zy123 zy123 220 Feb 24 16:33 .bash_logout -rw-r--r-- 1 zy123 zy123 3526 Feb 24 16:33 .bashrc drwx------ 3 zy123 zy123 4096 Feb 24 16:35 .config drwxr-xr-x 3 zy123 zy123 4096 Feb 24 16:36 .local -rw-r--r-- 1 zy123 zy123 807 Feb 24 16:33 .profile drwxr-xr-x 5 zy123 zy123 4096 Feb 26 08:53 zbparse drwxr-xr-x 3 root root 4096 Feb 26 08:54 zbparse_output 权限与文件类型(第一列): 第一个字符表示文件类型: “d”表示目录(directory) “-”表示普通文件(regular file) “l”表示符号链接(symbolic link) 后续的9个字符分为3组,每组三个字符,分别代表所有者、所属组和其他用户的权限(读、写、执行)。 硬链接数(第二列): 表示指向该文件的硬链接数量。对于目录来说,这个数字通常会大于1,因为“.”和“..”也算在内。 所有者(第三列): 显示该文件或目录的拥有者用户名。 所属组(第四列): 显示该文件或目录所属的用户组。 文件大小(第五列): 以字节为单位显示文件的大小。对于目录,通常显示的是目录文件占用的磁盘空间(一般为4096字节)。 最后修改日期和时间(第六列): 显示文件最后一次修改的日期和时间(可能包含月、日和具体时间或年份)。 文件名或目录名(第七列): 显示文件或目录的名称。 cd 进入指定文件夹,如cd /home 将进入home目录。返回上层目录的命令是 cd .. ,返回刚才操作的目录的命令是 cd - mkdir 新建文件夹,如 mkdir /home/Python 将在home 文件夹下新建一个Python 文件夹。 mv 移动文件和文件夹,也可以用来重命名,如: mv /home/hello.py /home/helloworld.py 将上文的hello.py重命名为helloworld.py, mv /home/helloworld.py /home/Python/helloworld.py 将helloworld.py 由home文件夹移动到了次级的Python文件夹。 mv /home/hello.py . 将/home/hello.py 移动到当前目录下 cp 复制文件 cp /home/Python/hellowrold.py /home/Python/HelloWorld.py 将helloworld.py复制为HelloWolrd.py。注意:Linux系统严格区分大小写,helloworld.py和HelloWolrd.py是两个文件。 rm 删除,即江湖传说中 rm -rf ,r为递归,可以删除文件夹中的文件,f为强制删除。rm /home/Python/helloworld.py 可以删除刚才的helloworld.py 文件,而想删除包括Python 在内的所有文件,则是 rm -rf /home/Python 。 grep 是用于在文件或标准输入中搜索符合条件的行的命令。 #test.txt Hello World hello linux Grep is useful HELLO GREP # 精确匹配大小写 grep "Hello" test.txt 输出:Hello World -i忽略大小写 -n显示行号 # 忽略大小写匹配 grep -i "hello" test.txt 输出: Hello World hello linux HELLO GREP awk 是一个功能强大的文本处理工具,它可以对文本文件进行分列处理、模式匹配和报告生成。它的语法类似一种简单的脚本语言。 awk 'pattern { action }' filename pattern:用于匹配文本的条件(可以省略,默认对所有行生效)。 action:在匹配的行上执行的操作。 $0:代表整行内容$1+ $2+ $3+ ...。 $1, $2, ...:代表各个列(默认分隔符是空白字符,可以通过 -F 参数指定其他分隔符)。 对于: A B C 1 Alice 25 Engineer 2 Bob 30 Designer awk '{print $1, $3}' filename #印指定列 输出: Alice Engineer Bob Designer sed sed -n '1000,$p' file 对于 filename这个文件,请只打印从第1000行开始一直到文件末尾的所有内容。$代表结尾,p是print打印。 管道 | 是将一个命令的输出直接传递给另一个命令作为输入的一种机制。 示例:将 grep 与 awk 联合使用:假设有一个日志文件 access.log,需要先用 grep 过滤出包含 "ERROR" 的行,再用 awk 提取时间字段: 127.0.0.1 27/Feb/2025:10:30:25 "GET /index.html HTTP/1.1" 200 1024 192.168.1.1 27/Feb/2025:10:31:45 "POST /login HTTP/1.1" 302 512 10.0.0.5 27/Feb/2025:10:32:10 "GET /error_page HTTP/1.1" 500 2048 ERROR grep 'ERROR' access.log | awk '{print $2}' 输出:27/Feb/2025:10:32:10 usermode 修改用户账户信息的命令 sudo usermod -aG docker zy123 #-aG一起用,添加zy123到group组 chmod 命令用于修改文件或目录的权限 数字方式:数字方式使用三个(或四个)数字来表示所有者、组用户和其他用户的权限。每个数字代表读 (4)、写 (2)、执行 (1) 权限的和。 chmod 644 filename #所有者:读 + 写 = 6 组用户:读 = 4 其他用户:读 = 4 符号方式 chmod [用户类别][操作符][权限] filename 用户类别: u:所有者(user) g:组用户(group) o:其他用户(others) a:所有用户(all),等同于 u+g+o 操作符: +:增加权限 -:去掉权限 =:直接设置权限 权限: r:读权限 w:写权限 x:执行权限 chmod u+x filename #为所有者增加执行权限 系统分析 df -h 查看磁盘空间使用情况 lsof"List Open Files"显示系统中当前打开的文件。 -i会显示所有正在使用网络连接的进程 lsof -i :80 #查看 80 端口上的进程,或者判断80端口是否被占用! netstat -ano | findstr :8080这是windows cmd下检查端口占用的命令 top 用于实时查看系统进程和资源占用情况。(CPU、内存、PID、用户等)。 top -p <pid> 只监控某个进程。 交互操作(进入 top 后按键):P → 按 CPU 占用率排序;M → 按 内存占用率排序 q → 退出 ps 用于查看当前系统中的进程快照。 ps -ef 查看所有进程的详细信息(常用)。 ps -aux 以 BSD 风格显示进程(带 CPU、内存占用率)。 ps -u <username> 查看某个用户的进程。 ps -p <pid> 查看某个进程的详细信息。 文本编辑器 nano:Debian 11自带了简便易用的nano文本编辑器 nano /etc/apt/sources.list #打开sources.list文件 Ctrl+O:保存修改 ->弹出询问-> Y则保存,N则不保存,ctrl+c 取消操作。 Ctrl+X:退出 vim 普通模式(Normal Mode): 打开 Vim 后默认进入普通模式。在该模式下,可以执行移动光标、删除、复制、粘贴等命令。 光标移动: 0:跳到当前行行首 $:跳到当前行行尾 gg: 将光标移到文件开头 文本操作: dd:删除(剪切)整行 yy:复制(拷贝)整行 p:在光标后粘贴(把剪切或复制的内容贴上) u:撤销上一步操作 Ctrl + r:重做上一步撤销的操作 插入模式(Insert Mode): 在普通模式下按 i、I、a、A 等键可进入插入模式,此时可以像普通编辑器那样输入文本。 按 ESC 键退出插入模式,返回普通模式。 可视模式(Visual Mode): 用于选中一段文本,自动进入可视模式。选中文本后可以进行复制、剪切等操作。 在可视模式下选中后按 d 删除 按 y 复制选中区域 命令行模式(Command-Line Mode): 在普通模式下,输入 : 进入命令行模式,可以执行保存、退出、查找等命令。 :w:保存当前文件 :q:退出 Vim(如果有未保存的修改会警告) :wq 或 :x:保存文件并退出 :q!:不保存强制退出 :set number:显示行号 :set paste:适用于代码或格式敏感的文本,确保粘贴操作不会破坏原有的布局和缩进。 :%d: 删除全文 抓包 sudo tcpdump -nn -i any port 1000 //查看请求端口1000的源 IP 地址 SSH 1. 生成密钥对 使用以下命令生成安全的 SSH 密钥对: ssh-keygen -t rsa -b 4096 -C "your_email@example.com" 生成的文件默认保存在用户主目录的 ~/.ssh/文件夹中: 私钥 (id_rsa):必须妥善保存在本地,严禁泄露。这是证明身份的核心凭证。 公钥 (id_rsa.pub):需要提供给服务端用于身份验证。 2. 核心概念:理解客户端与服务端 SSH 认证是双向的,关键在于分清每次连接中谁是客户端(主动发起连接的一方),谁是服务端(被动接受连接的一方)。 场景一:从服务器拉取 GitHub 代码 角色分配 客户端:你的 Linux 服务器(执行 git clone/push命令的机器) 服务端:GitHub 代码托管平台 认证流程 在客户端(你的服务器)生成 SSH 密钥对 将客户端的公钥内容添加到 GitHub 账户的 SSH Keys 设置中 当服务器执行 git clone git@github.com:...时: GitHub 会用存储的公钥发起挑战 你的服务器用本地私钥完成验证 本质:让你的服务器向 GitHub 证明其合法身份 场景二:通过 FinalShell 连接 Linux 服务器 角色分配 客户端:你的本地 Windows 电脑(运行 FinalShell 的机器) 服务端:目标 Linux 服务器 认证流程 在客户端(你的电脑)生成 SSH 密钥对 将客户端的公钥内容添加到服务端的 ~/.ssh/authorized_keys文件中 当 FinalShell 连接时: Linux 服务器用 authorized_keys中的公钥发起挑战 FinalShell 用本地私钥完成验证 本质:让你的电脑向 Linux 服务器证明你的用户身份 文件系统 在 Linux 系统中,整个文件系统从根目录 / 开始,下面简单介绍一些主要目录及其存放的文件类型: /bin 存放系统启动和运行时必需的用户二进制可执行文件,如常用的 shell 命令(例如 ls、cp、mv 等)。 /boot 包含启动加载器(如 GRUB)的配置文件和内核映像(kernel image),这些文件用于系统启动过程。 /dev 包含设备文件,这些文件代表系统中的各种硬件设备(例如硬盘、终端、USB 设备等),以及一些伪设备。 /etc 存放系统范围内的配置文件,例如网络配置、用户账户信息、服务配置等。这些文件通常由管理员维护。 /home 为普通用户提供的家目录,每个用户在这里有一个独立的子目录,存放个人文件和配置。 /lib 和 /lib64 存放系统和应用程序所需的共享库文件,这些库支持 /bin、/sbin 及其他程序的运行。 /media 通常用于挂载移动介质,如光盘、U 盘或其他可移动存储设备。 /mnt 提供一个临时挂载点,一般供系统管理员在需要手动挂载文件系统时使用。 /opt 用于安装附加的应用程序软件包,通常是第三方提供的独立软件,不与系统核心软件混合。 /proc 这是一个虚拟文件系统,提供内核和进程信息,例如系统资源使用情况、硬件信息、内核参数等。这里的文件不占用实际磁盘空间。 /root 系统管理员(root 用户)的家目录,与普通用户的 /home 分开存放。 /run 存储系统启动后运行时产生的临时数据,比如 PID 文件、锁文件等,系统重启后会清空该目录。 /sbin 存放系统管理和维护所需的二进制文件(系统级命令),例如网络配置、磁盘管理工具等,这些通常只由 root 用户使用。 /srv 用于存放由系统提供的服务数据,如 FTP、HTTP 服务的数据目录等。 /tmp 用于存放临时文件,许多应用程序在运行时会将临时数据写入这里,系统重启后通常会清空该目录。 /usr 存放大量用户应用程序和共享资源,其子目录包括: /usr/bin:大部分用户命令和应用程序。 /usr/sbin:非基本系统维护工具,主要供系统管理员使用。 /usr/lib:程序库文件。 /usr/share:共享数据,如文档、图标、配置样本等。 /var 存放经常变化的数据,如日志文件、缓存、邮件、打印队列和临时应用数据等。 Bash #!/bin/bash # 定义变量,注意等号两边不能有空格 name="World" # 如果脚本传入了参数,则使用第一个参数覆盖默认值 if [ $# -ge 1 ]; then # $# 表示传入脚本的参数个数 name=$1 # $1 表示第一个参数。 fi # 输出问候语 echo "Hello, $name!" #变量引用时要用 $ 符号,如 $name。 # 循环示例:遍历1到5的数字 for i in {1..5}; do echo "当前数字:$i" done # 定义一个函数,函数名为greet greet() { echo "函数内问候: Hello, $1!" } # 调用函数,并传入变量name作为参数 greet $name 如何运行? 赋予可执行权限 chmod +x hello_world.sh 执行 ./hello_world.sh 或者 ./hello_world.sh Alice #传参 在 Linux 系统中,默认情况下当前目录(.)并不包含在 PATH 环境变量中。这意味着,如果你在终端中直接输入脚本名(例如 hello_world.sh),系统不会在当前目录下查找这个脚本,而是只在 PATH 中指定的目录中查找可执行程序。使用 ./hello_world.sh 表示“在当前目录下执行 hello_world.sh”,从而告诉系统正确的路径。 如何设置定时任务? sudo crontab -e #在里面添加: 10 0 * * * /path/toyour/xx.sh #让gpt写 反向代理神器——Nginx Proxy Manager 【Docker系列】一个反向代理神器——Nginx Proxy Manager-我不是咕咕鸽 概念 正向代理是代理客户端的行为,即代理服务器代表客户端向目标服务器发出请求。客户端将自己的请求先发送给代理服务器,由代理服务器转发给真正的目标服务器,然后再将返回结果传递给客户端。 特点: 保护访问者(客户端)的信息:目标服务器只会看到代理服务器的请求,无法直接获知真正发起请求的客户端是谁。 应用场景:当客户端出于隐私、访问控制或跨越网络限制的目的,需要隐藏自己的真实IP或身份时,会使用正向代理。 反向代理是代理服务器代表目标服务器接收客户端请求,并将请求转发给内部的真实服务器,然后将结果返回给客户端。客户端只与代理服务器通信,而不知道背后实际处理请求的服务器。 特点: 保护服务器端的信息:客户端看不到真正的服务器细节,只知道代理服务器。这样可以隐藏真实服务器的 IP 和其他内部结构信息,从而增强安全性和负载均衡等功能。 应用场景:在大型网站或应用中,为了防止恶意攻击或实现负载均衡,通常会在真实服务器前部署一个反向代理服务器。 docker 部署 version: '3' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' # 保持默认即可,不建议修改左侧的80 - '81:81' # 冒号左边可以改成自己服务器未被占用的端口 - '443:443' # 保持默认即可,不建议修改左侧的443 volumes: - ./data:/data # 冒号左边可以改路径,现在是表示把数据存放在在当前文件夹下的 data 文件夹中 - ./letsencrypt:/etc/letsencrypt # 冒号左边可以改路径,现在是表示把数据存放在在当前文件夹下的 letsencrypt 文件夹中 NPM后台管理网站运行在81号端口,NPM服务本身监听80(http)和443(https)端口 工作原理 用户访问网站(80/443端口) 当用户访问 https://blog.test.com 时,请求到达服务器的443端口。 Nginx根据域名匹配代理规则(由NPM配置),将请求转发到后端服务(如 192.168.1.100:8080)。 管理员访问后台(81端口) 管理员通过 http://服务器IP:81 访问NPM管理界面,配置代理规则。 配置完成后,NPM会自动生成Nginx配置文件并重启Nginx服务,使新规则生效。 两种方法实现SSL安全连接 1. 开启橙云+Cloudflare Origin CA:网站SSL证书自动续期又又又失败了?试试CloudFlare的免费证书,15年有效期!-我不是咕咕鸽 cloudflare解析DNS,开启橙云 Cloudflare Full (strict)模式(灵活模式下无需以下步骤) 在 Nginx Proxy Manager(NPM)添加 Cloudflare Origin CA 配置 Proxy Host 使其使用 选择刚刚添加的 Cloudflare Origin CA 证书 选择 Force SSL(强制 HTTPS) 启用 HTTP/2 支持 Cloudflare Origin CA作用:实现cloudflare与源服务器之间的流量加密 2.通配符SSL证书:【Docker系列】反向代理神器NginxProxyManager——通配符SSL证书申请-我不是咕咕鸽 更推荐第二种!!!目前正在使用,但是3个月续签一次证书! 浏览器 → (HTTPS) → NPM → (HTTP 或 HTTPS) → Gitea 这就是反向代理常见的工作流程。 默认经常是 NPM 做 SSL 终止(内网用 HTTP 转发给 Gitea)。如果你想内外全程加密,就要让 NPM -> Gitea 这段也走 HTTPS,并在 Gitea 上正确配置证书。 正向代理(用于拉取镜像) 下载Clash客户端:Release Clash-Premium · DustinWin/proxy-tools 或者Index of /Linux/centOS/ 我是windows上下载clashpremium-release-linux-amd64.tar.gz 然后FTP上传到linux服务器上。 下载配置文件config.yaml:每个人独一无二的 wget -O /home/zy123/VPN/config.yaml "https://illo1.no-mad-world.club/link/2zXAEzExPjAi6xij?clash=3" 类似这样: port: 7890 socks-port: 7891 allow-lan: false mode: Rule //Global log-level: info external-controller: 0.0.0.0:9090 unified-delay: true hosts: time.facebook.com: 17.253.84.125 time.android.com: 17.253.84.125 dns: enable: true use-hosts: true nameserver: - 119.29.29.29 - 223.5.5.5 - 223.6.6.6 - tcp://223.5.5.5 - tcp://223.6.6.6 - tls://dns.google:853 - tls://8.8.8.8:853 - tls://8.8.4.4:853 - tls://dns.alidns.com - tls://223.5.5.5 - tls://223.6.6.6 - tls://dot.pub - tls://1.12.12.12 - tls://120.53.53.53 - https://dns.google/dns-query - https://8.8.8.8/dns-query - https://8.8.4.4/dns-query - https://dns.alidns.com/dns-query - https://223.5.5.5/dns-query - https://223.6.6.6/dns-query - https://doh.pub/dns-query - https://1.12.12.12/dns-query - https://120.53.53.53/dns-query default-nameserver: - 119.29.29.29 - 223.5.5.5 - 223.6.6.6 - tcp://119.29.29.29 - tcp://223.5.5.5 - tcp://223.6.6.6 proxies: - {name: 🇭🇰 香港Y01, server: qvhh1-g03.hk01-ae5.entry.v50307shvkaa.art, port: 19273, type: ss, cipher: aes-256-gcm, password: 6e4124c4-456e-36a3-b144-c0e1a618d04c, udp: true} 注意,魔戒vpn给的是一个订阅地址!!!还需要解码 简便方法:windows上将订阅链接导入,自动解析成yaml配置文件,然后直接把该文件传到服务器上! 启动Clash ./CrashCore -d . & //后台启动 为Clash创建服务 1.创建 systemd 服务文件 sudo vim /etc/systemd/system/clash.service 2.在文件中添加以下内容: [Unit] Description=Clash Proxy Service After=network.target [Service] ExecStart=/home/zy123/VPN/CrashCore -d /home/zy123/VPN WorkingDirectory=/home/zy123/VPN Restart=always User=zy123 Group=zy123 [Install] WantedBy=multi-user.target 这段配置将 Clash 配置为: 在网络服务启动后运行。 在启动时自动进入后台,执行 CrashCore 服务。 如果服务意外停止,它将自动重启。 以 zy123 用户身份运行 Clash。 启动服务: sudo systemctl start clash 停止服务: sudo systemctl stop clash 查看服务状态: sudo systemctl status clash 配置YACD YACD 是一个基于 Clash 的 Web 管理面板,用于管理您的 Clash 配置、查看流量和节点信息等。 直接用现成的:https://yacd.haishan.me/ 服务器上部署:目前是npm手动构建安装启动的。 下载yacd git clone https://github.com/haishanh/yacd.git 安装npm 构建yacd cd ~/VPN/yacd pnpm install pnpm build 启动yacd nohup pnpm serve --host 0.0.0.0 & //如果不是0.0.0.0 不能在windows上打开 停止进程 ps aux | grep pnpm kill xxx 通过http://124.71.159.195:4173/ 访问yacd控制面板。手动添加crash服务所在的ip:端口。 如果连不上:yacd面板和crash都是http协议就行了。 连接测试 直连: curl -v https://www.google.com 使用代理:curl -x http://127.0.0.1:7890 https://www.google.com File Browser 文件分享 https://github.com/filebrowser/filebrowser Docker 部署 File Browser 文件管理系统_filebrowser docker-CSDN博客 1.创建数据目录 mkdir -p /data/filebrowser/{srv,config,db} 2.目录授权 chmod -R 777 /data/filebrowser/ 3.编辑 docker-compose.yaml 文件 version: '3' services: filebrowser: image: filebrowser/filebrowser:s6 container_name: filebrowser restart: always ports: - "2000:80" # 将容器的80端口映射到宿主机2000端口 volumes: - /data/filebrowser/srv:/srv #保存用户上传的文件 - /data/filebrowser/config:/config # 配置文件存储路径 - /data/filebrowser/db:/database #数据库存储路径 调用API实现文件上传与下载 登录: # 登录 → 获取 JWT token(原始字符串) curl -X POST "yourdomain/api/login" \ -H "Content-Type: application/json" \ -d '{ "username": "admin", "password": "123456" }' 响应: "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9…" //jwt令牌 上传: # 先把 token 保存到环境变量(假设你已经执行过 /api/login 并拿到了 JWT) export TOKEN="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9…" # 定义要上传的本地文件和目标名称 FILE_PATH="/path/to/local/photo.jpg" OBJECT_NAME="photo.jpg" # 对远程路径做 URL 编码(保留斜杠) REMOTE_PATH="store/${OBJECT_NAME}" ENCODED_PATH=$(printf "%s" "${REMOTE_PATH}" \ | jq -sRr @uri \ | sed 's/%2F/\//g') # 发起上传请求(raw body 模式) curl -v -X POST "https://yourdomain/api/resources/${ENCODED_PATH}?override=true" \ -H "X-Auth: ${TOKEN}" \ -H "Content-Type: image/jpeg" \ # 根据文件后缀改成 image/png 等 --data-binary "@${FILE_PATH}" 获取分享链接url: # 假设已经执行过 /api/login 并把 JWT 保存在环境变量 TOKEN # 同样复用之前算好的 ENCODED_PATH 和 REMOTE_PATH # 调用分享接口(注意:POST,body 为空 JSON "{}") curl -s -X POST "https://yourdomain/api/share/${ENCODED_PATH}" \ -H "X-Auth: ${TOKEN}" \ -H "Cookie: auth=${TOKEN}" \ -H "Content-Type: text/plain;charset=UTF-8" \ -d '{}' \ | jq -r '.hash' \ | xargs -I{} printf "https://yourdomain/api/public/dl/%s/%s\n" {} "${REMOTE_PATH}" Gitea Gitea Docker 安装与使用详解:轻量级自托管 Git 服务教程-CSDN博客 version: "3" services: gitea: image: gitea/gitea:latest container_name: gitea environment: - USER_UID=1000 - USER_GID=1000 restart: always ports: - "3000:3000" # 将宿主机的3000端口映射到容器的3000端口 volumes: - /data/gitea:/data # 持久化存储Gitea数据(包括仓库、配置、日志等) EasyImage 【好玩儿的Docker项目】10分钟搭建一个简单图床——Easyimage-我不是咕咕鸽 github地址:icret/EasyImages2.0: 简单图床 - 一款功能强大无数据库的图床 2.0版 sudo -i # 切换到root用户 apt update -y # 升级packages apt install wget curl sudo vim git # Debian系统比较干净,安装常用的软件 version: '3.3' services: easyimage: image: ddsderek/easyimage:latest container_name: easyimage ports: - '1000:80' environment: - TZ=Asia/Shanghai - PUID=1000 - PGID=1000 volumes: - '/root/data/docker_data/easyimage/config:/app/web/config' - '/root/data/docker_data/easyimage/i:/app/web/i' restart: unless-stopped 网页打开显示bug: cd /data/easyimage/config/config.php 这里添加上https 网站域名 图片域名设置可以改变图片的url:IP或域名 picgo安装: Releases · Molunerfinn/PicGo 1.右下角小窗打开 2.插件设置,搜索web-uploader 1.1.1 (自定义web图床) 旧版有搜索不出来的情况!建议直接安装最新版! 3.配置如下,API地址从easyimage-设置-API设置中获取 typora设置 左上角文件-偏好设置-图像-插入图片时{ 上传图片-picgo服务器-填写picgo安装路径 } ps:还可以选择上传到./assets,每个md文件独立 或者上传到指定路径如/image,多个md文件共享 py脚本1:将所有md文件中的图片路径改为本地,统一保存到本地output文件夹中 py脚本2:将每个md文件及其所需图片单独保存,保存到本地,但每个md文件有自己独立的assets文件夹 py脚本3:将本地图片上传到easyimage图床并将链接返回替换md文件中的本地路径 Typecho 【好玩儿的Docker项目】10分钟搭建一个Typecho博客|太破口!念念不忘,必有回响!-我不是咕咕鸽 typecho:https://github.com/typecho/typecho/ 注意:nginx一定要对typecho目录有操作权限! sudo chmod 755 -R ./typecho services: nginx: image: nginx ports: - "4000:80" # 左边可以改成任意没使用的端口 restart: always environment: - TZ=Asia/Shanghai volumes: - ./typecho:/var/www/html - ./nginx:/etc/nginx/conf.d - ./logs:/var/log/nginx depends_on: - php networks: - web php: build: php restart: always expose: - "9000" # 不暴露公网,故没有写9000:9000 volumes: - ./typecho:/var/www/html environment: - TZ=Asia/Shanghai depends_on: - mysql networks: - web pyapp: build: ./markdown_operation # Dockerfile所在的目录 restart: "no" networks: - web env_file: - .env depends_on: - mysql mysql: image: mysql:5.7 restart: always environment: - TZ=Asia/Shanghai expose: - "3306" # 不暴露公网,故没有写3306:3306 volumes: - ./mysql/data:/var/lib/mysql - ./mysql/logs:/var/log/mysql - ./mysql/conf:/etc/mysql/conf.d env_file: - mysql.env networks: - web networks: web: 卸载: sudo -i # 切换到root cd /root/data/docker_data/typecho # 进入docker-compose所在的文件夹 docker-compose down # 停止容器,此时不会删除映射到本地的数据 cd ~ rm -rf /root/data/docker_data/typecho # 完全删除映射到本地的数据 主题 Joe主题:https://github.com/HaoOuBa/Joe Joe再续前缘主题 - 搭建本站同款网站 - 易航博客 自定义文章详情页的上方信息(如更新日期/文章字数第): /typecho/usr/themes/Joe/functions.php中定义art_count,统计字数(粗略)。 原始 Markdown → [1] 删除代码块/行内代码/图片/链接标记/标题列表标记/强调符号 → [2] strip_tags() + html_entity_decode() → [3] 正则保留 “文字+数字+标点”,去除其它 → 结果用 mb_strlen() 得到最终字数 typecho/usr/themes/Joe/module/single/batten.php <?php if (!defined('__TYPECHO_ROOT_DIR__')) { http_response_code(404); exit; } ?> <h1 class="joe_detail__title"><?php $this->title() ?></h1> <div class="joe_detail__count"> <div class="joe_detail__count-information"> <a href="<?php $this->author->permalink(); ?>"> <img width="38" height="38" class="avatar lazyload" src="<?php joe\getAvatarLazyload(); ?>" data-src="<?php joe\getAvatarByMail($this->author->mail) ?>" alt="<?php $this->author(); ?>" /> </a> <div class="meta ml10"> <div class="author"> <a class="link" href="<?php $this->author->permalink(); ?>" title="<?php $this->author(); ?>"><?php $this->author(); ?></a> </div> <div class="item"> <span class="text"> <?php echo $this->date('Y-m-d'); ?> / <?php $this->commentsNum('%d'); ?> 评论 / <?php echo joe\getAgree($this); ?> 点赞 / <?php echo joe\getViews($this); ?> 阅读 / <?php echo art_count($this->cid); ?> 字 </span> </div> </div> </div> </div> <div class="relative" style="padding-right: 40px;"> <i class="line-form-line"></i> <!-- 新增最近修改日期显示 --> <div style="font-size: 1.0em; position: absolute; right: 20px; top: 50%; transform: translateY(-50%);"> 最后更新于 <?php echo date('m-d', $this->modified); ?> </div> <div class="flex ac single-metabox abs-right"> <div class="post-metas"> <!-- 原图标及其他冗余信息已删除 --> </div> <div class="clearfix ml6"> <!-- 编辑文章/页面链接已删除 --> </div> </div> </div> 修改代码块背景色: typecho/usr/themes/Joe/assets/css/joe.global.css .joe_detail__article code:not([class]) { border-radius: var(--radius-inner, 4px); /* 可以设置一个默认值 */ background: #f5f5f5; /* 稍微偏灰的背景色 */ color: #000000; /* 黑色字体 */ padding: 2px 6px; /* 内边距可以适当增大 */ font-family: "SFMono-Regular", Consolas, "Liberation Mono", Menlo, Courier, monospace; word-break: break-word; font-weight: normal; -webkit-text-size-adjust: 100%; -webkit-font-smoothing: antialiased; white-space: pre-wrap; /* 保持代码换行 */ font-size: 0.875em; margin-inline-start: 0.25em; margin-inline-end: 0.25em; } 大坑: 会显示为勾选框,无法正常进行latex公式解析,因为typecho/usr/themes/Joe/public/short.php中设置了短代码替换,在文章输出前对 $content 中的特定标记或短代码进行搜索和替换,从而实现一系列自定义功能。现已全部注释。 typecho/usr/themes/Joe/assets/js/joe.single.js原版: 显示弹窗,点叉后消失 { document.querySelector('.joe_detail__article').addEventListener('copy', () => { autolog.log(`本文版权属于 ${Joe.options.title} 转载请标明出处!`, 'warn', false); }); } 显示5秒后消失: document.querySelector('.joe_detail__article').addEventListener('copy', () => { // 显示 autolog 消息 autolog.log(`本文版权属于 ${Joe.options.title} 转载请标明出处!`, 'warn', false); // 5 秒后删除该消息 setTimeout(() => { const warnElem = document.querySelector('.autolog-warn'); if (warnElem) { warnElem.remove(); // 或者使用 warnElem.style.display = 'none'; } }, 5000); }); markdown编辑与解析 确保代码块```后面紧跟着语言,如```java,否则无法正确显示。 markdown编辑器插件:https://xiamp.net/archives/aaeditor-is-another-typecho-editor-plugin.html '开启公式解析!' markdown解析器插件:mrgeneralgoo/typecho-markdown: A markdown parse plugin for typecho. 关闭公式解析,仅开启代码解析! slug为页面缩略名,在新增文章时可以传入,默认是index数字。 qBittorrent 【好玩的Docker项目】10分钟搭建你专属的下载神器——qbittorrent-我不是咕咕鸽 docker pull linuxserver/qbittorrent cd ~ mkdir /root/data/docker_data/qBittorrent #创建qbitorrent数据文件夹 cd /root/data/docker_data/qBittorrent mkdir config downloads #创建配置文件目录与下载目录 nano docker-compose.yml #创建并编辑文件 services: qbittorrent: image: linuxserver/qbittorrent container_name: qbittorrent environment: - PUID=1000 - PGID=1000 - TZ=Asia/Shanghai # 你的时区 - UMASK_SET=022 - WEBUI_PORT=8081 # 将此处修改成你欲使用的 WEB 管理平台端口 volumes: - ./config:/config # 绝对路径请修改为自己的config文件夹 - ./downloads:/downloads # 绝对路径请修改为自己的downloads文件夹 ports: # 要使用的映射下载端口与内部下载端口,可保持默认,安装完成后在管理页面仍然可以改成其他端口。 - 6881:6881 - 6881:6881/udp # 此处WEB UI 目标端口与内部端口务必保证相同,见问题1 - 8081:8081 restart: unless-stopped 有个bug!qBittorrent 登录遇到 unauthorized的解决方法: 1、先停止容器docker compose down 2、进入配置文件夹config,编辑qBittorrent.conf在文末加上: WebUI\HostHeaderValidation=false WebUI\CSRFProtection=false 3.如果还是进不去,在地址后端添加'/' 内网穿透 使用服务提供商 网址:https://natapp.cn 1.隧道查看 2.隧道配置 配置映射关系: 3.客户端下载与配置 https://natapp.cn/#download ,参考官方文档,配置本地token,启动本地客户端。 自己搭建FRP 数据流转流程 外部请求到达 frp-server 你在 frps.ini(服务端配置)里为某个 proxy 分配了一个 remote_port(或 custom_domains)。 当外部用户(浏览器、移动端、其他服务)访问 http://your.frps.ip:remote_port/... 时,流量首先打到你部署在公网的 frp-server 上。 frp-server 转发到 frp-client frp-server 维护着一个与每个 frp-client 的长连接(control connection)。 收到外部连接后,frp-server 会基于这个 control 通道告诉对应的 frp-client: “有一个新连接,请你去拿 proxy(name) 对应的后端服务数据。” frp-server 不自己去连 Java 后端,它只是做信令和数据的“管道”管理。 frp-client 建立到本地 Java 服务的连接 frp-client 收到信令后,内部根据 proxies 配置: [[proxies]] name = "my-java-app" type = "tcp" local_ip = "127.0.0.1" local_port = 8080 remote_port= 18080 它会在容器或宿主机内部打开一个新的 TCP 连接,指向 127.0.0.1:8080(即你的 Java 服务) frp-server frps.toml: # https://github.com/fatedier/frp/blob/dev/conf/frps_full_example.toml [common] # 监听端口 bind_port = 7000 # 面板端口 dashboard_port = 7500 # 登录面板的账号密码(修改成自己的) dashboard_user = admin dashboard_pwd = admin # token = docker-compose: version: '3.9' services: frps: image: fatedier/frps:v0.60.0 hostname: frps container_name: frps volumes: - "./config/frps.toml:/frps.toml" command: - "-c" - "/frps.toml" network_mode: "host" frp-client frpc.toml: # 服务端地址 https://github.com/fatedier/frp/blob/dev/conf/frpc_full_example.toml serverAddr = "124.71.159.195" # 服务端配置的bindPort serverPort = 7000 # token = [[proxies]] # 代理应用名称,根据自己需要进行配置 name = "smile-dev-tech-01" # 代理类型 有tcp\udp\stcp\p2p type = "tcp" # 客户端代理应用IP localIP = "host.docker.internal" # 客户端代理应用端口 localPort = 8234 # 服务端反向代理端口;提供给外部访问 remotePort = 8234 [[proxies]] # 代理应用名称,根据自己需要进行配置 name = "smile-dev-tech-02" # 代理类型 有tcp\udp\stcp\p2p type = "tcp" # 客户端代理应用IP localIP = "host.docker.internal" # 客户端代理应用端口 localPort = 9001 # 服务端反向代理端口;提供给外部访问 remotePort = 9001 docker-compose: # 命令执行 docker-compose -f docker-compose.yml up -d version: '3.9' services: frpc: image: fatedier/frpc:v0.60.0 hostname: frpc container_name: frpc volumes: - "./config/frpc.toml:/frpc.toml" command: - "-c" - "/frpc.toml" network_mode: "host" frp-server必须部署在有公网ip的服务器,frp-client客户端有两种部署方式: 1.docker部署,如上 2.下载windows客户端https://github.com/fatedier/frp/releases/tag/v0.60.0 **注意:**如果java后端和client都部署在docker同一网络中,frpc.toml 中 localIP = "localhost" 如果client在docker容器,java在idea中启动,那么 localIP = "host.docker.internal" 如果client在windows下启动,java在idea中启动, localIP = "localhost" 总之,关键是让client和java互通;client和server互通比较容易!!! 公网ip:7500 可以查看面板。
杂项
zy123
1年前
0
10
0
2025-03-15
欢迎使用 Typecho
如果您看到这篇文章,表示您的 blog 已经安装成功.
默认分类
zy123
1年前
1
14
0
上一页
1
...
11
12