首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
40 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
7
篇与
项目
相关的结果
2025-08-19
RAG知识库
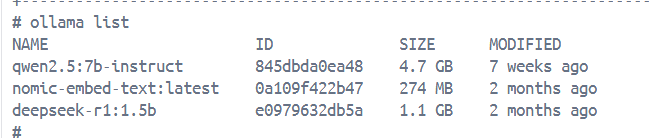
Spring AI + Ollama 1. Ollama 定位:本地/容器化的 大模型推理服务引擎 作用:负责加载模型、执行推理、返回结果 支持的模型:Qwen、DeepSeek、nomic-embed-text(embedding 模型)等 交互方式:REST API(默认 http://localhost:11434) ollama run qwen2.5:7b-instruct 2. Spring AI 定位:Spring 官方推出的 AI 接入框架 作用:统一封装对各种 AI 服务的调用逻辑,让开发者更容易接入(OpenAI、Ollama 等) 关键点 OllamaChatModel:封装了调用 Ollama 的对话接口 OllamaOptions:指定模型、参数(温度、上下文大小等) PgVectorStore:对接向量数据库(Spring AI 提供的默认向量数据库适配器。) TokenTextSplitter:默认的文本切分器 (Spring AI 内置逻辑) 3.pgVectorStore pgVectorStore 是 Spring AI 提供的向量存储接口实现,底层基于 PostgreSQL + pgvector 插件。它在项目中的作用: 1)存储向量和元数据: pgVectorStore.accept(splits); 这行代码会: 1.将 splits 中每个 Document 的 text → 调用 embedding 模型 → 生成向量 2.将生成的向量、原始文本、以及文档元数据统一存入数据库表(默认表名:vector_store); embedding:存储生成的向量; content:存储原始文本内容; metadata:以 JSONB 形式存储元数据。 2)检索时自动生成 SQL: List<Document> documents = pgVectorStore.similaritySearch(request); 在执行检索时,pgVectorStore 会自动生成 SQL 查询, 解析查询请求中的文本; 生成查询向量; 自动构造 SQL(结合 pgvector 的 <-> 向量相似度运算符); 按相似度排序返回最相关的文档列表。 进一步地,结合 filterExpression(例如 metadata->>'knowledge' = 'xxx')可在相似度计算的基础上进一步进行条件过滤。 配置 ai: ollama: base-url: http://ollama:11434 #告诉 Spring AI 去 http://ollama:11434 调用模型接口。 embedding: options: num-batch: 512 #批处理参数 model: nomic-embed-text #指定使用的 embedding 模型 rag: embed: nomic-embed-text 注意,需要提前下载模型: ollama pull deepseek-r1:1.5b ollama pull qwen2.5:7b-instruct ollama pull nomic-embed-text ollama list Docker如何开启GPU加速大模型推理 巨坑! 默认是CPU跑大模型,deepseek1.5b勉强能跑动,但速度很慢,一换qwen2.5:7b模型瞬间就跑不动了,这才发现一直在用CPU跑!! 如何排查? 1.查看ollama日志: load_backend: loaded CPU backend from /usr/lib/ollama/libggml-cpu-alderlake.so 2.本地cmd命令行输入,查看显存占用率。 nvidia-smi | 0 NVIDIA GeForce RTX 4060 ... WDDM | 00000000:01:00.0 On | N/A | | N/A 58C P0 24W / 110W | 2261MiB / 8188MiB | 6% Default | 设备状态: RTX 4060显卡驱动(576.02)和CUDA 12.9环境正常 当前GPU利用率仅6%(GPU-Util列) 显存占用2261MB/8188MB(约27.6%) 可见模型推理的时候压根没有用GPU!!! 解决 参考博客:1-3 Windows Docker Desktop安装与设置docker实现容器GPU加速_windows docker gpu-CSDN博客 1)配置WSL2,打开 PowerShell(以管理员身份运行),执行以下命令: wsl --install -d Ubuntu # 安装 Linux 发行版 wsl --set-default-version 2 # 设为默认版本 wsl --update # 更新内核 重启计算机以使更改生效。 2)检查wsl是否安装成功 C:\Users\zhangsan>wsl --list --verbose NAME STATE VERSION * Ubuntu Running 2 docker-desktop Running 2 这个命令会列出所有已安装的Linux发行版及其状态。如果看到列出的Linux发行版,说明WSL已成功安装。 3)安装docker desktop默认配置: 4)保险起见也启用一下开启 Windows 的 Hyper-V 虚拟化技术: 搜索“启用或关闭Windows功能”,勾选:Hyper-V 虚拟化技术。 5) 命令提示符输入 nvidia-smi C:\Users\zhangsan>nvidia-smi Tue Aug 19 21:18:11 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 576.02 Driver Version: 576.02 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4060 ... WDDM | 00000000:01:00.0 On | N/A | | N/A 55C P4 12W / 129W | 2132MiB / 8188MiB | 33% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ 若显示GPU信息(如型号、显存等),则表示支持。 6)Docker Desktop配置**(重要)** 打开 Docker 设置 → Resources → WSL Integration → 启用 Ubuntu 实例。 进入 Docker 设置 → Docker Engine,添加以下配置: { "experimental": true, "features": { "buildkit": true }, "registry-mirrors": ["https://registry.docker-cn.com"] // 可选镜像加速 } 保存并重启 Docker。 7)验证 GPU 加速 docker run --rm -it --gpus=all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled. > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM MapSMtoArchName for SM 8.9 is undefined. Default to use Ampere GPU Device 0: "Ampere" with compute capability 8.9 > Compute 8.9 CUDA device: [NVIDIA GeForce RTX 4060 Laptop GPU] 24576 bodies, total time for 10 iterations: 17.351 ms = 348.102 billion interactions per second = 6962.039 single-precision GFLOP/s at 20 flops per interaction 成功输出应包含 GPU 型号及性能指标 [NVIDIA GeForce RTX 4060 Laptop GPU] 8)Ollama验证: 在容器中也能显示GPU了,说明配置成功了!!! version: '3.9' services: ollama: image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/ollama:0.5.10 container_name: ollama restart: unless-stopped ports: - "11434:11434" volumes: - ./ollama:/root/.ollama runtime: nvidia environment: - NVIDIA_VISIBLE_DEVICES=all - NVIDIA_DRIVER_CAPABILITIES=all 什么原理? GPU 驱动仍运行在 Windows 主机上;WSL2 作为 Linux 内核子系统,共享访问该 GPU 驱动的底层接口;Docker Desktop 在 WSL2 内运行(作为 Linux 虚拟环境), 通过 NVIDIA Container Runtime (nvidia-container-toolkit) 把 GPU 设备挂载进容器; 最终容器内程序(如 PyTorch、Ollama)能直接使用 GPU 计算。 RAG(检索增强生成) postgre向量数据库 PostgreSQL也是结构化数据库(关系型数据库)!!! 所有数据都遵守固定的结构(Schema); 每一列(Column)定义了数据类型; 每一行(Row)表示一条记录; 表结构: @Bean public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) { return PgVectorStore.builder(jdbcTemplate, embeddingModel).build(); } PgVectorStore 会自动检测并在首次使用时创建所需的向量表,默认表名是 vector_store;默认表结构是固定格式(id, content, metadata, embedding)。 PgAdmin软件下:ai-rag-knowledge -> 架构 -> public -> 表 -> vector_store id → 每条数据的唯一标识(主键/uuid)。 content → 存放 chunk 的原始文本。 metadata → 存放 JSON 格式的额外信息(文件名、路径、知识库标签等)。 embedding → 存放向量,类型是 vector(N)(N 由 Embedding 模型决定,比如 768)。 所有文件切分出来的 chunk 都存在这一张表里,每条记录就是一个 chunk。 表的主要用途 1)相似度检索(Retrieval):用embedding <-> 查询向量 进行向量距离计算,找出与输入文本语义最相近的片段。其中<-> 是 pgvector 的距离运算符 2)结果展示(Content Retrieval):检索后,取出距离最近的若干条记录的 content,作为模型回答时的上下文。 3)溯源/过滤:通过 metadata 字段中的信息(如文件名、标签、知识类别等)进行结果筛选或来源追踪,例如:其中 ->> 从 JSON 对象中取出某个字段的值,并以文本(text)形式返回。 INSERT INTO vector_store (content, metadata) VALUES ('公司年度财报分析', '{"knowledge": "finance", "source": "report.pdf"}'), ('销售策略优化', '{"knowledge": "marketing", "source": "plan.docx"}'), ('财务合规指引', '{"knowledge": "finance", "source": "policy.pdf"}'), ('技术架构设计', '{"knowledge": "engineering", "source": "design.md"}'); 现在你想只查出属于 “财务领域(finance)” 的内容,可以这样写: SELECT id, content, metadata FROM vector_store WHERE metadata->>'knowledge' = 'finance'; 查询 同一般的SQL语句。 vector_dims(embedding)是内置函数,返回维度大小。 还有 metadata 和embedding 列显示不下。 A. 索引/入库(Ingestion) 这里用了SpringAI提供的:TikaDocumentReader 和 pgVectorStore 文档读取器 用 TikaDocumentReader 把上传的 PDF、Word、TXT、PPT 等文件解析成 List<Document>。 每个 Document 包含 text 和 metadata(比如 page、source)。 相当于是“把二进制文件 → 转成纯文本段落”。 TikaDocumentReader documentReader = new TikaDocumentReader(resource); List<Document> documents = documentReader.get(); 清洗过滤 剔除空文本,避免无效数据进入后续流程。 List<Document> docs = new ArrayList<>(documents); docs.removeIf(d -> d.getText() == null || d.getText().trim().isEmpty()); if (docs.isEmpty()) { log.warn("文件内容为空,跳过处理: {}", normalizedPath); return; } 文档切分器 用 TokenTextSplitter 把每个 Document 再切成 chunk(默认 800 tokens 一段,可配置)。 目的是避免超长文本超过 Embedding 模型的输入限制。 @Bean public TokenTextSplitter tokenTextSplitter() { return TokenTextSplitter.builder() .withChunkSize(600) // 每段最多 600 token .withMinChunkSizeChars(300) // 每段至少 300 字符 .withMinChunkLengthToEmbed(10) .withMaxNumChunks(10000) .withKeepSeparator(true) .build(); } //使用,省略依赖注入 List<Document> splits = tokenTextSplitter.apply(docs); withMinChunkSizeChars(300): 如果某个切分块的文本少于 300 个字符,TokenTextSplitter 会避免直接拆分它,而是尝试 合并它与下一个切分块,直到符合字符数要求。 打元数据 给原始文档和 chunk 都加上 knowledge(ragTag)、path、original_filename 等信息。 方便后续检索时追溯来源。 docs.forEach(doc -> { doc.getMetadata().put("knowledge", ragTag); doc.getMetadata().put("path", normalizedPath); doc.getMetadata().put("original_filename", originalFilename); }); splits.forEach(doc -> { doc.getMetadata().put("knowledge", ragTag); doc.getMetadata().put("path", normalizedPath); doc.getMetadata().put("original_filename", originalFilename); }); Embedding 模型 对 每个 chunk 调用 Ollama 的 nomic-embed-text,生成一个固定维度的向量(如 768 维)。 注意:这是对 chunk 整体嵌入,不是对单个 token。 向量存储 //配置类 @Bean public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) { return PgVectorStore.builder(jdbcTemplate, embeddingModel).build(); } //使用,省略依赖注入 pgVectorStore.accept(splits); 用 pgvector 存储 [embedding 向量 + metadata + 原始文本]。 向量维度由 Embedding 模型决定,pgvector 表的维度必须保持一致(如 768/1024/1536)。 B. 检索/回答(Query) 接收用户问题 输入用户的问题文本 message。 相似度检索 使用同一个 Embedding 模型(如 nomic-embed-text)将问题转为查询向量。 在向量库中用 余弦相似度 / 内积 搜索相似 chunk。 可附加条件过滤:如 knowledge == 'xxx',只在某个知识库范围内查。 常用参数: topK:取最相似的前 K 个结果(例如 5~8)。 minSimilarityScore(可选):过滤低相关度结果。 // 1) 相似度检索(带 ragTag 过滤) List<Document> documents = pgVectorStore.similaritySearch( SearchRequest.builder() .query(message) .topK(8) .filterExpression("knowledge == '" + ragTag + "'") .build() ); List<Document> documents = pgVectorStore.similaritySearch(request); 拼装文档上下文 把检索到的文档片段拼接成系统提示中的 DOCUMENTS 部分。 可以在拼接时附带 metadata(如文件名、页码),方便溯源。 String documentContent = documents.stream() .map(doc -> "[来源:" + doc.getMetadata().get("original_filename") + "]\n" + doc.getText()) .collect(joining("\n\n---\n\n")); 构造提示词(Prompt) 使用 SystemPromptTemplate 注入 DOCUMENTS 内容。 System Prompt 应该放在 用户消息之前,确保模型优先遵循规则。 Message ragMessage = new SystemPromptTemplate(SYSTEM_PROMPT) .createMessage(Map.of("documents", documentContent)); List<Message> messages = new ArrayList<>(); messages.add(ragMessage); // 先放系统提示 messages.add(new UserMessage(message)); 调用对话模型(流式返回) return ollamaChatModel.stream(new Prompt( messages, OllamaOptions.builder().model(model).build() )); 优化 1.优化分词逻辑 这块比较复杂,要切的恰到好处...切的不大不小。 2.更新向量嵌入模型 MCP服务 简介 - 模型上下文协议 MCP 是“模型与外部世界沟通的桥梁”。它让模型不仅能聊天,还能调用本地文件系统、数据库、网络 API 等服务,实现“有工具可用的 AI”。 基础介绍 角色 说明 举例 🖥️ MCP Server(服务端) 提供“工具能力”,比如操作文件系统、调用系统命令、执行数据库查询等。 @modelcontextprotocol/server-filesystem、mcp-server-computer.jar 🤖 MCP Client(客户端) 嵌入在应用(你的 Spring Boot)中,让模型能访问这些工具。 由 spring-ai-mcp-client-webflux-spring-boot-starter 实现 快速使用 1)引入依赖(POM) <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-mcp-client-webflux-spring-boot-starter</artifactId> </dependency> 2)配置 MCP 服务(Server) 创建配置文件:resources/config/mcp-servers-config.json { "mcpServers": { "filesystem": { "command": "npx.cmd", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "D:/folder/MCP-test", "D:/folder/MCP-test" ] }, "mcp-server-computer": { "command": "java", "args": [ "-Dspring.ai.mcp.server.stdio=true", "-jar", "D:/folder/study/apache-maven-3.8.4/mvn_repo/edu/whut/mcp/mcp-server-computer/1.0.0/mcp-server-computer-1.0.0.jar" ] } } } filesystem:定义了一个 MCP 文件系统服务; 通过 npx 启动; 调用包 @modelcontextprotocol/server-filesystem; 并将本地路径 D:/folder/MCP-test 暴露给模型访问。 mcp-server-computer:定义了一个自定义的 Java MCP 服务; 使用 java -jar 启动; 通过标准输入输出(stdio)与主程序通信。 Spring配置文件(application.yml)配置 MCP 服务加载路径 spring: ai: mcp: servers-config: classpath:config/mcp-servers-config.json 3)安装并启用 Filesystem MCP 服务 需要提前下载该文件服务,官网: https://www.npmjs.com/package/@modelcontextprotocol/server-filesystem (创建、移动目录,读取、写入文件...) 先装 Node.js,配置环境变量 node -v npm -v 安装 MCP 文件系统服务 npm install -g @modelcontextprotocol/server-filesystem 4)配置客户端 Spring AI 通过 ChatClient 调用大模型,如果你使用多个模型(如 Ollama、OpenAI),可以通过不同的 ChatModel Bean 实例来区分。 @Bean public OllamaChatModel ollamaChatModel(OllamaApi ollamaApi) { return OllamaChatModel.builder() .ollamaApi(ollamaApi) .defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build()) .build(); } @Bean public ChatClient.Builder chatClientBuilder(OllamaChatModel ollamaChatModel) { return new DefaultChatClientBuilder( ollamaChatModel, ObservationRegistry.NOOP, (ChatClientObservationConvention) null ); } 注意,ollamaChatModel()是基础模型,创建与Ollama服务交互的底层Chat模型;chatClientBuilder()是客户端构建器,提供高级功能封装(如工具调用) 5)模型调用示例 ollamaChatModel 是连接本地 Ollama 服务的客户端; 具体使用哪个模型(deepseek-r1:1.5b、qwen2.5:7b-instruct 等)是在调用时通过 OllamaOptions 决定的: ChatResponse response = chatClientBuilder .defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build()) .build() .prompt("你好,介绍一下你自己") .call(); 6)测试 MCP 调用 查看当前可用工具 @GetMapping("/tools") public Object listTools() { return Arrays.stream(tools.getToolCallbacks()) .map(cb -> Map.of( "name", cb.getName(), "description", cb.getDescription() )) .toList(); } 自动调用工具(含 MCP) @GetMapping("/test-workflow") public String testWorkflow(@RequestParam String question) { var chatClient = chatClientBuilder .defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build()) .build(); return chatClient.prompt(question).tools(tools).call().chatResponse().toString(); } 当模型发现某个问题需要使用外部工具(如文件读写、计算服务)时,会自动调用注册在 MCP 中的工具进行操作。 有时候大模型不会去调用Tools,可能是模型能力不够。 注意,docker部署后,这个路径还没改!!!自然查不到可用的工具,因为不是在本地windows中了。 自定义MCP服务 目录结构 mcp-server-demo/ ├─ src/ │ └─ main/ │ ├─ java/…/DemoApplication.java │ ├─ java/…/NoteService.java // 你的工具:@Tool 方法 │ └─ resources/application.yml // 仅需几行 └─ pom.xml POM 依赖 <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.0.0-M6</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> </dependencies> 关键配置 spring: application: name: mcp-server-demo ai: mcp: server: name: ${spring.application.name} version: 1.0.0 # 让它安静点,避免把 MCP JSON 混进正常日志 logging: level: org.springframework.ai.mcp: INFO pattern: console: server: main: banner-mode: off # 非 Web 进程(可选) # web-application-type: none 入口 & 工具 DemoApplication.java @SpringBootApplication public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } } 启动配置。 NoteService.java @Service public class NoteService { @Tool(description = "把输入转成大写并附带字符数") public Map<String, Object> toUpper( @ToolParam(name = "text", description = "要转换的文本") String text) { if (text == null) text = ""; return Map.of( "upper", text.toUpperCase(), "length", text.length() ); } } 注意,你的服务方法必须配置 @Tool(description = "获取电脑配置") 多一个注解,就向外多提供一个工具!!! 生成Jar包 在客户端项目中引用 { "mcpServers": { "mcp-server-demo": { "command": "java", "args": [ "-Dspring.ai.mcp.server.stdio=true", "-jar", "C:/path/to/target/mcp-server-demo-1.0.0.jar" ] } } } 注意上一步生成的jar包要放到这个"C:/path/to/target/mcp-server-demo-1.0.0.jar"中。 底层调用逻辑 一、启动客户端 假设你运行的客户端配置里包含: "mcpServers": { "filesystem": {...}, "mcp-server-computer": {...} } 当客户端启动时,会做以下几步: 1)客户端启动子进程 客户端发现你声明了两个 MCP 服务器,于是准备分别启动它们。 npx.cmd -y @modelcontextprotocol/server-filesystem D:/folder/MCP-test D:/folder/MCP-test java -Dspring.ai.mcp.server.stdio=true -jar D:/folder/.../mcp-server-computer-1.0.0.jar 这两个命令都会启动新的独立进程,“挂在”客户端进程下面,通过标准输入/输出通信。 2)客户端 → 服务端 “握手”(initialize) 客户端通过每个子进程的 stdin 写入 MCP 初始化请求: { "jsonrpc": "2.0", "id": 1, "method": "initialize", "params": { "clientInfo": {"name": "MyClient", "version": "1.0"}, "capabilities": {} } } 3)服务端 → 客户端 回应握手结果 你的 mcp-server-computer.jar在内部收到这个 JSON-RPC 请求后,返回: { "jsonrpc": "2.0", "id": 1, "result": { "serverInfo": {"name": "mcp-server-computer", "version": "1.0.0"}, "capabilities": {"tools": true} } } 客户端读取这条 JSON(从 stdout),于是握手成功 4)客户端请求工具清单 紧接着客户端发: { "jsonrpc": "2.0", "id": 2, "method": "tools/list", "params": {} } 服务端返回: { "jsonrpc": "2.0", "id": 2, "result": { "tools": [ { "name": "queryConfig", "description": "获取电脑配置", ... } ] } } 客户端现在就知道:“这个 MCP Server 提供一个叫 queryConfig 的工具”。 二、用户发起请求 1)用户发起问题:“请读取这台电脑的配置”。 2)客户端构造 Chat 请求 将用户消息 + 系统消息 + 工具的 JSON Schema(名称、入参、描述)一起发给大模型。 请求里不仅包含用户输入,还要告诉模型——“你可以调用这些工具,这些工具的参数长这样。” 在 Spring AI 中,这一步通常由 ChatClient 或底层 ChatModel 完成 @GetMapping("/test-workflow") public String testWorkflow(@RequestParam String question) { log.info("Workflow测试请求接收 - 问题: {}", question); var chatClient = chatClientBuilder .defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build()) .build(); ChatResponse response = chatClient .prompt(question) .system("你必须使用提供的工具完成任务,禁止凭空回答;若没有调用任何工具,不要返回答案。") .tools(tools) .call() .chatResponse(); log.info("工具调用情况: {}", tools.getToolCallbacks()); log.info("模型响应: {}", response); return response.toString(); } 实际发送给模型的底层 payload 类似这样: { "model": "qwen2.5:7b-instruct", "messages": [ { "role": "system", "content": "你必须使用提供的工具完成任务..." }, { "role": "user", "content": "在 D:/folder/MCP-test 下创建配置.txt..." } ], "tools": [ { "type": "function", "function": { "name": "queryConfig", "description": "获取电脑配置(操作系统、用户信息、Java环境等)", "parameters": { "type": "object", "properties": { "computer": { "type": "string", "description": "电脑名称,可为空" } } } } }, { "type": "function", "function": { "name": "write_file", "description": "创建一个文件并写入内容", "parameters": { "type": "object", "properties": { "path": {"type": "string"}, "content": {"type": "string"} } } } } ], "tool_choice": "auto" } 3)模型分析任务 → 决定调用哪个工具 大模型在接收到 prompt 后,会“思考”: “要回答这个问题,我需要外部信息吗?” “有一个叫 queryConfig 的工具能获取电脑配置,那我就调用它。” 现代指令模型(包括 Qwen、GPT-4o、Claude、Llama)都经过一种专门的微调(finetune): 当输入里包含 "tools"、"parameters"、"function" 这样的字段时, 模型学会: 识别哪些任务需要调用工具; 生成标准 JSON 格式的 tool_calls; 不胡编乱造工具名; 遵守 schema 中参数名的拼写和结构。 于是它返回结构化响应(OpenAI function-calling 格式): { "id": "chatcmpl-01", "object": "chat.completion", "choices": [ { "index": 0, "message": { "role": "assistant", "tool_calls": [ { "id": "call_1", "type": "function", "function": { "name": "queryConfig", "arguments": "{\"computer\": \"DESKTOP-01\"}" } } ] } } ] } 4)客户端执行工具调用(MCP 调用链) Spring AI 的 DefaultToolCallingManager 会检测到(框架自动实现): if (response.hasToolCalls()) { executeToolCalls(response.getToolCalls()); } 客户端解析出模型请求调用的工具名 queryConfig,然后通过 MCP 协议向对应的 MCP Server(你的 mcp-server-computer)发送调用请求(通过 stdin): { "jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": { "name": "queryConfig", "arguments": { "computer": "DESKTOP-01" } } } 注意,默认的工具名就是函数名!!! 你的 MCP Server(Spring Boot 进程)接收后,由框架自动路由到 @Tool 方法: @Service public class ComputerService { @Tool(description = "获取电脑配置") public ComputerFunctionResponse queryConfig( @ToolParam(name = "computer", description = "电脑名称") String computer ) { log.info("获取电脑配置信息: {}", computer); // 读取系统属性 + systeminfo 等命令 ... return response; // 返回 JSON 对象 } } 6)客户端将结果反馈回模型(第二轮) 客户端收到结果后,会把它作为新的上下文输入发回模型: { "role": "tool", "tool_call_id": "call_1", "name": "queryConfig", "content": "{\"osName\": \"Windows 11\", ... }" } 模型在这时再进行一轮“总结性思考”: “我得到了电脑配置结果,可以组织成自然语言回答。” 最终返回: { "role": "assistant", "content": "你的电脑运行的是 Windows 11,架构为 x64,用户名为 Jerry。" } sequenceDiagram participant User participant Client participant Model participant MCPServer as MCP Server User->>Client: "请读取这台电脑的配置" Client->>Model: 封装 Prompt + Tool Schema<br/>发送请求 Model-->>Client: 返回 tool_calls: queryConfig(...) Client->>MCPServer: 通过 MCP stdin 发送<br/>tools/call 请求 MCPServer-->>Client: 执行 Java @Tool 方法<br/>返回 JSON 结果 Client->>Model: 将工具结果再发给模型 Model-->>Client: 生成自然语言回答 Client-->>User: 输出最终文本 如果有长的调用链 当模型需要调用多个工具(例如:create_directory → queryConfig → write_file), Spring AI 会自动进入一个「循环式调用流程」,直到模型自己不再请求调用工具为止。 框架就会自动: 1.发现模型要调用工具; 2.执行工具; 3.把结果回灌给模型; 4.模型如果再要求调用下一个工具,再执行; 5.一直到模型返回纯文本。 while (true) { ChatResponse response = model.call(currentPrompt); if (response.hasToolCalls()) { // 1. 模型请求调用工具 for (ToolCall call : response.getToolCalls()) { Object result = executeTool(call.name, call.arguments); // 2. 把结果封装成“tool_result”消息 currentPrompt.addToolResult(call.id, call.name, result); } } else { // 没有工具调用 = 模型给出最终自然语言 return response; } }
项目
zy123
1年前
0
21
0
2025-08-11
拼团设计模式
设计模式 单例模式 懒汉 注意,单例模式的构造函数是私有的! public class LazySingleton { private static volatile LazySingleton INSTANCE; private LazySingleton() {} public static LazySingleton getInstance() { if (INSTANCE == null) { // 第一次检查 synchronized (LazySingleton.class) { if (INSTANCE == null) { // 第二次检查 INSTANCE = new LazySingleton(); } } } return INSTANCE; } } 第一次检查:防止重复实例化、以及进行synchronized同步块(防止每次加锁的开销)。 第二次检查:防止有多个线程同时通过第一次检查,然后依次进入同步块后,创建N个实例。 volatile:防止指令重排序。 instance = new LazySingleton(); 正确顺序是: memory = allocate(); // 分配内存 ctorInstance(memory); // 调用构造函数,初始化对象 INSTANCE = memory; // 将对象引用赋值给 INSTANCE 由于 JVM 和 CPU 都可能对指令进行优化重排,步骤 ② 和 ③ 的顺序可能被交换! memory = allocate(); // 分配内存 INSTANCE = memory; // 把引用赋给 INSTANCE(但未初始化完) ctorInstance(memory); // 调用构造函数 线程 A刚执行完赋值(3),但没调用构造函数;此时线程B来了,发现 INSTANCE != null,直接返回这个未初始化完成的对象!!! 饿汉 public class EagerSingleton { // 类加载时就初始化实例 private static final EagerSingleton INSTANCE = new EagerSingleton(); // 私有构造函数 private EagerSingleton() {} // 全局访问点 public static EagerSingleton getInstance() { return INSTANCE; } } 工厂模式 简单工厂 // 产品接口 interface Product { void use(); } // 具体产品A class ConcreteProductA implements Product { @Override public void use() { System.out.println("使用产品A"); } } // 具体产品B class ConcreteProductB implements Product { @Override public void use() { System.out.println("使用产品B"); } } class SimpleFactory { // 根据参数创建不同的产品 public static Product createProduct(String type) { switch (type) { case "A": return new ConcreteProductA(); case "B": return new ConcreteProductB(); default: throw new IllegalArgumentException("未知产品类型"); } } } public class Client { public static void main(String[] args) { // 通过工厂创建产品 Product productA = SimpleFactory.createProduct("A"); productA.use(); // 输出: 使用产品A Product productB = SimpleFactory.createProduct("B"); productB.use(); // 输出: 使用产品B } } 缺点:添加新产品需要修改工厂类(违反开闭原则) 抽象工厂 抽象工厂模式是一种创建型设计模式,它提供一个接口用于创建相关或依赖对象的家族,而不需要明确指定具体类。 // 抽象产品接口 interface Button { void render(); } interface Checkbox { void render(); } // 具体产品实现 - Windows 风格 class WindowsButton implements Button { @Override public void render() { System.out.println("渲染一个 Windows 风格的按钮"); } } class WindowsCheckbox implements Checkbox { @Override public void render() { System.out.println("渲染一个 Windows 风格的复选框"); } } // 具体产品实现 - MacOS 风格 class MacOSButton implements Button { @Override public void render() { System.out.println("渲染一个 MacOS 风格的按钮"); } } class MacOSCheckbox implements Checkbox { @Override public void render() { System.out.println("渲染一个 MacOS 风格的复选框"); } } // 抽象工厂接口 interface GUIFactory { Button createButton(); Checkbox createCheckbox(); } // 具体工厂实现 - Windows class WindowsFactory implements GUIFactory { @Override public Button createButton() { return new WindowsButton(); } @Override public Checkbox createCheckbox() { return new WindowsCheckbox(); } } // 具体工厂实现 - MacOS class MacOSFactory implements GUIFactory { @Override public Button createButton() { return new MacOSButton(); } @Override public Checkbox createCheckbox() { return new MacOSCheckbox(); } } // 客户端代码 public class Application { private Button button; private Checkbox checkbox; public Application(GUIFactory factory) { button = factory.createButton(); checkbox = factory.createCheckbox(); } public void render() { button.render(); checkbox.render(); } public static void main(String[] args) { // 根据配置或环境选择工厂 GUIFactory factory; String osName = System.getProperty("os.name").toLowerCase(); if (osName.contains("win")) { factory = new WindowsFactory(); } else { factory = new MacOSFactory(); } Application app = new Application(factory); app.render(); } } 观察者模式 是一种行为型设计模式,定义对象之间一对多的依赖关系,当一个对象(被观察者 / Subject)状态发生变化时 ,会自动通知所有依赖它的对象(观察者 / Observer),实现事件通知机制。 典型应用场景: GUI 事件监听(按钮点击通知多个监听器) 消息订阅/发布系统(发布者-订阅者) Spring 的事件机制(ApplicationEvent) 数据模型变化 → 界面自动更新(MVC、MVVM) 模板方法 核心思想: 在抽象父类中定义算法骨架(固定执行顺序),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。 如果仅仅是把重复的方法抽取成公共函数,不叫模板方法!模板方法要设计算法骨架!!! Client ───▶ AbstractClass ├─ templateMethod() ←—— 固定流程 │ step1() │ step2() ←—— 抽象,可变 │ step3() └─ hookMethod() ←—— 可选覆盖 ▲ │ extends ┌──────────┴──────────┐ │ ConcreteClassA/B… │ 示例: // 1. 抽象模板 public abstract class AbstractDialog { // 模板方法:固定调用顺序,设为 final 防止子类改流程 public final void show() { initLayout(); bindEvent(); beforeDisplay(); // 钩子,可选 display(); afterDisplay(); // 钩子,可选 } // 具体公共步骤 private void initLayout() { System.out.println("加载通用布局文件"); } // 需要子类实现的抽象步骤 protected abstract void bindEvent(); // 钩子方法,默认空实现 protected void beforeDisplay() {} protected void afterDisplay() {} private void display() { System.out.println("弹出对话框"); } } // 2. 子类:登录对话框 public class LoginDialog extends AbstractDialog { @Override protected void bindEvent() { System.out.println("绑定登录按钮事件"); } @Override protected void afterDisplay() { System.out.println("focus 到用户名输入框"); } } // 3. 调用 public class Demo { public static void main(String[] args) { AbstractDialog dialog = new LoginDialog(); dialog.show(); /* 输出: 加载通用布局文件 绑定登录按钮事件 弹出对话框 focus 到用户名输入框 */ } } 要点 复用公共流程:initLayout()、display() 写一次即可。 限制流程顺序:show() 定为 final,防止子类乱改步骤。 钩子方法:子类可选择性覆盖(如 beforeDisplay)。 策略模式 核心思想: 将可以互换的算法或行为抽象为独立的策略类,运行时由**上下文类(Context)**选择合适的策略对象去执行。调用方(Client)只依赖统一的接口,不关心具体实现。 ┌───────────────┐ │ Client │ └─────▲─────────┘ │ has-a ┌─────┴─────────┐ implements │ Context │────────────┐ ┌──────────────┐ │ (使用者) │ strategy └─▶│ Strategy A │ └───────────────┘ ├──────────────┤ │ Strategy B │ └──────────────┘ // 策略接口 public interface PaymentStrategy { void pay(int amount); } // 策略A:微信支付 @Service("wechat") public class WechatPay implements PaymentStrategy { public void pay(int amount) { System.out.println("使用微信支付 " + amount + " 元"); } } // 策略B:支付宝支付 @Service("alipay") public class Alipay implements PaymentStrategy { public void pay(int amount) { System.out.println("使用支付宝支付 " + amount + " 元"); } } // 上下文类 public class PaymentContext { private PaymentStrategy strategy; public PaymentContext(PaymentStrategy strategy) { this.strategy = strategy; } public void execute(int amount) { strategy.pay(amount); } } // 调用方 public class Main { public static void main(String[] args) { PaymentContext ctx = new PaymentContext(new WechatPay()); ctx.execute(100); ctx = new PaymentContext(new Alipay()); ctx.execute(200); } } 下面有更优雅的策略选择方式! Spring集合自动注入 在策略、工厂、插件等模式中,经常需要维护**“策略名 → 策略对象”**的映射。Spring 可以通过 Map<String, 接口类型> 一次性注入所有实现类。 @Resource private final Map<String, IDiscountCalculateService> discountCalculateServiceMap; 字段类型:Map<String, IDiscountCalculateService> key—— Bean 的名字 默认是类名首字母小写 (mjCalculateService) 或者你在实现类上显式写的 @Service("MJ") value —— 那个实现类对应的实例 Spring 机制: 启动时扫描所有实现 IDiscountCalculateService 的 Bean。 把它们按 “BeanName → Bean 实例” 的映射注入到这张 Map 里。 你一次性就拿到了“策略字典”。 示例: // 上下文类:自动注入所有策略 Bean @Component @RequiredArgsConstructor public class PaymentContext { // key 为 Bean 名(如 "wechat"、"alipay"),value 为策略实例 private final Map<String, PaymentStrategy> paymentStrategyMap; public void pay(String strategyKey, int amount) { PaymentStrategy strategy = paymentStrategyMap.get(strategyKey); if (strategy == null) { throw new IllegalArgumentException("无匹配支付方式: " + strategyKey); } strategy.pay(amount); } } // 调用方示例 @Component @RequiredArgsConstructor public class PaymentService { private final PaymentContext paymentContext; public void process() { paymentContext.pay("wechat", 100); // 输出:使用微信支付 100 元 paymentContext.pay("alipay", 200); // 输出:使用支付宝支付 200 元 } } 模板方法+策略模式 本项目的价格试算同时用了策略模式 + 模板方法模式: 策略模式(Strategy): IDiscountCalculateService 是策略接口;ZKCalculateService、ZJCalculateService ...是可替换的折扣策略(@Service("ZK") / @Service("ZJ") 作为选择键)。外部可以根据活动配置里的类型码选哪个实现来算价——这就是“运行时可切换算法”。 模板方法模式(Template Method): AbstractDiscountCalculateService#calculate(...) 把共同流程固定下来(先进行人群校验 → 计算优惠后价格),并把“真正的计算”这一步延迟到子类通过 doCalculate(...) 实现。 责任链 应用场景:日志系统、审批流程、权限校验——任何需要将请求按阶段传递、并由某一环节决定是否继续或终止处理的地方,都非常适合责链模式。 场景:员工报销审批 组长审批 报销单先到组长这里。 组长要么通过,要么驳回;如果通过,就传递给下一个。 部门经理审批 组长通过后,报销单自动流转到部门经理。 部门经理再看金额和合理性,要么通过,要么驳回;如果通过,就继续往下。 财务审批 部门经理通过后,单子来到财务。 财务校验发票、预算,要么通过,要么驳回;如果通过,就继续。 总经理审批 如果金额超过某个阈值(比如 5 万),最后需要总经理签字。 总经理通过后,整个审批链结束。 典型的责任链模式要点: 解耦请求发送者和处理者:调用者只持有链头,不关心中间环节。 动态组装:通过 appendNext 可以灵活地增加、删除或重排链上的节点。 可扩展:新增处理逻辑只需继承 AbstractLogicLink 并实现 apply,不用改动已有代码。 单实例链 可以理解成“单向、单链表式的链条”:每个节点只知道自己的下一个节点(next),链头只有一个入口。 你可以在启动或运行时动态组装:head.appendNext(a).appendNext(b).appendNext(c); T / D / R 是啥? T:请求的静态入参(本次请求的主要数据)。 D:动态上下文(链路里各节点共享、可读写的状态容器,比如日志收集、校验中间结果)。 R:最终返回结果类型。 1)接口定义:ILogicChainArmory<T, D, R> 提供添加节点方法和获取节点 // 定义了“链条组装”的最小能力:能拿到下一个节点、也能把下一个节点接上去 public interface ILogicChainArmory<T, D, R> { // 获取当前节点的“下一个”处理者 ILogicLink<T, D, R> next(); // 把新的处理者挂到当前节点后面,并返回它(方便链式 append) ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next); } 2)ILogicLink<T, D, R> 继承自 ILogicChainArmory<T, D, R>,并额外声明了核心方法 apply // 真正的“处理节点”接口:在具备链条组装能力的基础上,还要能“处理请求” public interface ILogicLink<T, D, R> extends ILogicChainArmory<T, D, R> { R apply(T requestParameter, D dynamicContext) throws Exception; } 3)抽象基类:AbstractLogicLink,提供了责任链节点的通用骨架,(保存 next、实现 appendNext/next()、以及一个便捷的 protected next(...),这样具体的节点类就不用重复这些代码,真正的业务处理逻辑仍然交由子类去实现 apply(...)。 // 抽象基类:大多数节点都可以继承它,避免重复写“组装链”的样板代码 public abstract class AbstractLogicLink<T, D, R> implements ILogicLink<T, D, R> { // 指向“下一个处理者”的引用 private ILogicLink<T, D, R> next; @Override public ILogicLink<T, D, R> next() { return next; } @Override public ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next) { this.next = next; return next; // 返回 next 以便连续 append,类似 builder } /** * 便捷方法:当前节点决定“交给下一个处理者” */ protected R next(T requestParameter, D dynamicContext) throws Exception { // 直接把请求丢给下一个节点继续处理 // 注意:这里假设 next 一定存在;实际项目里建议判空以免 NPE(见下文改进建议) return next.apply(requestParameter, dynamicContext); } } 子类只需要继承 AbstractLogicLink 并实现 apply(...): 能处理就处理(并可选择直接返回,终止链条)。 不处理或处理后仍需后续动作,就 return next(requestParameter, dynamicContext) 继续传递。 4)实现子类 @Component public class AuthLink extends AbstractLogicLink<Request, Context, Response> { @Override public Response apply(Request req, Context ctx) throws Exception { if (!ctx.isAuthenticated()) { // 未认证:立刻终止;也可以在这里构造一个标准错误响应返回 throw new UnauthorizedException(); } // 认证通过,继续下一个环节 return next(req, ctx); } } @Component public class LoggingLink extends AbstractLogicLink<Request, Context, Response> { @Override public Response apply(Request req, Context ctx) throws Exception { System.out.println("Request received: " + req); return next(req, ctx); } } @Component public class BusinessLogicLink extends AbstractLogicLink<Request, Context, Response> { @Override public Response apply(Request req, Context ctx) throws Exception { // 业务逻辑... return new Response(...); } } 5)组装链 @Configuration @RequiredArgsConstructor public class LogicChainFactory { private final AuthLink authLink; private final LoggingLink loggingLink; private final BusinessLogicLink businessLogicLink; @Bean public ILogicLink<Request, Context, Response> logicChain() { return authLink .appendNext(loggingLink) .appendNext(businessLogicLink); } } 示例图: AuthLink.apply └─▶ LoggingLink.apply └─▶ BusinessLogicLink.apply └─▶ 返回 Response 这种模式链上的每个节点都手动 next()到下一节点。 多实例链1 以上是单例链,即只能创建一条链;比如A->B->C,不能创建别的链,因为节点Bean是单例的,如果创别的链会导致指针引用错误!!! 如果想变成多例链: 1)节点由默认的单例模式改为原型模式: @Component @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) public class A extends AbstractLogicLink<Req, Ctx, Resp> { ... } 2)组装链的时候注明不同链的bean名称: /** 全局唯一链:A -> B -> C */ @Bean("chainABC") public ILogicLink<Req, Ctx, Resp> chainABC() { A a = aProvider.getObject(); B b = bProvider.getObject(); C c = cProvider.getObject(); return a.appendNext(b).appendNext(c); // 返回链头 a } /** 全局唯一链:A -> C */ @Bean("chainAC") public ILogicLink<Req, Ctx, Resp> chainAC() { A a = aProvider.getObject(); C c = cProvider.getObject(); return a.appendNext(c); // 返回链头 a(另一套实例) } 多实例链2 前面是每个节点自己要维护下一个节点。 authLink.appendNext(loggingLink).appendNext(businessLogicLink); 而这里,节点只管apply,链路的遍历由容器(双向链表)来维护。 /** * 通用逻辑处理器接口 —— 责任链中的「节点」要实现的核心契约。 */ public interface ILogicHandler<T, D, R> { /** * 默认的 next占位实现,方便节点若不需要向后传递时直接返回 null。 */ default R next(T requestParameter, D dynamicContext) { return null; } /** * 节点的核心处理方法。 */ R apply(T requestParameter, D dynamicContext) throws Exception; } /** * 业务链路容器 —— 双向链表实现,同时实现 ILogicHandler,从而可以被当作单个节点使用。 */ public class BusinessLinkedList<T, D, R> extends LinkedList<ILogicHandler<T, D, R>> implements ILogicHandler<T, D, R>{ public BusinessLinkedList(String name) { super(name); } /** * BusinessLinkedList是头节点,它的apply方法就是循环调用后面的节点,直至返回。 * 遍历并执行链路。 */ @Override public R apply(T requestParameter, D dynamicContext) throws Exception { Node<ILogicHandler<T, D, R>> current = this.first; // 顺序执行,直到链尾或返回结果 while (current != null) { ILogicHandler<T, D, R> handler = current.item; R result = handler.apply(requestParameter, dynamicContext); if (result != null) { // 节点命中,立即返回 return result; } //result==null,则交给那一节点继续处理 current = current.next; } // 全链未命中 return null; } } /** * 链路装配工厂 —— 负责把一组 ILogicHandler 顺序注册到 BusinessLinkedList 中。 */ public class LinkArmory<T, D, R> { private final BusinessLinkedList<T, D, R> logicLink; /** * @param linkName 链路名称,便于日志排查 * @param logicHandlers 节点列表,按传入顺序链接 */ @SafeVarargs public LinkArmory(String linkName, ILogicHandler<T, D, R>... logicHandlers) { logicLink = new BusinessLinkedList<>(linkName); for (ILogicHandler<T, D, R> logicHandler: logicHandlers){ logicLink.add(logicHandler); } } /** 返回组装完成的链路 */ public BusinessLinkedList<T, D, R> getLogicLink() { return logicLink; } } //工厂类,可以定义多条责任链,每条有自己的Bean名称区分。 @Bean("tradeRuleFilter") public BusinessLinkedList<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> tradeRuleFilter(ActivityUsabilityRuleFilter activityUsabilityRuleFilter, UserTakeLimitRuleFilter userTakeLimitRuleFilter) { // 1. 组装链 LinkArmory<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> linkArmory = new LinkArmory<>("交易规则过滤链", activityUsabilityRuleFilter, userTakeLimitRuleFilter); // 2. 返回链容器(即可作为责任链使用) return linkArmory.getLogicLink(); } 示例图: BusinessLinkedList.apply ←─ 只有这一层在栈里 while 循环: ├─▶ 调用 ActivityUsability.apply → 返回 null → 继续 ├─▶ 调用 UserTakeLimit.apply → 返回 null → 继续 └─▶ 调用 ... → 返回 Result → break 链头拿着“游标”一个个跑,节点只告诉“命中 / 未命中”。 这里无需把节点改为原型模式,也可以实现多例链,因为由双向链表BusinessLinkedList 负责保存链路关系和推进执行,而ILogicHandler节点本身不再保存 next 指针,所以它们之间没有共享可变状态。 本项目中使用多实例链2,有以下场景: 一、拼团「锁单前」校验链 目标:在真正锁单前把“活动有效性 / 用户参与资格 / 可用库存”一口气校清楚,避免后续回滚。 1.活动有效性校验 ActivityUsability (当前时间是否早于活动截止时间) 2.用户可参与活动次数校验 UserTakeLimitRuleFilter(默认用户只可参与一次拼团) 3.剩余库存校验 TeamStockOccupyRuleFilter(可能同时有多人点击参与当前拼团,尝试抢占库存,仅部分人可通过校验。) 校验通过方可进行真正的锁单。 二、交易结算校验链 1.渠道黑名单校验 SCRuleFilter:某签约渠道下架/风控拦截,禁止结算。 2.外部单号校验 OutTradeNoRuleFilter:查营销订单;不存在或已退单(CLOSE)→ 不结算。 3.可结算时间校验 SettableRuleFilter:结算时间必须在拼团有效期内(outTradeTime < team.validEndTime),比如发起 拼团一个小时之内要结算完毕。 4.结束节点EndRuleFilter:整理上下文到返回对象,作为结算规则校验的产出。 检验通过方可进入真正的结算。 三、交易退单执行链 1.数据加载 DataNodeFilter:按 userId + outTradeNo 查询营销订单与拼团信息,写入上下文。 2.重复退单检查 UniqueRefundNodeFilter:订单已是 CLOSE → 视为幂等重复,直接返回。 3.退单策略执行 RefundOrderNodeFilter:依据“拼团态 + 订单态”选用具体退单策略 IRefundOrderStrategy,执行退款/解锁/改库并返回成功结果。 本身就是完整的退单流程。 规则树流程 结构:节点之间呈树状关系,一个节点可以路由到多个不同的“下一跳”。 执行规则:根据 上下文数据(request + context),选择不同的分支继续执行。 责任链一开始就组装成链,依次执行;规则树每个节点中的get() 方法会根据上下文选择不同的下一跳。 场景:风控规则树(用户支付时校验) RootNode:进入风控 RiskScoreNode (风险评分节点) 如果分数 < 30 → 通过节点(直接放行支付) 如果分数 30 ~ 60 → 人工审核节点(挂起订单,通知客服人工确认) 如果分数 > 60 → 拒绝节点(直接拦截交易) 整体分层思路 分层 作用 关键对象 通用模板层 抽象出与具体业务无关的「规则树」骨架,解决 如何找到并执行策略 的共性问题 StrategyMapper、StrategyHandler、AbstractStrategyRouter<T,D,R> 业务装配层 基于模板,自由拼装出 一棵 贴合业务流程的策略树 RootNode / SwitchNode / MarketNode / EndNode … 对外暴露层 通过 工厂 + 服务支持类 将整棵树封装成一个可直接调用的 StrategyHandler,并交给 Spring 整体托管 DefaultActivityStrategyFactory、AbstractGroupBuyMarketSupport 通用模板层:规则树的“骨架” 角色 职责 关系 StrategyMapper 映射器:依据 requestParameter + dynamicContext 选出 下一个 策略节点 被 AbstractStrategyRouter 调用 StrategyHandler 处理器:真正执行业务逻辑;apply 结束后可返回结果或继续路由 节点本身 / 路由器本身都是它的实现 AbstractStrategyRouter<T,D,R> 路由模板:① 调用 get(...) 找到合适的 StrategyHandler;② 调用该 handler 的 apply(...);③ 若未命中则走 defaultStrategyHandler 同时实现 StrategyMapper 与 StrategyHandler,但自身保持 抽象,把细节延迟到子类 业务装配层:一棵可编排的策略树 RootNode -> SwitchNode -> MarketNode -> EndNode ↘︎ OtherNode ... 每个节点 继承 AbstractGroupBuyMarketSupport(业务基类) 实现 get(...):决定当前节点的下一跳是哪一个节点 实现 apply(...):实现节点自身应做的业务动作(或继续下钻) 组合方式 路由是“数据驱动”的:并非工厂把链写死,而是节点在运行期根据 request + context 决定下一跳(可能是ERROR_NODE或END_NODE),灵活插拔。 对外暴露层:工厂 + 服务支持类 组件 主要职责 DefaultActivityStrategyFactory (@Service) 仅负责把 RootNode 暴露为 StrategyHandler 入口(交由 Spring 管理,方便注入)。 AbstractGroupBuyMarketSupport 业务服务基类:封装拼团场景下共用的查询、工具方法;供每个节点继承使用 本项目执行总览: 调用入口:factory.strategyHandler() → 返回 RootNode(实现了 StrategyHandler)。 执行流程: apply(...):模板入口,先跑 multiThread(...) 预取/并发任务,再跑 doApply(...)。 doApply(...):每个节点自己的业务;通常在末尾调用 router(...) 继续下一个节点(return router(request, ctx);)。也可以在某些节点“短路返回”,不再路由。 router(request, ctx):内部调用当前节点的 get(...) 来挑选下一节点next,若存在就调用 next.apply(...) 递归推进;若不存在(或是到达 EndNode),则收束返回。 RootNode 校验必填参数:userId/goodsId/source/channel。 合法则路由到 SwitchNode;非法直接抛 ILLEGAL_PARAMETER。 SwitchNode(总开关、不区分活动,做总体的降级限流) 调用 repository.downgradeSwitch() 判断是否降级;是则抛 E0003。 调用 repository.cutRange(userId) 做切量;不在范围抛 E0004。 通过后路由到 MarketNode。 MarketNode multiThread(...) 中并发拉取: 拼团活动配置 GroupBuyActivityDiscountVO 商品信息 SkuVO 写入 DynamicContext doApply(...) 读取配置 + SKU(Stock Keeping Unit库存量单位),按 marketPlan 选 IDiscountCalculateService,计算 payPrice / deductionPrice 并写回上下文。 路由判定: 若配置/商品/deductionPrice 有缺失 → ErrorNode 否则 → TagNode TagNode(业务相关,部分人不在本次活动范围内!) 若活动没配置 tagId → 视为不限定人群:visible=true、enable=true。 否则通过 repository.isTagCrowdRange(tagId, userId) 判断是否在人群内,并据此更新 visible/enable。 路由到 EndNode。 EndNode 从 DynamicContext 读取:skuVO / payPrice / deductionPrice / groupBuyActivityDiscountVO / visible / enable; 构建并返回最终的 TrialBalanceEntity,链路终止。 ErrorNode 统一异常出口;若无配置/无商品,抛 E0002;否则可返回空结果作为兜底; 返回后走 defaultStrategyHandler(结束)。
项目
zy123
1年前
0
12
0
2025-06-20
拼团交易系统
拼团交易系统 部署 本地环境:Maven3.8.4 SpringBoot: 2.7.12 jdk:1.8 目录结构: 本地启动-1 docker-compose: version: '3.8' services: # 1. 前端 group-buy-market-front: image: nginx:alpine container_name: group-buy-market-front restart: unless-stopped ports: - '18091:80' volumes: - ./nginx/html:/usr/share/nginx/html - ./nginx/conf/nginx.conf:/etc/nginx/nginx.conf:ro privileged: true networks: - group-buy-network # 4. Java 后端 group-buying-sys: build: context: ../../.. # 从 docs/tag/v2.0 回到项目根 dockerfile: group-buying-sys-app/Dockerfile image: smile/group-buying-sys:latest container_name: group-buying-sys restart: unless-stopped depends_on: mysql: condition: service_healthy redis: condition: service_healthy ports: - '8091:8091' environment: - TZ=Asia/Shanghai - SPRING_PROFILES_ACTIVE=prod volumes: - ./log:/data/log logging: driver: json-file options: max-size: '10m' max-file: '3' networks: - group-buy-network mysql: image: mysql:8.0 container_name: group-buy-mysql hostname: mysql command: --default-authentication-plugin=mysql_native_password restart: unless-stopped environment: TZ: Asia/Shanghai MYSQL_ROOT_PASSWORD: 123456 ports: - "13306:3306" volumes: - ./mysql/my.cnf:/etc/mysql/conf.d/mysql.cnf:ro - ./mysql/sql:/docker-entrypoint-initdb.d healthcheck: test: [ "CMD", "mysqladmin" ,"ping", "-h", "localhost" ] interval: 5s timeout: 10s retries: 10 start_period: 15s networks: - group-buy-network # Redis redis: image: redis:6.2 restart: unless-stopped container_name: group-buy-redis hostname: redis privileged: true ports: - 16379:6379 volumes: - ./redis/redis.conf:/usr/local/etc/redis/redis.conf command: redis-server /usr/local/etc/redis/redis.conf networks: - group-buy-network healthcheck: test: [ "CMD", "redis-cli", "ping" ] interval: 10s timeout: 5s retries: 3 # rabbitmq # 账密 admin/admin # rabbitmq-plugins enable rabbitmq_management rabbitmq: image: rabbitmq:3.8-management container_name: group-buy-rabbitmq hostname: rabbitmq restart: unless-stopped ports: - "5672:5672" - "15672:15672" environment: RABBITMQ_DEFAULT_USER: admin RABBITMQ_DEFAULT_PASS: admin command: rabbitmq-server volumes: - ./rabbitmq/enabled_plugins:/etc/rabbitmq/enabled_plugins - ./rabbitmq/mq-data:/var/lib/rabbitmq networks: - group-buy-network nacos: image: nacos/nacos-server:v2.1.0 container_name: group-buy-nacos-server hostname: nacos restart: unless-stopped env_file: - ./nacos/custom.env ports: - "8848:8848" - "9848:9848" - "9849:9849" depends_on: - mysql networks: - group-buy-network volumes: - ./nacos/init.d:/docker-entrypoint-init.d networks: group-buy-network: external: true 本地启动,首先需要把docker中的mysql、redis、rabbitmq基本环境启动起来即可,其中nacos、group-buy-market-front(拼团前端)、group-buying-sys(拼团后端)都不用启。 然后项目代码改几个配置: 1)application配置文件切换到dev模式 spring: profiles: active: dev 2)application-dev中的dubbo相关配置注释掉 #dubbo: # application: # name: group-buy-market-service # 换成各自服务名 # registry: # address: nacos://localhost:8848 # 远程环境写内网地址 # # username/password 如果 Nacos 开了鉴权 # protocol: # name: dubbo # port: 20880 # 生产者开放端口;消费者可不写 # consumer: # timeout: 3000 # 毫秒 # check: false # 忽略启动时服务是否可用 3)把启动类上的@EnableDubbo注释掉 @SpringBootApplication @Configurable @EnableScheduling //@EnableDubbo(scanBasePackages = "edu.whut.trigger") public class Application { public static void main(String[] args){ SpringApplication.run(Application.class); } } 这样就不用配置 nacos 和小型支付商城 pay-mall 了,但是也无法使用前端界面联调,只能APIFOX、POSTMAN进行接口测试。 本地启动-2 要想前端联调,由于本服务是微服务项目,请求都由小型支付商城pay-mall发出,所以在本地启动-1的基础上,需要docker部署nacos、pay-mall、前端、frp内网穿透(可选),并且把项目代码中和dubbo相关的配置都启用,再运行后端。 其中前端需要修改一下nginx.conf中的: # 上游后端定义 upstream gbm_backend { # server group-buying-sys:8091; #线上部署 server host.docker.internal:8091; # 本地调试 } upstream pay_backend { # server pay-mall:8092; server host.docker.internal:8092; } 线上部署 docker-compose文件中的所有环境+前后端都用docker部署,其中后端单独写个dockerfile文件。 项目代码中将模式改为prod,dubbo配置全部启用,nginx.conf配置为线上部署。 dockerfile: # —— 第一阶段:Maven 构建 —— FROM maven:3.8.7-eclipse-temurin-17-alpine AS builder WORKDIR /workspace # 把项目级 settings.xml 复制到容器里 COPY .mvn/settings.xml /root/.m2/settings.xml # 1. 先只拷贝父 POM 及各模块的 pom.xml,加速依赖下载 COPY pom.xml ./pom.xml COPY group-buying-sys-api/pom.xml ./group-buying-sys-api/pom.xml COPY group-buying-sys-domain/pom.xml ./group-buying-sys-domain/pom.xml COPY group-buying-sys-infrastructure/pom.xml ./group-buying-sys-infrastructure/pom.xml COPY group-buying-sys-trigger/pom.xml ./group-buying-sys-trigger/pom.xml COPY group-buying-sys-types/pom.xml ./group-buying-sys-types/pom.xml COPY group-buying-sys-app/pom.xml ./group-buying-sys-app/pom.xml # 离线下载所有依赖 RUN mvn dependency:go-offline -B # 2. 拷贝所有源码 COPY . . # 3. 只打包 main 应用模块(连带编译它依赖的模块),跳过测试,加速构建 RUN mvn \ -f pom.xml clean package \ -pl group-buying-sys-app -am \ -DskipTests -B # —— 第二阶段:运行时镜像 —— FROM openjdk:17-jdk-slim LABEL maintainer="smile" # 可选:设置时区 ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone # 把构建产物拷过来 COPY --from=builder \ /workspace/group-buying-sys-app/target/group-buying-sys-app.jar \ app.jar # 暴露端口,按需改 EXPOSE 8091 ENTRYPOINT ["java", "-jar", "app.jar"] 修改项目后部署的影响: 前端服务 (group-buy-market-front) 代码位置:通过卷挂载 (./nginx/html:/usr/share/nginx/html)。 修改影响 如果修改的是 ./nginx/html 下的前端代码(如 HTML/JS/CSS),无需重建,Nginx 会直接读取更新后的文件。 如果修改的是 Nginx 配置 (./nginx/conf/nginx.conf),需重启容器生效: docker compose restart group-buy-market-front Java 后端服务 (group-buying-sys) 代码位置:通过镜像构建(build 指定了 Dockerfile 路径)。 修改影响 如果修改了 Java 代码或依赖(如 pom.xml),必须重建镜像: docker compose up -d --build group-buying-sys 其他服务(MySQL/Redis/RabbitMQ/Nacos) 代码位置:均使用官方镜像,无业务代码。 修改影响 修改配置文件(如 ./redis/redis.conf)需重启容器: docker compose restart redis 无需 --build(除非你自定义了它们的镜像)。 压测 .服务器资源:2核心4GB 验证锁单接口:防超卖 Jmeter测试,一秒发1000次请求下: 可以发现,只有一开始的少部分的并发请求进入抢占库存,抢占失败会返回'拼团组队失败,缓存库存不足',后面'交易锁单拦截-xx'都是在第一层就被拦下了,即下单前的人数/库存校验。 如果仅要求“防超卖”,已经可以确保在资源有限时也不超卖。 但是在2核 4GB,服务只能稳定支撑 ≈240 QPS,平均响应 2 秒 测试查询拼团配置接口: ≈320 QPS 系统备忘录 本系统涉及微信和支付宝的回调。 1.微信扫码登录,*https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index*平台上配置了扫描通知地址,如果是本地测试,需要打开frp内网穿透,然后填的地址是frp建立通道的服务器端的ip:端口 2.支付宝,用户付款成功回调,也是同理,本地测试就要开frp。注意frp中的通道,默认是本地端口=远程端口,但是如果在服务器上部署了一套,那么远程的端口就会与frp的端口冲突!!!导致本地测试的时候失效。 锁单结算大致流程: 用户锁单-》支付宝付款-》成功后return_url设置了用户支付完毕后跳转回哪个地址是给前端用户看的; alipay_notify_url设置了支付成功后alipay调用你的后端哪个接口。 这里有小商城和拼团系统,notify_url指拼团系统中拼团达到指定人数后,通知小商城的HTTP地址,但是如果notify_type为MQ,则 notify_url为空,并且notify_mq非空,指明是拼团成功通知还是用户退单通知(topic.team_refund)。 如果不参与拼团,则小商城的支付回调会直接修改订单为deal_done,然后发一个'支付成功'消息,进入下一环节:发货。 若参与拼团,则RPC调用拼团系统中的'拼团交易结算'接口,增加拼团完成量、更新订单状态。 若拼团达到人数,发送拼团成功通知,小商场将订单中相应拼团的 status 都设置为deal_done,然后小商场发一个'支付成功'消息,进入下一环节:发货。 此处为粗略总结,详细的和退单流程见下文。 踩坑 Lua脚本问题(后面也没采用这种方式) long max = target + recovery; String lua = "local v = redis.call('INCR', KEYS[1])+1; " + "if tonumber(v) > tonumber(ARGV[1]) then " + " redis.call('DECR', KEYS[1]); " + " return 0; " + "end " + "return v;"; Long occupy = redisService.eval( lua, RScript.ReturnType.INTEGER, Collections.singletonList(teamOccupiedStockKey), max); 报错: org.redisson.client.RedisException: ERR Error running script (call to f_xxxx): @user_script:1: user_script:1: attempt to compare nil with number. 问题:max的值根本传不到 ARGV[1] 原因:因为我配置了一个全局默认的序列号器: config.setCodec(JsonJacksonCodec.INSTANCE); //用 Jackson 进行序列化 Lua脚本期望:原始字符串或数字参数 因此,需要对这块单独配置序列化器StringCodec(): redissonClient.getScript(new org.redisson.client.codec.StringCodec()).eval(xxx,xx....) 系统设计 在 DDD 中有一套共识的工程两阶段设计手段,包括;战略设计、战术设计。 战略设计:战略设计的核心是通过业务边界划分和上下文隔离,将复杂的业务系统拆分为多个高内聚、低耦合的限界上下文,并明确它们之间的交互方式(如通过领域事件、API、消息队列等)。 战术设计:战术设计关注如何在限界上下文内部,使用领域模型来表达业务逻辑,避免传统的贫血模型(Anemic Model)导致的复杂、难以维护的代码。 用例图 用例图(use case diagram)是用户与系统交互的最简表示形式,展现了用户和与他相关的用例之间的关系。它不仅反映了不同角色(如用户、运营)在系统中的职责边界和任务范围,还以可视化的方式呈现了系统提供的核心功能和服务,如同一份构建系统的战略蓝图。 四色建模图 MVC的困局:面向过程的“大通铺” 传统MVC开发是面向过程的,像一个大通铺,大家挤在一起。 为每个功能流程(A、B、C流程)编写代码,导致功能代码四处复制、杂乱交织,难以管理和复用。 DDD的解法:面向领域的“精装公寓” DDD通过领域建模,将系统划分为不同的领域(如活动域、人群标签配置域、交易域)。 这就像为每个家庭分配独立的公寓和房间,让代码各归其位,结构清晰,易于维护。 1.建模方法 建模的起点:从用户行为出发 DDD建模始于用户,分析其行为命令如何触发系统动作。 用例图是完美的起点,它直观展示了用户与系统的所有交互,帮助我们识别出所有关键行为。 统一的语言:协作的基石 建模过程需要产品、研发、测试等所有角色基于统一语言(如“拼团”、“成团”)进行协作。 四色建模/风暴模型是DDD的标准方法,旨在让所有参与者能共同理解和构建业务模型。 此图为事件风暴法指导图,通过寻找领域事件,发起事件命令,完成领域事件的过程,完成 DDD 工程建模。 蓝色 - 决策命令,是用户发起的行为动作,如;发起拼团Command、支付订单Command,是流程的起点。 黄色 - 领域事件,在领域内已经发生的、有业务意义的事实。如支付已成功Event、拼团已成功Event。,是流程的终点。 红色 - 业务流程,连接决策命令和领域事件的处理逻辑或业务规则。它接收命令,执行业务操作,并产生事件,如拼团成团策略(判断人数是否已满)、支付处理流程。 粉色 - 外部系统,流程中需要调用的第三方服务或系统,如支付宝支付、微信登录。 绿色 - 只读模型,做一些读取数据的动作,没有写库的操作,如拼团活动展示。 棕色 - 领域对象,承载业务数据和行为的核心对象,是命令操作的直接目标,包括实体、值对象、聚合根,如用户地址(值对象)。 综上,左下角的示意图。是一个用户,通过一个策略命令,使用领域对象,通过业务流程,完成2个领域事件,调用1次外部接口个过程。我们在整个 DDD 建模过程中,就是在寻找这些节点。 流程解析: 1.起点:用户意图(User),用户想要做一件事,比如“发起拼团”或“支付订单”。 2.动作:决策命令(Command),用户的意图被封装为一个具体的 Command(命令),通常包含执行该命令所需的所有数据。 3.核心:领域对象,命令不会凭空执行,它 必须作用于 一个具体的 领域对象(通常是聚合根 Aggregate)。这个对象是业务的核心载体,拥有数据和行为。 4.执行:业务流程,领域对象根据自身的业务规则来处理接收到的命令。这个过程会修改对象自身的状态(如减少库存),并封装了最核心的业务逻辑。 5.结果:领域事件,业务执行成功后,会产生一个或多个领域事件。 6.扩展:调用外部系统,产生的领域事件可能会触发后续动作,其中之一就是调用外部系统。这是系统与外界协作的方式。 7.展示:读模型,负责提供数据查询功能。它通常通过监听领域事件来更新自己的数据视图,确保用户能看到最新的状态 2.寻找领域事件 寻找领域事件的过程,就是寻找系统中流程节点的结果态。什么结束了、什么完成了、什么终止。这个过程就是一堆人头脑风暴的过程,避免错失流程节点。 比如:发起拼团完成、支付完成、参与拼团完成、拼团目标达成、回调通知完成... 3.划分领域 在确定了领域事件以后,接下来要做的就是通过决策命令串联领域事件,并填充上所需要的领域对象。 首先,通过用户的行为动作,也就是决策命令,串联到对应的领域事件上。并对复杂的流程提供出红色的业务流程。 之后,为决策命令添加领域对象,每一个领域在整个流程中都起到了至关重要的作用。 有了识别出来的领域角色的流程,就可以非常容易的划分出领域边界了。 观察串联好的流程和聚集的领域对象,功能紧密相关、数据频繁交互的一组对象和事件自然形成一个领域。 例如: 所有与成团逻辑相关的命令、事件、实体(如拼团锁单、拼团结算)、策略(如成团校验策略)可以划归为 拼团域。 所有与活动相关的,比如活动配置信息、商品试算优惠价格,都可以划分为活动域。 4.简易流程图 首先,站在运营的角度,要为这次拼团配置对应的拼团活动。那么就会涉及到;给哪个渠道的什么商品ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商品所提供的规则信息,包括:折扣、起止时间、人数等。还要拿到折扣的一个试算金额。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。 那么,拼团活动表,为什么会把折扣拆分出来呢。因为这里的折扣可能有多种迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Bitmap,并为这批用户打上可配置的人群标签。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。 之后,站在用户的角度,是参与拼团。首次发起一个拼团或者参与已存在的拼团进行数据的记录,达成拼团约定拼团人数后,开始进行通知。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。 系统表设计 group_buy_activity(拼团活动) 字段名 说明 id 自增 activity_id 活动ID activity_name 活动名称 discount_id 折扣ID group_type 成团方式(0自动成团、1达成目标成团) take_limit_count 拼团次数限制 target 拼团目标 valid_time 拼团时长(分钟) status 活动状态(0创建、1生效、2过期、3废弃) start_time 活动开始时间 end_time 活动结束时间 tag_id 人群标签规则标识 tag_scope 人群标签规则范围(多选;1可见限制、2参与限制) create_time 创建时间 update_time 更新时间 group_buy_discount(折扣配置) 字段名 说明 id 自增ID discount_id 折扣ID discount_name 折扣标题 discount_desc 折扣描述 discount_type 折扣类型(0:base、1:tag) market_plan 营销优惠计划(ZJ:直减、MJ:满减、ZK:折扣、N元购) market_expr 营销优惠表达式 tag_id 人群标签(特定优惠限定) create_time 创建时间 update_time 更新时间 group_buy_order(拼团订单表) 字段名 说明 id 自增ID team_id 拼单组队ID activity_id 活动ID source 渠道 channel 来源 original_price 原始价格 deduction_price 折扣金额 pay_price 支付价格 target_count 目标数量 complete_count 完成数量 lock_count 锁单数量 status 状态(0拼单中、1完成、2失败、3完成-含退单) valid_start_time 拼团开始时间 valid_end_time 拼团结束时间 notify_type 回调类型(HTTP、MQ) notify_url 回调地址(HTTP 回调不可为空) create_time 创建时间 update_time 更新时间 group_buy_order_list(拼团订单明细表) 字段名 说明 id 自增ID user_id 用户ID team_id 拼单组队ID order_id 订单ID activity_id 活动ID start_time 锁单时间 end_time 最晚锁单时间 valid_end_time 拼团结束时间 goods_id 商品ID source 渠道 channel 来源 original_price 原始价格 deduction_price 折扣金额 pay_price 支付金额 status 状态(0初始锁定、1消费完成、2用户退单) out_trade_no 外部交易单号(幂等) create_time 创建时间 update_time 更新时间 biz_id 业务唯一ID out_trade_time 外部交易时间 notify_task(回调任务) 字段名 说明 id 自增ID activity_id 活动ID team_id 拼单组队ID notify_category 回调种类(trade_unpaid2refund) notify_type 回调类型(HTTP、MQ) notify_mq 回调消息 notify_url 回调接口 notify_count 回调次数 notify_status 回调状态(0初始、1完成、2重试、3失败) parameter_json 参数对象 uuid 唯一标识 create_time 创建时间 update_time 更新时间 crowd_tags(人群标签) 字段名 说明 id 自增ID tag_id 人群ID tag_name 人群名称 tag_desc 人群描述 statistics 人群标签统计量 create_time 创建时间 update_time 更新时间 crowd_tags_detail(人群标签明细) 字段名 说明 id 自增ID tag_id 人群ID user_id 用户ID create_time 创建时间 update_time 更新时间 crowd_tags_job(人群标签任务) 字段名 说明 id 自增ID tag_id 标签ID batch_id 批次ID tag_type 标签类型(参与量、消费金额) tag_rule 标签规则(限定类型 N次) stat_start_time 统计数据开始时间 stat_end_time 统计数据结束时间 status 状态(0初始、1计划、2重置、3完成) create_time 创建时间 update_time 更新时间 sc_sku_activity(渠道商品活动配置关联表) 字段名 说明 id 自增ID source 渠道 channel 来源 activity_id 活动ID goods_id 商品ID create_time 创建时间 update_time 更新时间 sku(商品信息) 字段名 说明 id 自增ID source 渠道 channel 来源 goods_id 商品ID goods_name 商品名称 original_price 商品价格 create_time 创建时间 update_time 更新时间 DDD架构设计 MVC架构: DDD架构: 价格试算与人群标签 活动是否允许用户参与,拼团的判断逻辑有两重,具体条件如下: 活动是否设置了 tag_scope tag_scope 用于限制活动参与的范围。若活动未设置 tag_scope,则默认认为没有任何限制,所有用户均可参与拼团;若配置了 tag_scope,则需要根据该配置进一步判断用户是否符合参与条件。 用户是否在指定的人群标签 tag_id 范围内 tag_id 指定了本次活动的参与人群,只有拥有该标签的人群才能参与活动(具体逻辑就是每个tagid的位图里存了很多userid,只有这些userid才能参与)。如果活动未配置 tag_id,则默认所有用户都可参与拼团。 需要注意的是,在本项目的实现中,虽然活动配置了 tag_id,但由于位图(bitmap)未进行配置,实际上也是默认所有用户均可参与拼团。 ps:这里只校验用户是否有参与活动的资格!!! 后续还有锁单的校验,注意区分,锁单是基于这里的资格判断之后的,再去此时活动是否仍有效、用户参与拼团次数是否已达上限... 价格试算流程 使用了规则树的设计模式,详情请见 拼图设计模式 IndexGroupBuyMarketService │ │ indexMarketTrial() ▼ DefaultActivityStrategyFactory │ (return rootNode) ▼ RootNode.apply() │ doApply() (执行) │ router() (路由到下一node) ▼ SwitchNode.apply() │ ... ▼ MarketNode.apply() ... (可能还有其他节点) ▼ EndNode.apply() → 组装结果并返回 TrialBalanceEntity ▲ └────────── 最终一路向上 return IndexGroupBuyMarketService 是领域服务,整个价格试算的入口 DefaultActivityStrategyFactory 帮你拿到 根节点,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。 DynamicContext 是一次性创建的共享上下文:谁需要谁就往里放 优惠策略配置 目前项目中是单策略模式,即满减、直减、折扣 这些优惠 N选一 ;未来可能需要支持 多种优惠组合(例如“满减 + 优惠券 + 折扣”),因此需要一种 可扩展的优惠计算策略体系。 1.组合策略(静态组合) 最简单的实现方式是为每种优惠组合定义一个组合类,例如“满减 + 优惠券”: @Service("MJ_COUPON") public class MJCouponCalculateService extends AbstractDiscountCalculateService { @Resource private MJCalculateService mjCalculateService; @Resource private CouponCalculateService couponCalculateService; @Override public BigDecimal doCalculate(BigDecimal originalPrice, GroupBuyActivityDiscountVO.GroupBuyDiscount groupBuyDiscount) { // 先满减 BigDecimal afterMJ = mjCalculateService.doCalculate(originalPrice, groupBuyDiscount); // 再用优惠券 return couponCalculateService.doCalculate(afterMJ, groupBuyDiscount); } } 问题:但是如果以后有更多组合(比如“满减+直减+优惠券”),会出现类爆炸,扩展性差。 2.动态策略组合(推荐方案) 通过配置文件或数据库指定策略执行顺序,例如:["MJ", "COUPON", "DISCOUNT"] 编写通用组合类,根据配置顺序依次执行各策略: public class CompositeDiscountService extends AbstractDiscountCalculateService { private final List<IDiscountCalculateService> strategies; @Override public BigDecimal doCalculate(BigDecimal originalPrice, GroupBuyActivityDiscountVO.GroupBuyDiscount discount) { BigDecimal price = originalPrice; for (IDiscountCalculateService s : strategies) { price = s.calculate("userId", price, discount); } return price; } } 这种设计支持任意顺序与动态扩展,避免硬编码。 策略执行逻辑配置方式 (1)固定优先级(非动态计算) 由运营或产品预先定义策略执行顺序,例如:例如强制规定 满减 → 直减 → 折扣,避免计算所有排列组合。 优点:性能高,规则可控。适用场景:优惠策略较少或业务方明确要求顺序。 (2)动态计算最优解 系统自动枚举可叠加的优惠组合,有限枚举 + 剪枝优化,仅对允许叠加的策略枚举顺序,并通过规则提前排除无效组合(如互斥优惠)。 优点:灵活性高,用户获利最大化。 假设总价 300元,可用优惠三选二: 满 200减 50. 满 300打 8折. 直减 20元 顺序 计算过程 结果 满减 → 折扣 (300-50)*0.8 200 满减 → 直减 (300-50)-20 230 折扣 → 满减 (300*0.8)-50 190 ← 最优 折扣 → 直减 (300*0.8)-20 220 直减 → 满减 (300-20) -50 230 直减 → 折扣 (300-20)*0.8 224 (3)分层优惠 总价 │ ├─ 第一阶段:全局优惠(如全场8折) │ ├─ 第二阶段:品类优惠(如家电满1000减100) │ └─ 第三阶段:单品优惠(如A商品直降50) 人群标签 在规则树的TagNode节点中,需要判断当前请求用户是否在位图中(目标人群)。 人群标签采集 步骤 目的 说明 1. 记录日志 标明本次批次任务的开始 方便后续排查、链路追踪 2. 读取批次配置 拿到该批次统计范围、规则、时间窗等 若返回 null 通常代表批次号错误或已被清理 3. 采集候选用户 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 4. 双写标签明细 将每个用户与标签的关系永久化 & 提供实时校验能力 方法内部两件事:• 插入 crowd_tags_detail 表• 在 Redis BitMap 中把该用户对应位设为 1(幂等处理冲突) 5. 更新统计量 维护标签当前命中人数,用于运营看板 这里简单按“新增条数”累加,也可改为重新 count(*) 全量回填 6. 结束 方法返回 void 如果过程抛异常,调度系统可重试/报警 一句话总结 这是一个被定时器或消息触发的离线批量打标签任务: 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。 之后业务系统就能用位图做到毫秒级 isUserInTag(userId, tagId) 判断,实现精准运营投放。 Bitmap(位图) 概念 Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。 为什么用 Bitmap? 超高空间效率:1000 万个用户,只需要约 10 MB(1000 万 / 8)。 超快操作:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。 存储方式 bitmap.set(123) 的含义就是把 第 123 位 (bit) 标记为 1。 在底层实现上,Bitmap 通常用一段连续的二进制数组(比如 int[] 或 byte[])来存储: 如果用 int 数组存储:每个 int 占 32 bit(在 Java/C++ 等语言里)。 第 123 个 bit 属于第 123 / 32 = 3 个整型元素(下标从 0 开始)。 在这个元素里具体是哪一位呢?就是 123 % 32 = 27 这位。 所以实际上是 array[3] 的第 27 个 bit 被置 1。 如果用 byte 数组存储:每个 byte 占 8 bit。 第 123 个 bit 属于第 123 / 8 = 15 个字节。 在这个字节里具体位置是 123 % 8 = 3。 所以是 array[15] 的第 3 位被置 1。 Bitmap人群标签思路 法一: 把 userid 用 MD5 映射到了一个固定的整数区间 [0, Integer.MAX_VALUE),即约 21 亿个可能的位置。 MD5(UUID) → 128 位哈希值=>转成正整数=>对 Integer.MAX_VALUE(≈2.1×10⁹)取模=>结果就是 bitmap 下标 index。 ≈ 256 MB 的位图 default int getIndexFromUserId(String userId) { try { MessageDigest md = MessageDigest.getInstance("MD5"); byte[] hashBytes = md.digest(userId.getBytes(StandardCharsets.UTF_8)); // 将哈希字节数组转换为正整数 BigInteger bigInt = new BigInteger(1, hashBytes); // 取模以确保索引在合理范围内 return bigInt.mod(BigInteger.valueOf(Integer.MAX_VALUE)).intValue(); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("MD5 algorithm not found", e); } } MD5有128位,只能BigInteger来接收。 这个方法会出现假阳性(非目标用户被误判为在)。减轻办法: 布隆过滤器 核心思想:用 多个哈希函数 来降低冲突,不消除碰撞本质。 具体做法: 对 userId 用 k 个不同的 hash 函数(可以是 MD5 的不同切片、或 MurmurHash 等)。 得到 k 个位置,把这些位置的 bit 全部设为 1。 判断存在性时,只要这 k 个位置都为 1,就认为“可能存在”;只要有一个为 0,就一定不存在。 这样虽然依然有假阳性(可能存在其实不存在),但概率大大降低。 判断是否是否存在,如果任意一个bit=0 =》一定不存在;如果所有bit=1=》可能存在。 法二: 如果用户是 UUID,我不会直接拿 UUID 取模进 bitmap,因为那样一定会有哈希冲突。想做到精确集合、零误判,我会先在系统中维护一份稳定的 UUID 到稠密整型 ID 的映射表。 每个 UUID 在首次出现时分配一个连续的整型 ID,比如从 0 开始自增,这样我们就把原本稀疏的 128 位空间压缩成 0 到 N-1 的稠密索引。之后,bitmap 的第 ID 位就代表该用户是否在目标人群。 **查询流程也很简单:**先通过映射表把 UUID 转成 ID,然后直接在 bitmap 上判断对应那一位是否为 1。这样整个体系是 O(1) 的查写效率,完全无冲突,而且空间极省——一千万人也就一两兆。 映射表这层大概两三百兆,可以放在 Redis 或 RocksDB 里,全局复用。 追问:那我直接在redis中用set存储目标用户的uuid不可以吗?为什么还要先通过映射表,再查bitmap? 答:映射表只是一个全局、长期复用的索引层。它的空间开销固定、规模稳定。我们后面的人群 bitmap 可能有上千份,对应着不同的目标人群分类!!!,但它们都共用这一份映射表。一次投入,多次使用。 人群标签过滤 白名单。 无 tagId(没配标签)→ 不限人群,全部放行(visible=true, enable=true)。 有 tagId 且位图存在 → 位图里的人可以参加(白名单)。 有 tagId 但位图不存在 → 现在的实现是默认全放行(把“未配置位图”当作“不限制”),因为真实场景中由外部系统统计用户行为 => 将符合条件的用户放入位图中,这里暂时没有模拟。 动态降级与人群切量 downgradeSwitch —— 降级开关 作用:在出现异常或高压场景时,主动关闭部分功能,保证核心流程可用。 值为 0(默认):功能正常,系统按照全量逻辑执行。 值为 1:开启降级,比如: 关闭一些非核心功能(如推荐、统计、日志落库)。 使用兜底方案(如直接返回默认值、提示“稍后再试”)。 cutRange —— 人群切量开关 作用:做灰度发布或分流测试,让不同用户群体验不同的功能版本。 默认值为 100:表示 100% 用户都可用,即全量发布。 如果设置为 30:就表示 只有 30% 的用户能进入新功能,其他 70% 用户还是老逻辑。 计算逻辑:对用户 ID 做哈希,取模 100,落在 [0, cutRange] 范围内的用户通过。 public boolean isCutRange(String userId) { // 计算哈希码的绝对值 int hashCode = Math.abs(userId.hashCode()); // 获取最后两位 int lastTwoDigits = hashCode % 100; // 判断是否在切量范围内 // 在范围内,可以继续参加活动 if (lastTwoDigits <= Integer.parseInt(cutRange)) { return true; } return false; } 不要直接对用户 ID 取模,因为可能是String类型的。 拼团交易锁单 下单到支付中间有一个流程,即锁单,比如淘宝京东中,在这个环节(限定时间内)选择使用优惠券、京豆等,可以得到优惠价,再进行支付;拼团场景同理,先加入拼团,进行锁单,然后优惠试算,最后才付款。 锁单流程: 1.幂等查询,如果已有一模一样的锁单,直接返回该条记录;(见下文防止重复下单 ) 2.拼团人数校验(前端显示有滞后性,在调用锁单接口的时候还要重新拉取一下) 3.优惠试算,查看拼团活动配置信息(优惠价、目标人群、活动有效期、最大参与次数...)。 4.人群限定,非目标人群不允许参与活动。 5.锁单责任链 活动有效性 用户参与次数 剩余库存校验(见下文 防超卖 ) 拼团结算 结算规则过滤:SC渠道拦截、外部交易单号交易、结算时间校验(now小于拼团结束时间) 对接商城和拼团系统 下单总体流程 查询商品并初始化订单 查询商品信息,构建订单,填入 total_amount,此时订单状态为 PAY_CREATE。 判断订单类型 普通下单:直接进入预支付流程。 拼团下单/开团:远程调用拼团系统,执行锁单逻辑(活动校验、库存校验、优惠计算等)。 生成预支付订单 根据订单类型决定支付金额: 普通单:按商品原价。 拼团单:按优惠后价格。 创建支付单,填入 pay_amount、pay_url 等信息,订单状态置为 PAY_WAIT。 等待支付回调 用户扫码/支付成功后,支付平台回调商城接口,更新订单状态。 超时未支付订单由调度任务关闭。 具体业务步骤 1. 用户下单 如果用户已存在未支付订单: 且有支付链接(pay_url) → 直接返回支付链接。 没有支付链接 → 进入支付单创建流程。 否则,进入新订单创建。 2. 创建订单 查询商品信息并保存新订单(状态 PAY_CREATE)。 若为拼团单(marketType == GROUP_BUY_MARKET),调用拼团系统执行 营销锁单 校验活动有效性 校验用户参与次数 校验剩余库存 优惠试算 记录拼团锁单结果(订单号、折扣金额等) 普通订单跳过营销锁单。 3. 创建预支付单 拼团单:根据优惠结果生成预支付订单。 普通单:直接用原价生成预支付订单。 更新订单状态为 PAY_WAIT,返回支付链接。 支付完成与组队结算 1.支付回调 更新订单状态 触发“支付结算并发货”流程 2.组队结算判断 调用拼团营销系统组队结算接口,更新当前拼团完成人数 判断该拼团是否已完成: 是: 调用营销结算 HTTP 接口 结算完成 N 个用户组成的队伍 发送“组队完成回调通知” 否:直接结束流程 3.后续发货 当收到拼团完成(complete_count==target_count)的回调消息时,小型商城执行后续交易结算及发货逻辑(目前是模拟触发的)。 注意 alipay_notify_url 作用:支付宝在用户支付成功后,向该地址发起服务器端回调(需公网可访问,或通过内网穿透映射到本地)。 调用流程:支付宝 → pay-mall 用途:pay-mall 接收到支付成功通知后,可以调用拼团组队结算接口。 与之相关的两个地址: return_url:用户付款后网页自动跳转的地址(通常是返回商城首页),属于前端页面跳转,与业务结算无关。 gateway_url:支付宝提供的商户收款页面地址(用户发起付款时访问)。 group-buy-market_notify_url http://127.0.0.1:8092/api/v1/alipay/group_buy_notify 注意!HTTP调用下才使用,MQ这个字段失效! 作用:由 pay-mall 商城设置,作为拼团平台的回调地址。 调用流程:拼团平台(group-buy-market) → pay-mall 触发条件:某个 teamId 的拼团人数达到目标值,拼团成功。 用途:通知 pay-mall 对该 teamId 下所有成员执行后续操作,例如发货。 本地对接 在 group-buying-sys 项目中,对 group-buying-api 模块执行 mvn clean install(或在 IDE 中运行 install)。这会将该模块的 jar 安装到本地 Maven 仓库(~/.m2/repository)。然后在 pay-mall 项目的 pom.xml 中添加依赖,使用相同的 groupId、artifactId 和 version 即可引用该模块,如下所示: <dependency> <groupId>edu.whut</groupId> <artifactId>group-buying-api</artifactId> <version>1.0.0-SNAPSHOT</version> </dependency> 发包 仅适用于本地,共用一个本地Maven仓库,一旦换台电脑或者在云服务器上部署,无法就这样引入,因此可以进行发包。这里使用阿里云效发包https://packages.aliyun.com/ 1)点击制品仓库->生产库 2)下载settings-aliyun.xml文件并保存至本地的Maven的conf文件夹中。 3) 配置项目的Maven仓库为阿里云提供的这个,而不是自己的本地仓库。 4)发包,打开Idea中的Maven,双击deploy 5)验证 6)使用 将公共镜像仓库的settings文件和阿里云效的settings文件合并,可以同时拉取公有依赖和私有包。 逆向工程:退单 逆向的流程,要分析用户是在哪个流程节点下进行退单行为。包括3个场景; 已锁单、未支付:redis恢复量+1,mysql中锁单量-1 已锁单、已支付,但拼团未成团:redis恢复量+1,mysql中锁单量、完成量-1,退款 已锁单、已支付,且拼团已成团:redis恢复量无需+1,因为成团之后不开放给别人;mysql中锁单量、完成量-1,退款,拼团设置为'已完成含退单'状态,但拼团中所有人都退单,更新为失败! 核心流程说明 阶段一:退单操作流程 客户主动提交退单请求 通过责任链模式处理:数据加载Node(查询订单) → 重复检查Node(防止重复退单) → 策略执行Node 策略选择 根据订单状态和拼团状态选择对应退单策略(三种之一) 执行退单 更新数据库操作(锁单量、完成量、拼团状态、订单状态...) 消息通知 + 任务补偿 发送MQ退单消息通知(未支付退单、已支付未成团...三种消息 notify_category) 将消息写入notify_task表,定时任务扫描未成功处理的消息,以做补偿兜底。 阶段二:库存恢复流程 消息监听 MQ监听器接收退单成功消息 服务调用 调用恢复库存服务 策略选择 根据退单类型选择对应策略(已成团的无需恢复了,反正新用户也无法再参与该拼团) 库存恢复 执行Redis库存恢复操作(带分布式锁保护) 设计模式应用 责任链模式 TradeRefundRuleFilterFactory 构建的过滤链: DataNodeFilter → UniqueRefundNodeFilter → RefundOrderNodeFilter 策略模式 策略接口:RefundOrderStrategy 实现策略: Unpaid2RefundStrategy(未付款退单的流程) Paid2RefundStrategy(已付款退单) PaidTeam2RefundStrategy(已成团退单) 工厂模式 TradeRefundRuleFilterFactory 负责组装责任链 模板方法模式 AbstractRefundOrderStrategy 提供: 公共方法封装 (发送退单MQ消息、库存恢复redis) 依赖注入支持 退单触发入口 1)用户主动退单 2)定时任务,定时任务扫描锁单但未结算的订单,若支付时间超过设定值,对这笔订单执行退单操作。 注意:小型支付商城中的订单可能有些是普通订单,有些是拼团订单。 对于普通订单,无需调用拼团系统中的退单接口,自己本地退单,对于CREATE或PAY_WAIT状态的订单,直接修改订单状态为CLOSED;对于PAY_SUCCESS(个人支付完成)、DEAL_DONE,额外调用支付宝退款。 对于拼团订单,RPC调用拼团系统的退单接口,调用成功后设置订单为WAIT_REFUND,然后由MQ消息回调调用支付宝退款。 定时任务+MQ消息通知 定时任务 拼团营销系统: 1.MQ消息补偿,每天零点执行一次(暂定) //每天零点执行一次 @Scheduled(cron = "0 0 0 * * ?") public void exec() { // 为什么加锁?分布式应用N台机器部署互备(一个应用实例挂了,还有另外可用的),任务调度会有N个同时执行,那么这里需要增加抢占机制,谁抢占到谁就执行。完毕后,下一轮继续抢占。 // 获取锁句柄,并未真正获取锁 RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec"); try { //尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取; // leaseTime = 0:不设过期时间,看门狗机制 boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS); if (!isLocked) return; Map<String, Integer> result = tradeTaskService.execNotifyJob(); log.info("定时任务,回调通知完成 result:{}", JSON.toJSONString(result)); } catch (Exception e) { log.error("定时任务,回调通知失败", e); } finally { if (lock.isLocked() && lock.isHeldByCurrentThread()) { lock.unlock(); } } } 2.超时未支付订单扫描,每隔5分钟执行一次;主要就是营销锁单了,但是15分之内还没付款,自动调用退单逻辑,释放锁单量,然后发退单的MQ消息。 小型支付商城: 1.支付宝回调补偿,未支付订单扫描,每隔10秒调用一次支付宝的接口,查询某未支付的订单到底付了没有,如果付了,则更新订单状态。主要是为了防止用户付了钱,但是由于网络波动,导致支付宝调用系统的回调接口失败,做的一次补偿动作。 2.超时订单扫描,每3分钟执行一次,对于超过15分钟仍未付款的订单,将其关闭。 待优化:将定时轮询查询改为在每个用户下单时发一个延迟消息的事件触发方式。 特性 定时轮询查询 延迟消息(事件触发) 优胜方 实时性 差(取决于轮询间隔,如1分钟) 高(理论上精确到秒) 延迟消息 数据库压力 巨大(高频扫描全表) 极小(只查单条记录) 延迟消息 可靠性 高(逻辑简单,不易丢单) 中(依赖MQ的可靠性) 定时轮询 扩展性 差(订单量越大,性能越差) 好(天然分布式,随订单量线性扩展) 延迟消息 复杂度 低(实现简单) 中(需引入和维护MQ) 定时轮询 资源利用率 低(大量无效查询) 高(按需触发,无浪费) 延迟消息 MQ消息 有三种MQ消息: 1.退单消息 2.拼团组队成功消息 3.订单支付成功消息 退单消息:拼团系统发送,拼团订单。拼团系统发送,小型商城和拼团系统都接收,各自执行退单流程。 组队成功消息:拼团系统发送,拼团订单。拼团系统发送,小型商城和拼团系统都接收,小型商城更新订单状态;拼团系统仅仅是简单的打印一下'通知成功'消息。 订单支付成功消息:小型商城发送,普通订单则用户支付后的回调就发送;拼团订单则是先接到'组队成功消息'之后 再发MQ。小型商城接收,更新订单状态为模拟发货。 这里主要起到解耦的作用,将发货这个过程解耦。 不仅在相关接口完成的时候自动发送MQ消息,同时有兜底,将MQ消息持久化进Mysql,设置定时任务来扫描表,对暂未处理(处理失败)的MQ消息重新投递。 字段名 类型 允许为空 默认值 约束 / 备注 id int UNSIGNED NO AUTO_INCREMENT 自增ID,主键 activity_id bigint NO 活动ID team_id varchar(8) NO 拼单组队ID notify_category varchar(64) YES NULL 回调种类 notify_type varchar(8) NO 'HTTP' 回调类型(HTTP、MQ) notify_mq varchar(32) YES NULL 回调消息 notify_url varchar(128) YES NULL 回调接口 notify_count int NO 回调次数 notify_status tinyint(1) NO 回调状态【0 初始、1 完成、2 重试、3 失败】 parameter_json varchar(256) NO 参数对象(JSON 字符串) uuid varchar(128) NO 唯一标识 create_time datetime NO CURRENT_TIMESTAMP 创建时间 update_time datetime NO CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 更新时间 如何确保MQ消息持久化成功? // 4. 更新数据库,拼团交易结算,若达到拼团人数,返回notifyTaskEntity发送回调通知,否则返回null不做处理 NotifyTaskEntity notifyTaskEntity =repository.settlementMarketPayOrder(groupBuyTeamSettlementAggregate); // 5. 组队回调处理 - 处理失败也会有定时任务补偿,通过这样的方式,可以减轻任务调度,提高时效性 if (null != notifyTaskEntity) { threadPoolExecutor.execute(() -> { Map<String, Integer> notifyResultMap = null; try { notifyResultMap = tradeTaskService.execNotifyJob(notifyTaskEntity); log.info("回调通知拼团完结 result:{}", JSON.toJSONString(notifyResultMap)); } catch (Exception e) { log.error("回调通知拼团完结失败 result:{}", JSON.toJSONString(notifyResultMap), e); throw new AppException(e.getMessage()); } }); } 在拼团支付成功后的结算过程中(repository.settlementMarketPayOrder),所有数据库操作(更新状态、更新拼团人数、持久化拼团成功消息)都被包含在一个事务内。通过 @Transactional 注解保证了事务的一致性,确保了操作的原子性。 如果任何步骤失败,事务会回滚,数据保持一致。 repository.settlementMarketPayOrder 执行失败的话,后面也不会发送MQ消息了。 如果操作是幂等的,并且失败是由于 暂时性故障(如数据库连接失败、网络问题等),那么可以引入 重试机制 来增加系统的容错性。 如何衡量消息是否成功发送? private Map<String, Integer> execNotifyJob(List<NotifyTaskEntity> notifyTaskEntityList) throws Exception { //successCount:成功回调的任务数量 int successCount = 0, errorCount = 0, retryCount = 0; for (NotifyTaskEntity notifyTask : notifyTaskEntityList) { // HTTP模式下回调小商城中的groupBuyNotify接口 success 成功,error 失败 String response = port.groupBuyNotify(notifyTask); // 更新状态判断&变更数据库表回调任务状态 if (NotifyTaskHTTPEnumVO.SUCCESS.getCode().equals(response)) { int updateCount = repository.updateNotifyTaskStatusSuccess(notifyTask); if (1 == updateCount) { successCount += 1; } } else if (NotifyTaskHTTPEnumVO.ERROR.getCode().equals(response)) { if (notifyTask.getNotifyCount() < 5) { // 失败但可以重试 → 标记为 RETRY,等待下一次收集 “待处理的通知任务列表” if (repository.updateNotifyTaskStatusRetry(notifyTask) == 1) { retryCount++; } } else { // 已达最大重试次数 → 标记为 ERROR(不再重试) if (repository.updateNotifyTaskStatusError(notifyTask) == 1) { errorCount++; } } } } 目前逻辑比较简单,只能确保消息发送出去了,如果为了提高安全性,还需要: 1.发送方确认机制(ConfirmCallback、returnCallback) 2.消费方确认机制,比如把auto ACK改为manul ACK,配置无状态重试/有状态重试(需要对消息做幂等性处理),超过最大重试次数的消息进入死信队列中,等待人工审查。 3.消费方成功收到消息并将消息表中的对应消息的status设置为'已完成',而不是发送者来写。 收获 实体对象 实体是指具有唯一标识的业务对象。 在 DDD 分层里,Domain Entity ≠ 数据库 PO。 在 edu.whut.domain.*.model.entity 包下放的是纯粹的业务对象,它们只表达业务语义(团队 ID、活动时间、优惠金额……),对「数据持久化细节」保持无感知。因此它们看起来“字段不全”是正常的: 它们不会带 @TableName / @TableId 等 MyBatis-Plus 注解; 也不会出现数据库的技术字段(id、create_time、update_time、status 等); 只保留聚合根真正需要的业务属性与行为。 @Data @Builder @AllArgsConstructor @NoArgsConstructor public class PayActivityEntity { /** 拼单组队ID */ private String teamId; /** 活动ID */ private Long activityId; /** 活动名称 */ private String activityName; /** 拼团开始时间 */ private Date startTime; /** 拼团结束时间 */ private Date endTime; /** 目标数量 */ private Integer targetCount; } 这个也是实体对象,因为多个字段的组合: teamId 和 activityId 能唯一标识这个实体。 多线程异步调用 如果某任务比较耗时(如加载大量数据),可以考虑开多线程异步调用。 创建线程池 ThreadPoolExecutor executor = new ThreadPoolExecutor( corePoolSize, // 核心线程数,常驻 maxPoolSize, // 最大线程数 keepAliveTime, // 空闲线程存活时间 TimeUnit.SECONDS, // 时间单位 new LinkedBlockingQueue<>(100), // 有界任务队列 Executors.defaultThreadFactory(), // 线程工厂,默认命名 pool-1-thread-x new ThreadPoolExecutor.AbortPolicy() // 拒绝策略,队列满时抛异常 ); 注意:生产环境建议使用有界队列,避免内存溢出;拒绝策略可选 CallerRunsPolicy 等实现背压。 提交任务 在 ThreadPoolExecutor 中,你可以用 两种方式提交任务: execute(Runnable):提交不需要返回值的任务。 submit(Runnable):也可以传 Runnable,但会返回一个 Future<?>,future.get() 得到 null,常用于等待任务完成或捕获异常。 submit(Callable):提交需要返回值的任务,返回 Future。 // 1) Runnable + execute:无返回值,无法感知异常 executor.execute(() -> { try { System.out.println(Thread.currentThread().getName()); } catch (Exception e) { e.printStackTrace(); } }); // 2) Runnable + submit:返回 Future,可用来等待或捕获异常 Future<?> f1 = executor.submit(() -> { System.out.println("Runnable 任务"); // int x = 1 / 0; // 如果抛异常,在 f1.get() 时感知 }); f1.get(); // 返回 null;若任务抛异常,这里会抛 ExecutionException // 3) Callable + submit:有返回值,可抛异常 Future<String> f2 = executor.submit(() -> { TimeUnit.MILLISECONDS.sleep(200); return "任务完成"; }); System.out.println(f2.get()); // 拿到返回值;若任务抛异常,这里会抛 ExecutionException executor是ThreadPoolExecutor 实例,调用 execute/submit 后,线程池会把任务放入队列,并自动选择线程执行,执行完后线程复用,不会频繁创建销毁。 什么是 Future? 当你用 submit() 提交任务时,线程池会立即返回一个 Future 对象,表示“任务的未来结果”。 你可以通过这个 Future: 获取任务的执行结果 判断任务是否完成 取消任务 获取任务抛出的异常 V get() // 阻塞,直到任务执行完成,返回结果或抛异常 V get(long timeout, TimeUnit unit) // 阻塞指定时间,超时抛 TimeoutException boolean cancel(boolean mayInterruptIfRunning) // 取消任务 boolean isDone() // 判断任务是否完成 什么是FutureTask 同时实现了 Runnable 和 Future 两个接口。它既是一个 任务(能被线程或线程池执行),又是一个 Future(能拿到异步结果)。 FutureTask = Runnable + Future import java.util.concurrent.*; public class FutureTaskDemo2 { public static void main(String[] args) throws Exception { ExecutorService executor = Executors.newFixedThreadPool(2); Callable<String> task = () -> { Thread.sleep(1000); return "Hello from FutureTask"; }; FutureTask<String> futureTask = new FutureTask<>(task); // 线程池执行 FutureTask executor.execute(futureTask); // 获取结果 String result = futureTask.get(); System.out.println("结果: " + result); executor.shutdown(); } } 相当于直接拿futureTask.get()获得结果,而不是: Future<Integer> f = executor.submit(callable); Integer result = f.get(); 动态配置(热更新) BeanPostProcessor 是 Spring 提供的一个扩展接口,用来在 Spring 容器实例化 Bean(并完成依赖注入)之后,但 在调用 Bean 的初始化方法之前或之后,对 Bean 进行额外的加工处理。 Spring 容器启动时会扫描并实例化所有实现了 BeanPostProcessor 接口的 Bean,然后在Bean 初始化阶段前后依次调用它们的 postProcessBeforeInitialization 和 postProcessAfterInitialization 方法。 postProcessAfterInitialization返回你修改之后的bean实例。 **原理:**利用 Redis 的发布/订阅(Pub/Sub)机制,在程序运行时动态推送配置变更通知,订阅者接收到消息后更新相应的 Bean 字段。通过 反射(Reflection API) 可以 动态修改运行中的对象实例的字段值。 实现步骤 注解标记 用 @DCCValue("key:default") 标注需要动态注入的字段,指定 Redis Key 和默认值。 // 标记要动态注入的字段 @Retention(RUNTIME) @Target(FIELD) public @interface DCCValue { String value(); // "key:default" } // 业务使用示例 @Service public class MyFeature { @DCCValue("myFlag:0") //标注字段,默认值为0 private String myFlag; public boolean enabled() { return "1".equals(myFlag); } } 启动时注入 代码位置:app/config 实现 BeanPostProcessor,覆写postProcessAfterInitialization方法,在每个 Spring Bean 初始化后自动执行: 扫描标注了 @DCCValue 的字段; 拼接完整 Redis Key,若 Redis 中没有配置,则写入默认值(即@DCCValue注解上的值); 通过反射将配置值注入到 Bean 的字段; 将配置与 Bean 映射关系存入本地HashMap,以便后续热更新。 @Override public Object postProcessAfterInitialization(Object bean, String name) { private final Map<String, Object> dccObjGroup = new HashMap<>(); Class<?> cls = AopUtils.isAopProxy(bean) ? AopUtils.getTargetClass(bean) : bean.getClass(); for (Field f : cls.getDeclaredFields()) { DCCValue dccValue = f.getAnnotation(DCCValue.class); if (dccValue != null) { String[] parts = dccValue.value().split(":"); String key = PREFIX + parts[0]; // Redis 中存储的 Key String defaultValue = parts[1]; // 默认值 RBucket<String> bucket = redis.getBucket(key); String value = bucket.isExists() ? bucket.get() : defaultValue; bucket.trySet(defaultValue); // 若 Redis 中无配置,则写入默认值 injectField(bean, f, value); // 通过反射注入值 dccObjGroup.put(key, bean); // 缓存配置与 Bean 映射关系 } } return bean; // 返回初始化后的 Bean } 运行时热更新 订阅一个 Redis Topic(频道),比如 "dcc_update"; 外部通过发布接口 PUBLISH dcc_update "key,newValue" 发送更新消息; private final RTopic dccTopic; @GetMapping("/dcc/update") public void update(@RequestParam String key, @RequestParam String value) { // 发布配置更新消息到 Redis 主题,格式为 "configKey,newValue" String message = key + "," + value; dccTopic.publish(message); // 通过 dccTopic 发布更新消息 log.info("配置更新发布成功 - key: {}, value: {}", key, value); } 订阅者收到后: 更新 Redis 中的配置; 从映射里取出对应 Bean,使用反射更新字段。 // 发布/订阅配置热更新 @Bean("dccTopic") public RTopic dccTopic(RedissonClient redis) { RTopic dccTopic = redis.getTopic("dcc_update"); dccTopic.addListener(String.class, (channel, msg) -> { String[] parts = msg.split(","); // msg 约定格式:"configKey,newValue" String key = PREFIX + parts[0]; // 拼接 Redis Key String newValue = parts[1]; // 新的配置值 RBucket<String> bucket = redis.getBucket(key); if (!bucket.isExists()) { return; // 如果不是我们关心的配置,跳过 } bucket.set(newValue); // 更新 Redis 中的配置 Object bean = beans.get(key); // 从内存中取出 Bean 实例 if (bean != null) { injectField(bean, parts[0], newValue); // 通过反射更新 Bean 字段 } }); return dccTopic; // 返回 Redis Topic 实例 } 在 Redis 的发布/订阅模型中,RTopic dccTopic = redis.getTopic("dcc_update"); 这行代码指定了 dccTopic 订阅的主题(也可以理解为一个消息通道)。不同的类可以通过依赖注入来使用这个 RTopic 实例。一些类可以调用 dccTopic.publish(message) 向该通道发送消息;而另一些类则可以通过 dccTopic.addListener() 来订阅该主题,从而接收消息并进行相应的处理。 面试官:为什么选择Redis Pub/Sub,不用rabbitmq? 两者都能实现这个需求,但 Redis 更轻量。在多实例部署时,每个实例都能收到广播并通过反射完成热更新;如果某个实例宕机重启,它会直接从 Redis 中拉取最新配置,而不依赖历史广播。 确实,Redis Pub/Sub 没有消息确认等可靠性机制;如果换成 RabbitMQ,配置交换机为广播模式,各实例使用匿名队列,同样可以接收消息并完成更新,而且还能提供更强的可靠性保证。不过在本项目中,动态配置中心在初期就基于 Redis 实现了,RabbitMQ 是在后期做交易领域时才引入的组件。考虑到场景对可靠性要求不高,同时也为了保持架构的简单性,所以没有替换为 RabbitMQ。 热更新数据流转过程 1.广播消息(PUBLISH):配置变更会通过 PUBLISH 命令广播到 Redis 中的某个主题。 2.Redis Sub(订阅):订阅该主题的客户端收到消息后,进行处理。 3.更新 Redis 和 Bean 字段: 更新 Redis 中的配置(保持一致性)。 更新 Bean 实例的对应字段(通过反射,确保配置的实时性)。 重要说明 RedissonClient( Redis)的作用: 1.消息广播(通过 Topic) 2.redis中的配置与bean中的字段配置一致,有一定容错 / 恢复能力,如果某个节点启动时错过了消息,它可以在初始化时直接从 Redis 读到最新配置。 HashMap的作用: 在广播监听阶段,快速获取要操作的bean实例,进行反射。 OkHttpClient+Retrofit 小型支付商城中,需要调用外部的支付宝、微信登录相关接口,使用了OkHttp + Retrofit。 1.引入依赖 <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.12.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>retrofit</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>converter-jackson</artifactId> <version>2.11.0</version> </dependency> 2.配置 OkHttpClient @Configuration public class OkHttpClientConfig { @Bean public OkHttpClient okHttpClient() { return new OkHttpClient.Builder() .connectTimeout(Duration.ofSeconds(10)) .readTimeout(Duration.ofSeconds(30)) .writeTimeout(Duration.ofSeconds(30)) .retryOnConnectionFailure(true) // TODO: 可以统一加日志拦截器、鉴权拦截器 .build(); } } 单例复用:Spring 管理 Bean,整个应用只创建一次。 集中配置:超时、拦截器、SSL 等只在这里写一份,避免代码里到处 new。 3.配置Retrofit @Configuration public class RetrofitConfig { private static final String BASE_URL = "https://api.example.com/"; @Bean public Retrofit retrofit(OkHttpClient okHttpClient) { return new Retrofit.Builder() .baseUrl(BASE_URL) .client(okHttpClient) // 🔑 复用统一的 OkHttpClient .addConverterFactory(JacksonConverterFactory.create()) .build(); } @Bean public ApiService apiService(Retrofit retrofit) { return retrofit.create(ApiService.class); } } 4.定义 API 接口(Retrofit 风格) public interface ApiService { @GET("users/{id}") Call<User> getUser(@Path("id") String id); @POST("orders") Call<OrderResponse> createOrder(@Body OrderRequest request); } 5.在 Service 中调用 @Slf4j @Service @RequiredArgsConstructor public class UserService { private final ApiService apiService; // 同步请求 public User getUserById(String id) { try { Response<User> resp = apiService.getUser(id).execute(); if (resp.isSuccessful()) { return resp.body(); } throw new RuntimeException("请求失败,HTTP " + resp.code()); } catch (Exception e) { log.error("获取用户信息失败", e); throw new RuntimeException(e); } } // 异步请求 public void getUserAsync(String id) { apiService.getUser(id).enqueue(new Callback<User>() { @Override public void onResponse(Call<User> call, Response<User> response) { log.info("异步回调结果: {}", response.body()); } @Override public void onFailure(Call<User> call, Throwable t) { log.error("异步请求失败", t); } }); } } Retrofit 在运行时会生成这个接口的实现类,帮你完成: 拼 URL(把 {id} 换成具体值) 发起 GET 请求 拿到响应的 JSON 并自动反序列化成 User 对象 OkHttp 提供底层能力:连接池、超时、拦截器、HTTP/2 等,适合做全局单例配置。 特点/场景 Retrofit RPC(如 gRPC、Dubbo 等) 主要用途 封装 HTTP API 调用,集成第三方服务 微服务之间的内部通信 协议层 基于 HTTP/HTTPS(REST 风格) 基于 TCP/HTTP2,自定义协议或 Protobuf 数据序列化 JSON(默认) Protobuf / Thrift / Avro(更高效) 典型应用场景 第三方 REST API、外部服务调用 微服务架构、跨语言调用、内部高性能通信 调用方式 支持同步/异步,声明式接口 支持同步/异步、流式调用,多语言 SDK 性能特点 依赖 HTTP/JSON,序列化开销较大 高吞吐量、低延迟,序列化高效 易用性 简单,代码少,学习成本低 需要服务框架支持,学习/配置成本较高 支付宝下单沙箱 https://open.alipay.com/develop/sandbox/app 读取本地配置文件。 @Data @Component @ConfigurationProperties(prefix = "alipay", ignoreInvalidFields = true) public class AliPayConfigProperties { // 「沙箱环境」应用ID - 您的APPID,收款账号既是你的APPID对应支付宝账号。获取地址;https://open.alipay.com/develop/sandbox/app private String appId; // 「沙箱环境」商户私钥,你的PKCS8格式RSA2私钥 private String merchantPrivateKey; // 「沙箱环境」支付宝公钥 private String alipayPublicKey; // 「沙箱环境」服务器异步通知页面路径 private String notifyUrl; // 「沙箱环境」页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问 private String returnUrl; // 「沙箱环境」 private String gatewayUrl; // 签名方式 private String signType = "RSA2"; // 字符编码格式 private String charset = "utf-8"; // 传输格式 private String format = "json"; } 创建alipay客户端。 @Configuration public class AliPayConfig { @Bean("alipayClient") public AlipayClient alipayClient(AliPayConfigProperties properties) { return new DefaultAlipayClient(properties.getGatewayUrl(), properties.getAppId(), properties.getMerchantPrivateKey(), properties.getFormat(), properties.getCharset(), properties.getAlipayPublicKey(), properties.getSignType()); } } 公众号扫码登录流程 https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index 微信开发者平台。 微信登录时,需要调用微信提供的接口做验证,使用Retrofit 场景:用微信的能力来替你的网站做“扫码登录”或“社交登录”,代替自己写一整套帐号/密码体系。后台只需要基于 openid 做一次性关联(比如把某个微信号和你系统的用户记录挂钩),后续再次扫码就当作同一用户; 1.前端请求二维码凭证 用户点击“扫码登录”,前端向后端发 GET /api/v1/login/weixin_qrcode_ticket。 后端获取 access_token 1.先尝试从本地缓存(如 Guava Cache)读取 access_token; 2.若无或已过期,则请求微信接口: GET https://api.weixin.qq.com/cgi-bin/token ?grant_type=client_credential &appid={你的 AppID} &secret={你的 AppSecret} 微信返回 { "access_token":"ACCESS_TOKEN_VALUE", "expires_in":7200 },后端缓存这个值(有效期约 2 小时)。 后端利用 access_token 创建二维码 ticket,返给前端。(每次调用微信会返回不同的ticket) 2.前端展示二维码 前端根据 ticket 生成二维码链接:https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket={ticket} 3.微信回调后端 用户确认扫描后,微信服务器向你预先配置的回调 URL(如 POST /api/v1/weixin/portal/receive)推送包含 ticket 和 openid 的消息。 后端:将 ticket → openid 存入缓存(openidToken.put(ticket, openid));调用 sendLoginTemplate(openid) 给用户推送“登录成功”模板消息(手机公众号上推送,非网页) 4.前端获知登录结果 轮询方式:生成二维码后,前端每隔几秒向后端 check_login 接口发送 ticket来验证登录状态,后端查缓存来判断 ticket 对应用户是否成功登录。 推送方式:前端通过 WebSocket/SSE 建立长连接,后端回调处理完成后直接往该连接推送登录成功及 JWT。 浏览器指纹获取登录ticket 在扫码登录流程的基础上改进!!! 目的:把「这张二维码/ticket」严格绑在发起请求的那台浏览器上,防止别的设备或会话拿到同一个 ticket 就能登录。 1.生成指纹 前端在用户打开「扫码登录页」时,先用 JS/浏览器 API(比如 User-Agent、屏幕分辨率、插件列表、Canvas 指纹等)算出一个唯一的浏览器指纹 fp。 2.获取 ticket 时携带指纹 前端发起请求: GET /api/v1/login/weixin_qrcode_ticket_scene?sceneStr=<fp> 后端执行: String ticket = loginPort.createQrCodeTicket(sceneStr); sceneTicketCache.put(sceneStr, ticket); // 把 fp→ticket 映射进缓存 3.扫码后轮询校验 前端轮询:传入 ticket 和 sceneStr 指纹 GET /api/v1/login/check_login_scene?ticket=<ticket>&sceneStr=<fp> 后端逻辑(简化): // 1) 验证拿到的 sceneStr(fp) 对应的 ticket 是否一致 String cachedTicket = sceneTicketCache.getIfPresent(sceneStr); if (!ticket.equals(cachedTicket)) { // fp 不匹配,拒绝 return NO_LOGIN; } // 2) 再看 ticket→openid 有没有被写入(扫码并回调后,saveLoginState 会写入) String openid = ticketOpenidCache.getIfPresent(ticket); if (openid != null) { // 同一浏览器,且已扫码确认,返回 openid(或 JWT) return SUCCESS(openid); } return NO_LOGIN; 4.回调时保存登录状态 当用户扫描二维码,微信会回调你预定的接口地址,拿到 ticket、openid 后,调用: ticketOpenidCache.put(ticket, openid); // 保存 ticket→openid 注意 ticketOpenidCache 和 sceneTicketCache 一般是一个Cache Bean,这里只是为了更清晰。 安全性提升 防止“票据劫持”:别人就算截获了这个 ticket,想拿去自己那台机器上轮询也不行,因为指纹对不上。 防止多人共用:多个人在不同设备上同时扫同一个码,只有最先发起获取 ticket 的那台浏览器能完成登录。 独占锁和无锁化场景(防超卖) 目标: 保证 库存数量的正确性 —— 不能出现“明明只有 10 件商品,却卖出去 11 件”的情况。 典型问题场景: 秒杀/拼团/抢购,高并发请求瞬间打到库存。 多个并发事务都认为“库存足够”,于是都扣减成功。 独占锁 适用场景 定时任务互备 多机部署时,确保每天只有一台机器在某个时间点执行同一份任务(如数据清理、报表生成、邮件推送等)。 @Scheduled(cron = "0 0 0 * * ?") public void exec() { // 获取锁句柄,并未真正获取锁 RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec"); try { //尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取;leaseTime = 0:不设过期时间,看门狗机制 boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS); if (!isLocked) return; Map<String, Integer> result = tradeSettlementOrderService.execSettlementNotifyJob(); log.info("定时任务,回调通知拼团完结任务 result:{}", JSON.toJSONString(result)); } catch (Exception e) { log.error("定时任务,回调通知拼团完结任务失败", e); } finally { if (lock.isLocked() && lock.isHeldByCurrentThread()) { lock.unlock(); } } } 无锁化并发控制(法一) 目标:在万级并发下保证 不超卖、可退单补量、团长也算库存,且不引入 JVM 级互斥锁。 角色 Redis Key 含义 变化方式 计数器 teamOccupiedStockKey 已占用名额(仅团员) INCR 退单补量 recoveryTeamStockKey 退回名额(累加) 退单环节 INCRBY 配额上限 target 团长 + 团员 的最大名额 配置 1. Lua 原子脚本 -- KEYS[1] = teamOccupiedStockKey -- ARGV[1] = target(含团长) -- ARGV[2] = recoveryCount local limit = tonumber(ARGV[1]) + tonumber(ARGV[2]) local v = redis.call('INCR', KEYS[1]) + 1 -- +1 把团长补进去 if v > limit then redis.call('DECR', KEYS[1]) -- 回滚 return 0 -- 告诉调用方名额已满 else return v -- 抢到的序号(含团长) end 原子性:INCR → 判断 → DECR 全在一条脚本里,Redis 单线程保证不会被并发打断。 +1 偏移:计数器只统计团员,每次 +1 把团长补进去,对比对象与 target 同维度。(redis中的teamOccupiedStockKey的值比真实锁单量少1,是正常的,因为redis中只存了团员的锁单,团长是在代码逻辑中手动+1的) 退单补量:limit = target + recoveryCount,退单线程把名额写回 recoveryTeamStockKey 后,下一次抢单自然放量。 无锁化并发控制(法二) @Override public boolean occupyTeamStock(String teamOccupiedStockKey, String recoveryTeamStockKey, Integer target, Integer validTime) { // 获取失败恢复量 Long recoveryCount = redisService.getAtomicLong(recoveryTeamStockKey); recoveryCount = null == recoveryCount ? 0 : recoveryCount; // 1. incr 得到值,与总量和恢复量做对比。恢复量为系统失败时候记录的量。 // 2. 从有组队量开始,相当于已经有了一个占用量,所以要 +1,因为团长开团的时候teamid为null,但事实上锁单已经有一单了。 long occupy = redisService.incr(teamOccupiedStockKey) + 1; //取teamOccupiedStockKey的值,先自增,再返回;类似++i if (occupy > target + recoveryCount) { repository.recoveryTeamStock(recoveryTeamStockKey); return false; } // 1. 给每个产生的值加锁为兜底设计,虽然incr操作是原子的,基本不会产生一样的值。但在实际生产中,遇到过集群的运维配置问题,以及业务运营配置数据问题,导致incr得到的值相同。 // 2. validTime + 60分钟,是一个延后时间的设计,让数据保留时间稍微长一些,便于排查问题。 String lockKey = teamOccupiedStockKey + Constants.UNDERLINE + occupy; Boolean lock = redisService.setNx(lockKey, validTime + 60, TimeUnit.MINUTES); if (!lock) { log.info("组队库存加锁失败 {}", lockKey); } return lock; } 这里teamOccupiedStockKey 和recoveryTeamStockKey 都是只增不减的,如果抢占失败的,直接对recoveryTeamStockKey+1。 recoveryTeamStockKey 还有通过参与拼团的人退单来+1 为什么对teamOccupiedStockKey-1 必须要用Lua脚本? long occupy = redisService.incr(teamOccupiedStockKey); if (occupy > target + recoveryCount) { redisService.decr(teamOccupiedStockKey); // 回滚 return false; } 如果直接JAVA代码中写两个逻辑,风险在: INCR 和 DECR 是两条独立命令。 在 INCR 和 DECR 之间的时间窗口里,其他请求可能已经拿到 INCR 的结果。 多个失败请求并发执行,会出现“多次 DECR 把计数扣过头”的问题,导致库存虚减甚至超卖。 本项目采用第二种方法!!! 极端兜底锁 String lockKey = teamOccupiedStockKey + Constants.UNDERLINE + occupy; Boolean lock = redisService.setNx(lockKey, validTime + 60, TimeUnit.MINUTES); if (!lock) { log.info("组队库存加锁失败 {}", lockKey); } 解决极小概率 相同序号并发撞号 的问题( TTL 比业务 validTime 多留 60 min,方便排查。 订单关闭/失效时记得删除对应 lockKey(目的是设置了过期时间为拼团有效期+60分钟),防止 Redis 小键堆积。 怎样的情况可能导致并发撞号? t1:客户端发起 INCR,Redis 内存里变成 101,返回 101(内存里修改完成就返回,不等落盘); t1+Δ:Redis 还没把这条写刷到磁盘(AOF 还在缓冲里 / OS 还没 fsync); t2:Redis 故障崩溃 → 只剩下落盘的旧状态(100); t3:重启后加载旧数据,从 100 再开始递增 → 101(和之前用过的号重复)。 持久化粒度取决于 appendfsync 配置: always:每次写都 fsync → 最安全,最慢。 everysec(默认):每秒 fsync → 可能丢 1 秒内的数据。 no:完全交给操作系统 → 性能好,但可能丢几十秒。 本项目有三层防护: 页面/接口层校验 前端进入拼团展示页时,先查询当前拼团信息(展示“还差 X 人”)。 用户下单时调用“锁单接口”,若此时名额已满,接口直接返回“拼团组队完结”。 这一层主要是减少无效请求,但无法彻底防止并发穿透。 后端并发控制层(Redis 无锁化) Redis 原子计数:通过 INCR 原子操作,确保同一时刻的请求不会并发写入同一计数值。 补偿计数:通过 recoveryTeamStockKey 自动回收名额,防止异常锁单占用。 兜底锁(SETNX):防止极端情况下(如 Redis AOF 数据丢失后重启)出现“号段重复”。 Redis 层负责 高并发抢占的并发正确性与性能优化,让大部分请求在内存层快速失败返回。 最终防线:数据库层库存约束 Redis 只作为并发控制与削峰层,真正防止超卖的约束仍在数据库: INSERT ... WHERE lock_count < target; 面试问题:如果Redis宕机了,里面的锁单量、恢复量岂不是清零了?是否导致超卖? 答:不会导致超卖。 1.配置AOF Redis 会把每一条写命令以日志形式追加到 appendonly.aof 文件。 宕机重启时,Redis 会回放 AOF 文件里的命令,恢复到宕机前的状态。 appendfsync=always → 每次写都刷盘,几乎不丢数据,但性能略低。。 2.哨兵+主从集群 Redis 主从集群可实现自动故障切换,保证服务高可用。 虽然主从切换瞬间可能出现短暂数据不一致(最终一致性),但在同步完成后数据会恢复一致。 3.数据库层兜底约束 “Redis 掉了不会导致超卖,因为它只是瞬时控制层,最终库存是由数据库和恢复机制兜底的。” INSERT ... WHERE lock_count < target; 生活例子理解 假设你有一个限量商品,每个商品有一个唯一的编号,假设这些商品编号为 1、2、3、4、5(总共 5 个)。这些商品被分配给用户,每个用户会抢一个编号。每个用户成功抢到一个商品后,系统会在库存中占用一个编号。 抢购过程: 有 5 个商品编号(1-5),这些编号是库存量。 每个用户请求一个商品编号,系统会给用户分配一个编号(这个过程就像是自增占用量的过程)。 如果用户请求的编号超过了现有库存的最大编号(5),则说明没有商品可以分配给该用户,用户抢购失败。 如果有多个用户抢同一个编号(例如都想抢到编号 1 的商品),系统通过“分布式锁”来保证只有一个用户能成功抢到编号 1,其他用户则失败。 缓存Supplier<T> Supplier<T> 是 Java 8 提供的一个函数式接口 @FunctionalInterface public interface Supplier<T> { /** * 返回一个 T 类型的结果,参数为空 */ T get(); } 任何“无参返回一个 T 类型对象”的代码片段(方法引用或 lambda)都可以当成 Supplier<T> 来用。 作用 1.延迟执行 把“取数据库数据”这类开销大的操作,包装成 Supplier<T> 传进去;只有真正需要时(缓存未命中),才触发执行。 // 缓存未命中时,才调用 supplier.get() 执行数据库查询 T dbResult = dataFetcher.get(); 2.解耦逻辑 缓存组件不关心数据如何获取,只负责缓存策略;调用方通过 Supplier提供数据获取逻辑。 public <T> T getFromCacheOrDb(String key, Supplier<T> dataFetcher) { ... } 3.重用性高 同一个缓存-回源模板方法可以服务于任何返回 T 的场景,既可以查 User,也可以查 Order、List<Product>…… // 查询用户 User user = getFromCacheOrDb("user:123", () -> userDao.findById(123)); // 查询订单列表 List<Order> orders = getFromCacheOrDb("orders:456", () -> orderDao.listByUserId(456)); dataFetcher.get() → userDao.findById(123) 分布式限流(AOP + Redisson 实现)+黑名单 核心思路 动态开关管理 使用 @DCCValue("rateLimiterSwitch:open") 从配置中心动态注入全局开关,支持热更新。 当开关为 "close" 时,直接放行所有请求,切面不再执行限流逻辑。 AOP 切面拦截 通过自定义注解 @RateLimiterAccessInterceptor 标记需要限流的方法。 注解参数 key 用于指定限流维度(如 userId 表示按用户限流,all 表示全局限流)。 切面在运行时解析这个字段的值,动态生成 Redis 限流器 Key,例如: //添加拦截注解 @RateLimiterAccessInterceptor(key = "userId", permitsPerSecond = 5, fallbackMethod = "fallback") public void order(String userId) {...} 请求1: userId=U12345 → Redis Key: rl:limiter:U12345 请求2: userId=U67890 → Redis Key: rl:limiter:U67890 反射的应用: 获取限流维度 Key(如 userId) 切面会从方法参数对象中反射查找 userId字段: private String extractField(Object obj, String name) { Field field = getFieldByName(obj, name); field.setAccessible(true); Object v = field.get(obj); return v != null ? v.toString() : null; } 调用降级方法 当请求被限流或进入黑名单时,切面会通过反射执行注解里指定的 fallbackMethod: Method method = jp.getTarget().getClass() .getMethod(fallbackMethod, ms.getParameterTypes()); return method.invoke(jp.getTarget(), jp.getArgs()); 限流与黑名单 使用 RRateLimiter 实现分布式令牌桶,每秒放入 permitsPerSecond 个令牌。 取不到令牌时: 如果配置了 blacklistCount,用 RAtomicLong 记录该 Key 的拒绝次数; 拒绝次数超限后,将 Key 加入黑名单 24 小时。(rl:bl:keyAttr 中存放着24小时内该用户超限次数,如果大于blacklistCount,则黑名单启动拦截;而不是指某个rl:bl:keyAttr 存在就拦截,还是要比较次数的!) 命中黑名单或限流时,调用注解里的 fallbackMethod 执行降级逻辑。 注意这里有两个key: rl:bl:keyAttr ,设置了24小时的过期时间,里面存着24小时内xx用户超限的次数。 rl:limiter:keyAttr 未设置过期时间(xx用户随时来,随时限流) 令牌桶算法(Token Bucket) 工作原理:按固定速率往桶里放“令牌”(tokens),例如每秒放 N 个。每次请求到达时,必须先从桶中“取一个令牌”,才能通过;如果取不到,则拒绝或降级。 特点:支持流量平滑释放和突发流量吸纳,桶最多能存储 M 个令牌。 方法调用 ↓ AOP 切面拦截(匹配 @RateLimiterAccessInterceptor) ↓ 检查全局限流开关(@DCCValue 注入) ↓ 解析注解里的 key → 获取对应参数值(如 userId) ↓ 黑名单检查(RAtomicLong) ↓ 分布式令牌桶限流(RRateLimiter.tryAcquire) ↓ ├─ 成功 → 执行目标方法 └─ 失败 → 累加拒绝计数 & 调用 fallbackMethod 对比维度 本地限流 分布式限流 实现复杂度 低:直接用 Guava RateLimiter,几行代码即可接入 中高:依赖 Redis/Redisson,需要注入客户端并管理限流器 性能开销 极低:全程内存操作,纳秒级延迟 中等:每次获取令牌需网络往返,存在 RTT 延迟 限流范围 单实例:仅对当前 JVM 有效,多实例互不影响 全局:多实例共享同一套令牌桶,合计速率可控 状态持久化 & 容错 无:服务重启后状态丢失;实例宕机只影响自身 有:Redis 存储限流器与黑名单,可持久化;需保证 Redis 可用性 目前本项目采用 分布式限流,使用 Redisson 实现跨实例令牌桶,确保全局限流控制。 防止重复下单 目标: 确保同一用户在同一业务维度(如一个拼团活动、一个商品、一次支付流程)下,无论请求多少次,都只生成一条有效订单。 典型问题场景: 用户在页面疯狂点击“立即购买”; 网络延迟导致重复提交; 用户恶意构造多条请求。 一、整体思路 核心目标:实现幂等性(Idempotency) 对于同一个操作的重复请求,系统只执行一次,结果一致、返回同一订单号。 层级 方案 作用 前端 按钮禁用 / loading 状态 阻止多次点击 服务端 幂等 Key + 唯一索引 数据层防重 可选 Redis 分布式锁 并发控制(防止短时间内重复插入) 二、实现幂等性 1)生成幂等 Key 前端生成:调用 /api/idempotency-key,由后端生成唯一 ID(UUID / 雪花算法); 外部系统传入:使用外部交易号(如 out_trade_no)作为幂等 key。 原则:幂等 Key 必须唯一且可复用(同一业务场景同一 key,重复请求仍返回同一结果)。 请求下单接口 /create_order 时,前端需携带该 Key。 2)数据库唯一约束(核心防重机制) 给幂等 Key 添加唯一索引 ALTER TABLE orders ADD UNIQUE KEY uniq_idempotent (idempotency_key); 3)数据库原子插入(推荐写法) INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); SELECT LAST_INSERT_ID() AS order_id; 客户端连接 Session #1 ────────────────────────────────────────────── SQL1: INSERT INTO orders (...) VALUES (...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); MySQL 内部执行: ┌─检测唯一键冲突───────────────┐ │ 若无冲突 → 插入 → 设置 last_insert_id = 新id │ │ 若冲突 → 更新 → 设置 last_insert_id = 原id │ └──────────────────────────┘ SQL2: SELECT LAST_INSERT_ID() AS order_id; → 返回上一步中设置的 last_insert_id(无论是插入的还是更新的) MySQL 内部保证原子性: 要么插入,要么更新 → 不存在竞态条件。 4)Redis 分布式锁(可选层) 针对高并发下同一 Key 的同时提交,可使用 Redis 锁: String lockKey = "order:submit:" + idempotencyKey; if (tryLock(lockKey, 5s)) { // 查是否已存在 // 不存在则创建订单 } else { return "重复请求"; } 锁仅控制短期并发,幂等仍由数据库唯一索引兜底。 三、为什么不建议“先查后插”或"先插后查" -- 1. 尝试插入 INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...); -- 2. 如果影响行数 == 0,则说明冲突了(存在了) -- 3. 再去查询 SELECT id FROM orders WHERE idempotency_key = :key; 在并发下存在竞态: 顺序 线程 A 线程 B 1 插入成功 插入冲突失败 2 – 立即查询时可能读到别的线程刚写入的数据 → 数据不一致、逻辑混乱。 ✅ 推荐:使用 ON DUPLICATE KEY 让 MySQL 原子处理。 企业做法:幂等 Key + 状态表 维护一个专门的幂等控制表(order_request) 记录「请求级别」的信息,主要用来判断:这个幂等 key(一次下单操作)是不是已经被处理过。 CREATE TABLE idempotent_record ( id BIGINT AUTO_INCREMENT PRIMARY KEY, biz_type VARCHAR(32), -- 业务类型: order/pay/refund/notify idempotency_key VARCHAR(64) UNIQUE, biz_id BIGINT, -- 对应业务主键 status ENUM('PROCESSING','SUCCESS','FAILED'), error_msg VARCHAR(255), created_at DATETIME ); 可以把这张幂等表理解成一个「防火墙」或「中间登记簿」: 每一个请求先“登记”; 若登记成功,说明是第一次进入 → 允许创建订单; 若登记失败(重复 key) → 直接查记录返回原订单。 为什么要单独维护这张表? 原因 说明 ✅ 控制层和业务层解耦 幂等控制独立,不污染订单表结构 ✅ 通用性强 同一个机制可复用在「支付、退款、回调」等接口 RPC微服务调用 RPC(Remote Procedure Call,远程过程调用) 就像调用本地方法一样调用远程服务的方法。 框架(Dubbo、gRPC、Thrift 等)会帮你处理 动态代理、序列化、网络通信、连接管理、负载均衡 等细节。 开发者只需要写接口 + 实现类,调用方直接调用接口,RPC 框架在背后“悄悄”完成远程调用。 实现步骤 1.父Pom统一版本 <!-- 统一锁版本,避免不同模块写不同小版本 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-bom</artifactId> <version>3.3.5</version> <type>pom</type> <scope>import</scope> </dependency> 2.pay-mall-infrustruct(Consumer)group-buying-sys-trigger (Provider)引入依赖 <dependencies> <!-- Dubbo 核心 + Spring Boot 自动装配 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> </dependency> <!-- Nacos 注册中心扩展 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-registry-nacos</artifactId> </dependency> </dependencies> 3.部署nacos(详见微服务笔记) 4.配置注册(消费者、生产者都要配) dubbo: application: name: group-buy-market-service # 换成各自服务名 registry: address: nacos://localhost:8848 # 远程环境写内网地址 # username/password 如果 Nacos 开了鉴权 protocol: name: dubbo port: 20880 # 生产者开放端口;消费者可不写 consumer: timeout: 3000 # 毫秒 check: false # 忽略启动时服务是否可用 5.开启 Dubbo 注解扫描 在消费者、生产者的主启动类上加,设置正确的包名,让 @DubboService 和 @DubboReference 被 Spring+Dubbo 识别和处理 @SpringBootApplication @EnableDubbo(scanBasePackages = "edu.whut") public class Application { … } 6.在Dubbo RPC调用中,DTO对象需要在网络中进行传输,因此它们必须实现 java.io.Serializable 接口: /** * 用户信息请求对象 */ @Data public class UserRequestDTO implements Serializable { // 实现 Serializable private static final long serialVersionUID = 1L; // 添加 serialVersionUID,用于版本控制 // 用户ID private String userId; // 用户名 private String userName; // 邮箱 private String email; } 7.定义服务接口: 服务接口定义了服务提供者能够提供的功能以及服务消费者能够调用的方法。这个接口必须是公共的,并且通常放置在一个独立的 api模块中。供服务提供者和消费者共同依赖。 /** * 用户服务接口 */ public interface IUserService { /** * 根据用户ID获取用户信息 * @param requestDTO 用户请求对象 * @return 用户响应对象 */ UserResponseDTO getUserInfo(UserRequestDTO requestDTO); /** * 创建新用户 * @param requestDTO 用户请求对象 * @return 操作结果 */ String createUser(UserRequestDTO requestDTO); } 8.服务提供者 (Provider) 实现并暴露服务 在服务提供者应用中,实现上述定义的服务接口,并使用 @DubboService 注解将其暴露为Dubbo服务。可以放在trigger/rec包下。 /** * 用户服务实现类 */ @DubboService(version = "1.0.0", group = "user-service") // 关键注解:暴露Dubbo服务 @Service // 也可以同时是Spring的Service public class UserServiceImpl implements IUserService { @Override public UserResponseDTO getUserInfo(UserRequestDTO requestDTO) { System.out.println("收到获取用户信息的请求: " + requestDTO.getUserId()); // 模拟业务逻辑 UserResponseDTO response = new UserResponseDTO(); response.setUserId(requestDTO.getUserId()); response.setUserName("TestUser_" + requestDTO.getUserId()); response.setEmail("test_" + requestDTO.getUserId() + "@example.com"); return response; } @Override public String createUser(UserRequestDTO requestDTO) { System.out.println("收到创建用户的请求: " + requestDTO.getUserName()); // 模拟业务逻辑 return "User " + requestDTO.getUserName() + " created successfully."; } } 9.服务消费者 (Consumer) 引用远程服务 在服务消费者应用中,通过 @DubboReference 注解引用远程Dubbo服务。Dubbo 会自动通过注册中心查找并注入对应的服务代理。 /** * 用户API控制器 */ @RestController public class UserController { @DubboReference(version = "1.0.0", group = "user-service") // 关键注解:引用Dubbo服务 private IUserService userService; @GetMapping("/user/info") public UserResponseDTO getUserInfo(@RequestParam String userId) { UserRequestDTO request = new UserRequestDTO(); request.setUserId(userId); return userService.getUserInfo(request); } @GetMapping("/user/create") public String createUser(@RequestParam String userName, @RequestParam String email) { UserRequestDTO request = new UserRequestDTO(); request.setUserName(userName); request.setEmail(email); return userService.createUser(request); } } RPC:同步调用、强一致、快速响应,比如pay-mall调用拼团系统的拼团交易锁单 、营销结算、营销拼团退单 HTTP:本系统调用微信支付这种第三方接口。 MQ:异步解耦、削峰填谷、最终一致性,比如退单消息,pay-mall调用营销拼团退单接口后,将订单设置为'待退单状态',然后拼团系统退单完成后发送'退单完成'消息,pay-mall接收继续做最终的退单处理。 怎么确保这个微服务调用的可靠性? 如果小型支付商城调用拼团失败,有两种情况: 1.网络异常、超时,dubbo框架会抛一个异常,可以特别处理,对其进行重试,设置最大重试次数,以及指数退避算法;这里要求锁单做幂等校验! 2.业务异常,不重试,可能是因为用户参与次数已达上限、活动过期之类的。 日志系统 输出流向一览 输出到3个地方:控制台、本地文件、ELK日志(服务器上内存不足无法部署!) 日志级别 控制台 本地文件(异步) Logstash (TCP) TRACE/DEBUG — — — INFO ✔ log_info.log ✔ WARN ✔ log_info.log``log_error.log ✔ ERROR/FATAL ✔ log_info.log``log_error.log ✔ 注意:实际写文件时,都是通过 ASYNC_FILE_INFO/ERROR 两个异步 Appender 执行,以免日志写盘阻塞业务线程。 ELK日志系统 本地文件每台机器都会在自己 /data/log/... 目录下滚动输出自己的日志,互相之间不会合并。 如果你希望跨多台服务器统一管理,就需要把日志推到中央端——ELK日志系统 ELK=Elasticsearch(存储&检索)+ Logstash(采集&处理)+ Kibana(可视化) docker-compose.yml: version: '3' services: elasticsearch: image: elasticsearch:7.17.28 ports: ['9201:9200','9300:9300'] environment: - discovery.type=single-node - ES_JAVA_OPTS=-Xms512m -Xmx512m volumes: - ./data:/usr/share/elasticsearch/data logstash: image: logstash:7.17.28 ports: ['4560:4560','9600:9600'] volumes: - ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf environment: - LS_JAVA_OPTS=-Xms1g -Xmx1g kibana: image: kibana:7.17.28 ports: ['5601:5601'] environment: - elasticsearch.hosts=http://elasticsearch:9200 networks: default: driver: bridge kibana配置: # # ** THIS IS AN AUTO-GENERATED FILE ** # # Default Kibana configuration for docker target server.host: "0" server.shutdownTimeout: "5s" elasticsearch.hosts: [ "http://elasticsearch:9200" ] # 记得修改ip monitoring.ui.container.elasticsearch.enabled: true i18n.locale: "zh-CN" logstash配置: input { tcp { mode => "server" host => "0.0.0.0" port => 4560 codec => json_lines type => "info" } } filter {} output { elasticsearch { action => "index" hosts => "es:9200" index => "group-buy-market-log-%{+YYYY.MM.dd}" } } 自己的项目: <!-- 上报日志;ELK --> <springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/> <!--输出到logstash的appender--> <appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <!--可以访问的logstash日志收集端口--> <destination>${LOG_STASH_HOST}:4560</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>7.3</version> </dependency> 使用 检查索引:curl http://localhost:9201/_cat/indices?v3 打开 Kibana:浏览器访问 http://localhost:5601,新建 索引模式(如 app-log-*),即可在 Discover/Visualize 中查看与分析日志。
项目
zy123
1年前
0
41
1
2025-06-07
Smile云图库
Smile云图库 整体架构 注意:使用腾讯云OSS存储,12月7号资源包过期!!! 数据库表 picture 表 — 图片表 字段名 类型 说明 id bigint 主键 ID url varchar(512) 图片 URL name varchar(128) 图片名称 introduction varchar(512) 简介 category varchar(64) 分类 tags varchar(512) 标签(JSON 数组) pic_size bigint 图片体积(字节) pic_width int 图片宽度 pic_height int 图片高度 pic_scale double 宽高比例 pic_format varchar(32) 图片格式 user_id bigint 创建用户 ID create_time datetime 创建时间 edit_time datetime 编辑时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除(0 否 1 是) review_status int 审核状态:0 待审核 / 1 通过 / 2 拒绝 review_message varchar(512) 审核信息 reviewer_id bigint 审核人 ID review_time datetime 审核时间 thumbnail_url varchar(512) 缩略图 URL original_url varchar(512) 原图 URL space_id bigint 空间 ID(null 为公共空间) pic_color varchar(16) 图片主色调 space 表 — 空间表 字段名 类型 说明 id bigint 主键 ID space_name varchar(128) 空间名称 space_level int 空间级别:0 普通版 / 1 专业版 / 2 旗舰版 max_size bigint 空间最大可存储总大小 max_count bigint 空间最大图片数量 total_size bigint 当前空间图片总大小 total_count bigint 当前空间图片数量 user_id bigint 创建用户 ID create_time datetime 创建时间 edit_time datetime 编辑时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除 space_type int 空间类型:0 私有 / 1 团队 space_user 表 — 空间与用户关联表 字段名 类型 说明 id bigint 主键 ID space_id bigint 空间 ID user_id bigint 用户 ID space_role varchar(128) 空间角色:viewer / editor / admin create_time datetime 创建时间 update_time datetime 更新时间(自动更新) user 表 — 用户表 字段名 类型 说明 id bigint 主键 ID user_account varchar(256) 用户账号 user_password varchar(512) 用户密码 user_name varchar(256) 用户昵称 user_avatar varchar(1024) 用户头像 user_profile varchar(512) 用户简介 user_role varchar(256) 用户角色(user / admin) user_email varchar(256) 用户邮箱 birthday date 出生日期 user_phone varchar(50) 用户手机号 edit_time datetime 编辑时间 create_time datetime 创建时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除 压测 正式环境:2核4GB运存 首页查询接口: 单测延迟70ms,耗时占比:若干图片json拿缓存+JSON 反序列化+序列化返回给前端+HTTP 传输 14 KB 数据+浏览器 解析 JSON 1秒内1000次请求压测: 为什么压测下这么慢?排查过本地缓存都是命中的。可能是: Caffeine 命中后 → 依旧要 mapper.readValue 做 JSON parse; JSON 体量 ~14 KB,CPU 在高并发下被打爆; Tomcat 线程池也被压满,导致排队。 待完善功能 缓存相关 1. 手动刷新缓存 在某些情况下,数据更新较为频繁,但自动刷新缓存的机制可能存在延迟,这时可以通过手动刷新来解决。例如: 提供一个刷新缓存的接口,仅供管理员调用。 在管理后台提供入口,允许管理员手动刷新指定缓存。 2.热点Key问题 定义:在 Redis 中,某个 key 的访问量远高于其他 key,导致 大量请求集中到同一个 key。 后果: Redis 单线程处理这个 key 的请求,容易形成性能瓶颈。 如果 key 过期或被删除,大量并发请求会直接穿透数据库(缓存击穿)。 目前图片详情页没有缓存,如果少数图片非常热门(比如被放在推荐位或首页大 banner),用户频繁点进去看详情,每次都查数据库,就可能导致 单 key 高并发,数据库被压垮。后续可以用热key 探测技术,实时对图片的访问量进行统计,并自动将热点图片添加到内存缓存。 系统安全 限流、黑名单,降级返回逻辑都未完善,而系统中存在爬虫搜图、AI扩图功能,需要补充这块逻辑。 上传图片体验优化 1.目前仅有公共图库支持管理员批量搜图并上传,私人空间和团队空间都只能一张张上传,或许可以前端优化一下显示,支持批量上传,然后有一个类似扑克卡片那张叠加,每次顶上显示一个图片以及它的基本信息,确认无误点击确认可处理下一张。 2.目前只有管理员界面显示所有图片的管理;用户这边可以记录一个自己上传的图片列表,记录自己什么时候上传了什么图片,是否正在审核中... 图片展示优化 可以使用CDN内容分发网络、浏览器缓存提高图片的加载速度。 协同编辑 1、为防止消息丢失,可以使用 Redis 等高性能存储保存执行的操作记录。目前如果图片已经被编辑了,新用户加入编辑时没办法查看到已编辑的状态,这一点也可以利用 Redis 保存操作记录来解决,新用户加入编辑时读取 Redis 的操作记录即可。 2、支持分布式 WebSocket。只需要保证要编辑同一图片的用户连接的是相同的服务器即可,和游戏分服务器大区、聊天室分房间是类似的原理。(目前单机部署,暂不考虑) 3.目前多人协同编辑,只支持一个人编辑,其他人实时看到最新编辑状态,而且防并发限制只做了前端,即第一个人进入编辑,其他人按钮变灰,这样是不安全的。后端应该使用redis分布式锁。 锁 Key:pic:edit:{pictureId} 锁 Value:{userId}:{uuid}(既能辨认持有者,又能避免误删别人的锁) 加锁:SET key value NX PX <ttl>(拿到返回 OK,拿不到返回 null) 续期:持锁线程每 ttl/3 定时 PEXPIRE key <ttl>(或 SET key value XX PX <ttl> 确保续租) 释放:Lua 脚本「value 匹配才 DEL」,防止误删他人的锁 重入:如果同一用户再次进入,允许他复用自己手上的锁(校验 value 的 userId 部分) 超时兜底:没续期/断线,锁会因 TTL 过期被动释放 踩坑 精度损失和日期格式转换问题 前端 → 后端 日期 前端把日期格式化成后端期待的纯日期字符串,例如 "2025-08-14",后端 DTO 用 LocalDate 接收(配合 @JsonFormat(pattern="yyyy-MM-dd")),Jackson 反序列化成 LocalDate。 精度: JavaScript 的 number 类型只能安全地表示到 2^53−1(约 9×10^15)的整数,超过这个范围就会丢失精度,用 number 传给后端时末尾只能补0; 解决办法:前端 ID 当做字符串传给后端。 Spring MVC 会自动调用 Long.parseLong("1951619197178556418") 并赋值给你方法签名里的 long id(即还是写作long来接收,不变) 后端 → 前端 日期: 后端用 LocalDate / LocalDateTime 之类的 Java 8 类型,经过 Jackson 序列化为指定格式的字符串(比如 "yyyy-MM-dd" / "yyyy-MM-dd HH:mm:ss")供前端消费,避免时间戳或默认格式的不一致。 精度: Java 的 long 可能超过 JavaScript number 的安全范围(2^53−1),直接以数字输出会丢失精度。必须把 long/Long 序列化成字符串(例如 ID 输出为 "1951648800160399362"),前端拿到字符串再展示。 对 Jackson 用作 Spring 的 HTTP 消息转换器的 ObjectMapper 进行配置(日期格式、Java 8 时间支持、Long 转字符串等)示例代码: @Configuration public class JacksonConfig { private static final String DATE_FORMAT = "yyyy-MM-dd"; private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; private static final String TIME_FORMAT = "HH:mm:ss"; @Bean public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() { return builder -> { builder.featuresToDisable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); builder.simpleDateFormat(DATETIME_FORMAT); builder.featuresToDisable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS); JavaTimeModule javaTime = new JavaTimeModule(); javaTime.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT))); javaTime.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DATE_FORMAT))); javaTime.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(TIME_FORMAT))); javaTime.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT))); javaTime.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DATE_FORMAT))); javaTime.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(TIME_FORMAT))); SimpleModule longToString = new SimpleModule(); longToString.addSerializer(Long.class, ToStringSerializer.instance); longToString.addSerializer(Long.TYPE, ToStringSerializer.instance); builder.modules(javaTime, longToString); }; } } 序列化操作是通过 Jackson 的 ObjectMapper 完成的,它并不依赖于 Serializable 接口。Serializable 接口更多的是用于对象的 Java 原生序列化,例如将对象写入文件或通过网络传输时的序列化,而 Jackson 处理的是 Java 对象和 JSON 之间的序列化与反序列化。 Websocket连接问题 前端请求地址: const protocol = location.protocol === 'https:' ? 'wss' : 'ws' // 线上地址 const host = location.host; const url = `${protocol}://${host}/api/ws/picture/edit?pictureId=${this.pictureId}` this.socket = new WebSocket(url) nginx配置: # ---------- WebSocket 代理 ---------- location /api/ws/ { proxy_pass http://picture_backend; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_buffering off; proxy_read_timeout 86400s; } 坑点在这:由于本项目采用NPM做域名管理,124.71.159.xxx:18096 ->https://picture.bitday.top/ 要把这里的Websockets Supports勾上,不然无法建立连接!排查了很久! 数据库密码加密 加密存储确保即使数据库泄露,攻击者也不能轻易获取用户原始密码。 spring security 中提供了一个加密类BCryptPasswordEncoder。 它采用哈希算法 SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种可逆的算法,而哈希算法是一种不可逆的算法。 因为有随机盐的存在,所以相同的明文密码经过加密后的密码是不一样的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的 验证密码 matches // 使用 matches 方法来对比明文密码和存储的哈希密码 boolean judge= passwordEncoder.matches(rawPassword, user.getPassword()); 注意,matches的第一个参数必须 是 “原始明文”,第二个参数 必须 是 “已经加密过的密文”!!!顺序不能反!!! 循环依赖问题 PictureController ↓ 注入 PictureServiceImpl PictureServiceImpl ↓ 注入 SpaceServiceImpl SpaceServiceImpl ↓ 注入 SpaceUserServiceImpl SpaceUserServiceImpl ↓ 注入 SpaceServiceImpl ←—— 又回到 SpaceServiceImpl 解决办法:将一方改成 setter 注入并加上 @Lazy注解 如在SpaceUserServiceImpl中 @Resource @Lazy // 必须使用 Spring 的 @Lazy,而非 Groovy 的! private SpaceService spaceService; @Lazy为懒加载,直到真正第一次使用它时才去创建或注入。且这里不能用构造器注入的方式!!! ❌ 构造器注入会立即触发依赖加载,无法解决循环依赖 Redis RDB问题 Caused by: io.lettuce.core.RedisCommandExecutionException: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error. Redis 默认是支持持久化的(RDB / AOF),其中 RDB 快照是通过后台 bgsave 子进程定期把内存数据写到磁盘。 配置文件里有一条关键参数: stop-writes-on-bgsave-error yes # 默认值 yes:如果 bgsave 持久化失败(写 RDB 文件失败),Redis 会立刻禁止所有写操作(set/del/incr 等)。避免出现数据还在内存里、但落盘失败,用户却误以为写成功了的情况。 如何解决:进入redis的命令行 config set stop-writes-on-bgsave-error no 收获 MybatisX插件简化开发 下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下: 注意,勾选 Actual Column 生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即 user_name—>userName 下载GenerateSerailVersionUID插件,可以右键->generate->生成序列ID: private static final long serialVersionUID = -1321880859645675653L; 胡图工具类hutool 引入依赖 <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.26</version> </dependency> ObjUtil.isNotNull(Object obj),仅判断对象是否 不为 null,不关心对象内容是否为空,比如空字符串 ""、空集合 []、数字 0 等都算是“非 null”。 ObjUtil.isNotEmpty(Object obj) 判断对象是否 不为 null 且非“空” 对不同类型的对象判断逻辑不同: CharSequence(String):长度大于 0 Collection:size > 0 Map:非空 Array:长度 > 0 其它对象:只判断是否为 null(默认不认为“空”) StrUtil.isNotEmpty(String str) 只要不是 null 且长度大于 0 就算“非空”。 StrUtil.isNotBlank(String str) 不仅要非 null,还要不能只包含空格、换行、Tab 等空白字符 StrUtil.hasBlank(CharSequence... strs)只要 **至少一个字符串是 blank(空或纯空格)**就返回 true,底层其实就是对每个参数调用 StrUtil.isBlank(...) CollUtil.isNotEmpty(Collection<?> coll)用于判断 集合(Collection)是否非空,功能类似于 ObjUtil.isNotEmpty(...) BeanUtil.toBean :用来把一个 Map、JSONObject 或者另一个对象快速转换成你的目标 JavaBean public class BeanUtilExample { public static class User { private String name; private Integer age; // 省略 getter/setter } public static void main(String[] args) { // 1. 从 Map 转 Bean Map<String, Object> data = new HashMap<>(); data.put("name", "Alice"); data.put("age", 30); User user1 = BeanUtil.toBean(data, User.class); System.out.println(user1.getName()); // Alice // 2. 从另一个对象转 Bean class Temp { public String name = "Bob"; public int age = 25; } Temp temp = new Temp(); User user2 = BeanUtil.toBean(temp, User.class); System.out.println(user2.getAge()); // 25 } } 创建图片的业务流程 方式 1:先上传文件,再提交表单数据 流程: 用户先把图片上传到云存储,系统生成一个 url。 系统不急着写数据库,只是记住这个 url。 用户继续在前端填写图片的标题、描述、标签等信息。 用户点击“提交”后,才把 url + 其它信息 一起存进数据库,生成一条完整记录。 优点: 数据库里不会出现“用户传了文件,但没填写信息”的垃圾数据。 缺点: 如果用户传了文件但中途关掉页面,文件虽然已经占了存储空间,但数据库里没有记录,这个文件可能变成“孤儿文件”,需要后台定期清理。 方式 2:上传文件时就立即建数据库记录 流程: 用户一旦上传成功,后端立即在数据库里生成完整的图片记录(包含能直接解析出来的元信息,如宽高、大小、格式、URL、上传者等)。 后续用户只是在编辑已有的图片记录(补充标题、描述、标签等),而不是新建。 优点: 数据库里能实时反映出当前所有文件的存在状态,方便管理。 即使用户中途不编辑,也能有一条图片记录存在。 缺点: 可能会有很多“不完整”的记录(缺少标题等),需要做清理或状态标记。 可能侵害用户隐私 **针对方式1,**可能存在孤儿文件的问题,解决办法: 上传阶段(放临时区) 用户选图 → 前端调用后端接口拿一个临时上传地址(key 类似 /temp/{userId}/{uuid}.png)。 前端直接把文件上传到 COS 的 temp 文件夹。 这时只是文件存在 COS,数据库里还没有正式的图片记录。 提交阶段(转正) 用户在网页里填写标题、描述等信息后点击提交。 后端接收到提交请求后: 在数据库里创建图片记录(生成 pictureId 等信息) 把 COS 中的文件从 /temp/... 复制(Copy)到正式目录 /prod/{spaceId}/{pictureId}.png 删除 /temp/... 的原文件(节省空间) 把正式文件 URL 保存到数据库中 针对方式2: 新上传的图片记录默认设置为 status = DRAFT,表示草稿状态,仅对上传者可见。 当用户确认并提交(实际是编辑补充信息后)时,将该记录的状态更新为 PUBLISHED,即正式发布。 如果用户在上传后未点击提交而是选择取消,则应立即删除该记录,并同时从 COS 中移除对应的文件。 另外,后端应配置定时任务,定期清理超过 N 小时/天仍处于 DRAFT 状态的记录,并同步删除 COS 上的文件,以避免无效数据和存储浪费。 本项目采取的是方式2!!! 登录校验 BCrypt加密 使用 BCrypt 这类强哈希算法,它不仅仅是简单的 MD5 或 SHA 加密,还融合了盐值(Salt) 和成本因子(Work Factor)。 盐值(Salt): 每个用户的密码在加密前都会叠加一个随机生成的、唯一的字符串(盐)。这意味着即使两个用户的密码相同,它们在数据库里存储的哈希值也完全不同。这有效防御了彩虹表攻击。 成本因子(Work Factor): 它控制着哈希计算的复杂度(迭代次数)。可以动态调整(例如从 10 增加到 12),使得即使未来算力增长,暴力破解的成本依然高昂到不可接受。 比较过程:将用户输入的密码进行哈希计算后与数据库存储的值比对。我们自始至终都只处理哈希值,而不接触或存储用户的明文密码。 // 校验密码 if (!passwordEncoder.matches(userPassword, user.getUserPassword())) { throw new BusinessException(ErrorCode.PARAMS_ERROR, "用户不存在或者密码错误"); } Session登录校验 1.基本原理 服务端:存储会话数据(内存、Redis 等)。 客户端:仅保存会话 ID(如 JSESSIONID),通常通过 Cookie 传递。 2.数据结构 服务端会话存储(Map 或 Redis) { "abc123" -> HttpSession 实例 } HttpSession 结构: HttpSession ├─ id = "abc123" ├─ creationTime = ... ├─ lastAccessedTime = ... └─ attributes └─ "USER_LOGIN_STATE" -> user 实体对象 3.请求流程 首次请求 浏览器没有 JSESSIONID,服务端调用 createSession() 创建一个新会话(ID 通常是 UUID)。 服务端返回响应头 Set-Cookie: JSESSIONID=<新ID>; Max-Age=2592000(30 天有效期)。 浏览器将 JSESSIONID 写入本地 Cookie(持久化保存)。 后续请求 浏览器自动在请求头中附带 Cookie: JSESSIONID=<ID>。 服务端用该 ID 在会话存储中查找对应的 HttpSession 实例,恢复用户状态。 ┌───────────────┐ (带 Cookie JSESSIONID=abc123) │ Browser │ ───────►│ Tomcat │ └───────────────┘ └──────────┘ │ │ 用 abc123 做 key ▼ {abc123 → HttpSession} ← 找到 │ ▼ 取 attributes["USER_LOGIN_STATE"] → 得到 userrequest.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); 4.后端使用示例 保存登录状态: request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); request.getSession() 会自动获取当前请求关联的 HttpSession 实例。 获取登录状态: User user = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE); 退出登录: request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE); 相当于清空当前会话中的用户信息。浏览器本地的 JSESSIONID 依然存在,只不过后端啥也没了。 优点 会话数据保存在服务端,相比直接将数据存储在客户端更安全(防篡改)。 缺点 分布式集群下 Session 无法自动共享(需借助 Redis 等集中存储)。 客户端禁用 Cookie 时,Session 会失效。 服务端需要维护会话数据,高并发环境下可能带来内存或性能压力。 Redis+Session 前面每次重启服务器都要重新登陆,既然已经整合了 Redis,不妨使用 Redis 管理 Session,更好地维护登录态,且能多实例(集群)共享。 1)先在 Maven 中引入 spring-session-data-redis 库: <!-- Spring Session + Redis --> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> 2)修改 application.yml 配置文件,更改Session的存储方式和过期时间: 既要设置redis能存30天,发给前端的cookie也要30天有效期。 spring: session: store-type: redis timeout: 30d # 会话不活动超时(maxInactiveInterval) redis: host: 127.0.0.1 port: 6379 server: servlet: session: cookie: max-age: 30d # 发给前端 Cookie 的保存时长 # name: JSESSIONID # 如想保持原名,见下文“Cookie 名称” 存储结构展示: 面试官:Spring Session 中存储的是什么数据? 答:存储的核心数据是用户的登录状态对象。具体来说,就是我代码中 request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user)存入的整个 user实体对象。 从技术实现上看,Spring Session 在 Redis 中存储的是一个标准的 Hash 数据结构。这个 Hash 的 Key 是由 Spring Session 自动生成的一个唯一 Session ID(格式类似于 sessionid:abc123),而 Hash 的各个 Field 则对应着 HttpSession 中的各个 Attribute(如上图的sessionAttr:user_login)。 如果有多个Attribute,那也会有多个filed!!!这里的lastAccessedTime、maxInactiveInterval、creationTime都是固定有的field!!! 面试官:存储用户信息的过程中通常会涉及序列化和反序列化的操作,这有什么作用? 序列化是将内存中的对象转换为一种可以存储或传输的格式(通常是字节流或字符串),而反序列化则是其逆过程,将这种格式重新构建为内存中的对象。 1.为了传输和存储:内存中的对象无法直接存数据库或网络传输,序列化把它变成通用格式(如JSON字符串/二进制流)。 2.为了跨语言和平台:序列化后的数据(如JSON)任何语言都能识别,实现了Java服务、Go服务、前端都能理解同一份数据。 3.为了重建状态:在分布式系统中,反序列化能把存储的数据(如Redis里的字符串)重新变回内存里的对象,恢复用户会话状态(如登录信息)。 普通用户与管理员权限控制 使用AOP切面! 1)定义注解 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface AuthCheck { /** * 必须具有某个角色 **/ String mustRole() default ""; } 2)写切片类 @Aspect @Component @RequiredArgsConstructor public class AuthInterceptor { private final UserService userService; /** * 执行拦截 * * @param joinPoint 切入点 * @param authCheck 权限校验注解 */ @Around("@annotation(authCheck)") public Object doInterceptor(ProceedingJoinPoint joinPoint, AuthCheck authCheck) throws Throwable { String mustRole = authCheck.mustRole(); RequestAttributes requestAttributes = RequestContextHolder.currentRequestAttributes(); HttpServletRequest request = ((ServletRequestAttributes) requestAttributes).getRequest(); // 获取当前登录用户 User loginUser = userService.getLoginUser(request); UserRoleEnum mustRoleEnum = UserRoleEnum.getEnumByValue(mustRole); // 如果不需要权限,放行 if (mustRoleEnum == null) { return joinPoint.proceed(); } // 以下的代码:必须有权限,才会通过 UserRoleEnum userRoleEnum = UserRoleEnum.getEnumByValue(loginUser.getUserRole()); if (userRoleEnum == null) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } // 要求必须有管理员权限,但用户没有管理员权限,拒绝 if (UserRoleEnum.ADMIN.equals(mustRoleEnum) && !UserRoleEnum.ADMIN.equals(userRoleEnum)) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } // 通过权限校验,放行 return joinPoint.proceed(); } } 3)使用 /** * 分页获取图片列表(仅管理员可用) */ @PostMapping("/list/page") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Page<Picture>> listPictureByPage(@RequestBody PictureQueryRequest pictureQueryRequest) { long current = pictureQueryRequest.getCurrent(); long size = pictureQueryRequest.getPageSize(); // 查询数据库 Page<Picture> picturePage = pictureService.page(new Page<>(current, size), pictureService.getQueryWrapper(pictureQueryRequest)); return ResultUtils.success(picturePage); } 上传图片(模板方法模式) 本模块采用 模板方法设计模式: 在 抽象类 PictureUploadTemplate 中定义了上传图片的 固定流程(算法骨架)。 将具体步骤(如校验、获取文件名、处理输入源)延迟到 子类实现,以支持不同的上传方式。 目前支持两种上传方式: 本地文件上传(FilePictureUpload) 网络 URL 上传(UrlPictureUpload) 抽象类:PictureUploadTemplate 核心方法:uploadPicture() 定义了上传图片的完整流程,固定步骤如下: 校验图片 → validPicture(inputSource) 检查文件大小、格式是否合法。 生成上传路径与文件名 → getOriginFilename(inputSource) 提取原始文件名并拼接安全的上传路径。 创建临时文件 → processFile(inputSource, tempFile) 将输入源(文件或 URL)转化为本地临时文件。 上传到对象存储(COS) 通过 CosManager 将文件推送至存储桶。 封装返回结果 包含压缩图、缩略图、原图地址以及宽高、大小、格式等信息。 清理临时文件 → deleteTempFile(file) 删除服务器上的临时文件,避免资源泄露。 子类职责 FilePictureUpload 实现文件上传场景 校验文件大小 ≤ 2MB,后缀是否在白名单(jpg/png/webp 等) 使用 MultipartFile.transferTo() 写入临时文件 UrlPictureUpload 实现 URL 上传场景 校验 URL 格式、协议(http/https) 通过 HEAD 请求检查 Content-Type、Content-Length 使用 HttpUtil.downloadFile() 将远程文件保存为临时文件 模板方法模式保证了上传流程的一致性和扩展性。 不同来源的图片上传(文件 / URL)只需实现差异化的步骤,而无需改动整体流程。 图片压缩优化 对象存储 图片持久化处理_腾讯云 项目中存储了三种图片url: 1.原图,仅供下载的时候提供 2.使用腾讯云的数据万象将原图转为Webp格式,作为一般的网页内图片的展示图 3.使用腾讯云的数据万象将原图转为缩略图格式,作为网页中小图的展示(点开图片前) 以图搜图 法一:使用百度 AI 提供的图片搜索 API 或者 Bing以图搜图API 法二:爬虫 以百度搜图网站为例,先体验一遍流程,并且对接口进行分析: 1)进到百度图片搜索百度识图搜索结果,通过 url 上传图片,发现接口:https://graph.baidu.com/upload?uptime= ,该接口的返回值为 “以图搜图的页面地址” 2)访问上一步得到的页面地址,可以在返回值中找到 firstUrl: 3)访问 firstUrl,就能得到 JSON 格式的相似图片列表,里面包含了图片的缩略图和原图地址: 本项目采用法二。 外观模式 目的:简化系统的复杂性,提供一个统一的接口,隐藏系统内部的细节。 实现方式:创建了一个 ImageSearchApiFacade 类,它对外提供了 searchImage 方法,通过这个方法,外部调用者不需要关心图片搜索的具体步骤(如获取页面 URL、获取图片列表等),只需要调用这个简洁的接口即可。 searchImage(String localImagePath):外部调用者通过该方法传入图片路径,ImageSearchApiFacade 会依次调用子系统中的方法获取图片列表,并返回结果。 子系统:GetImagePageUrlApi、GetImageFirstUrlApi、GetImageListApi 等是实现细节,分别负责不同的任务: getImagePageUrl(String localImagePath):该方法向百度的「以图搜图」API 发起上传请求,并获取返回的结果页面 URL。 getImageFirstUrl(String imagePageUrl):根据传入的页面 URL,该方法会请求页面并解析其 HTML 内容,从中找到 firstUrl,即第一张图片的 URL。 getImageList(String imageFirstUrl):该方法使用传入的第一张图片 URL,发起请求到获取图片列表的 API,处理返回的 JSON 数据,提取出图片列表,并将其转换为 ImageSearchResult 对象。 @Slf4j public class ImageSearchApiFacade { /** * 搜索图片 */ public static List<ImageSearchResult> searchImage(String localImagePath) { String imagePageUrl = GetImagePageUrlApi.getImagePageUrl(localImagePath); String imageFirstUrl = GetImageFirstUrlApi.getImageFirstUrl(imagePageUrl); List<ImageSearchResult> imageList = GetImageListApi.getImageList(imageFirstUrl); return imageList; } } 图片功能扩展 按颜色搜图 为了提高性能并避免每次搜索时都进行实时计算,我们建议在图片上传成功后,立即提取图片的主色调并将其存储在数据库中的独立字段中。 完整流程如下: 提取图片颜色: 通过图像处理技术(如云服务 API 或 OpenCV 图像处理库),我们可以提取图片的颜色特征。我们采用主色调作为图片颜色的代表,简单明了,便于后续处理。此处,使用腾讯云提供的 数据万象接口 来获取每张图片的主色调:数据万象 获取图片主色调_腾讯云。 存储颜色特征: 提取到的颜色特征会被存储在数据库中,以便后续快速检索。通过这种方式,我们可以避免每次查询时重新计算图片的颜色特征,提高系统的响应速度。 用户查询输入: 用户可以通过不同的方式来指定颜色查询条件: 颜色选择器:用户可以通过直观的界面选择颜色。 RGB 值输入:用户可以直接输入颜色的 RGB 值。 预定义颜色名称:用户也可以选择常见的颜色名称(如红色、蓝色等)。 计算相似度: 在收到用户的查询条件后,系统会根据用户指定的颜色与数据库中存储的颜色特征进行相似度计算。常用的相似度计算方法包括 欧氏距离、余弦相似度 等,目的是找出与用户要求颜色最接近的图片。 返回结果: 由于每个空间内的图片数量相对较少,我们可以通过计算图片与目标颜色的相似度,对图片进行排序,优先返回最符合用户要求的图片。这种方法不仅提高了用户的搜索体验,也避免了仅返回完全符合指定色调的图片,拓宽了搜索结果的范围。 AI扩图 使用大模型服务平台百炼控制台提供的扩图功能。 异步任务 + 轮询查询模式 当调用的接口处理逻辑较为耗时(如 AI 图像生成、文档转换等),服务端通常不会立即返回最终结果。 为了避免 HTTP 请求长时间占用连接,接口会设计成先提交任务,再异步获取结果。 思想流程 发起任务 调用 create 类型接口,传入任务参数(图片url、调用的model、可选参数控制生成的图片细节)。 返回 taskId(任务唯一标识)以及任务的初始状态(如 pending、processing)。 延迟查询 等待一段时间(几秒或按服务端建议的间隔)。 使用 taskId 调用 get 类型接口查询状态。 轮询直到完成 如果状态为 processing 或 pending,继续间隔查询。 如果状态为 success 或 failed,结束轮询并处理结果。 轮询一般会在前端(或调用方)用定时器来触发,如每隔X秒查一次。 私有空间创建 在业务中,每个用户只能创建一个私人空间,但还允许创建团队空间,所以不能直接在 space 表的 userId 上加唯一索引来限制。需要加锁确保在并发情况下同一用户的创建操作安全且互不干扰。 private static final ConcurrentHashMap<Long, Object> USER_LOCKS = new ConcurrentHashMap<>(); Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); synchronized (lock) { try { // 执行事务内的空间创建逻辑 } finally { USER_LOCKS.remove(userId, lock); } } 来请求 → 创建/获取锁 → 进入 synchronized → 干活 干完活 → 释放锁(删除掉锁对象) 锁的目的是防止并发创建,锁里面会查数据库防止用户创多个私人空间。 为什么用 ConcurrentHashMap<Long,Object> 管理锁更优? 1. 避免污染常量池 synchronized (userId.toString().intern()) { // 以 userId 为维度的锁 } 如果用 String.intern() 作为锁对象,会将不同的 userId 字符串放入 JVM 字符串常量池。(有则取,无则创建并放入常量池) 随着用户量(userid)增长,常量池(位于元空间/永久代)会不断膨胀,带来 内存压力 和 垃圾回收开销。 ConcurrentHashMap 存储的锁对象是普通堆对象,可控且可回收,不会污染常量池。 2. 锁生命周期可控 ConcurrentHashMap可以显式增删: computeIfAbsent:仅当不存在锁对象时才创建。 remove(userId, lock):业务完成后立即移除,防止内存占用过大。 而 intern() 生成的字符串常驻常量池,生命周期由 JVM 管理,无法手动清理,存在内存泄漏风险。 3.支持高并发下的高性能 ConcurrentHashMap 在 JDK8 及以上采用CAS + 分段锁(或节点锁,多线程 computeIfAbsent 性能优于 HashMap + 全局 synchronized。 computeIfAbsent 是 ConcurrentHashMap提供的一个原子性操作方法,用于实现“如果键不存在则计算并存入,否则直接返回现有值”的线程安全逻辑。 Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); 单机:用 ConcurrentHashMap + synchronized 就足够。 多机 / 集群:必须用分布式锁(如 Redisson),否则不同节点之间的请求无法感知彼此的锁。 为什么这里用编程式事务而不是 @Transactional 问题背景 声明式事务(@Transactional)是由 Spring AOP 代理在方法进入前就开启事务,在方法返回后才提交。 如果锁(synchronized)在方法内部,事务会比锁早开启、晚提交。 并发风险 线程 A 进入方法 → 事务已开启 进入 synchronized,执行 exists → save,退出锁 事务还没提交(提交在方法返回时) 线程 B 等 A 释放锁后进入 → 此时 A 的事务未提交 B 查询 exists 看不到 A 的未提交数据(READ_COMMITTED 下) 误以为不存在 → 也执行 save 最终可能产生重复记录或唯一索引冲突。 编程式事务的好处 事务开启和提交的时机完全可控,可以放在 synchronized 内部。 保证加锁期间事务已提交或回滚,避免并发读取“看不到未提交数据”的问题。 private static final ConcurrentHashMap<Long, Object> USER_LOCKS = new ConcurrentHashMap<>(); @Autowired private TransactionTemplate transactionTemplate; public void createResource(Long userId) { // 每个用户一把锁 Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); synchronized (lock) { try { // 在锁内开启事务,确保事务提交时才释放锁 transactionTemplate.execute(status -> { // 模拟:先检查是否存在 boolean exists = checkExists(userId); if (exists) { throw new RuntimeException("已存在记录,不能重复创建"); } // 模拟:执行保存 saveResource(userId); return null; }); } finally { USER_LOCKS.remove(userId, lock); } } } // 以下是伪代码方法 private boolean checkExists(Long userId) { return false; // 假设不存在 } private void saveResource(Long userId) { System.out.println("为用户 " + userId + " 创建资源成功"); } 分库分表 如果某团队空间的图片数量比较多,可以对其数据进行单独的管理。 1、图片信息数据 可以给每个团队空间单独创建一张图片表 picture_{spaceId},也就是分库分表中的分表,而不是和公共图库、私有空间的图片混在一起。这样不仅查询空间内的图片效率更高,还便于整体管理和清理空间。但是要注意,仅对旗舰版空间生效,否则分表的数量会特别多,反而可能影响性能。 要实现的是会随着新增空间不断增加分表数量的动态分表,使用分库分表框架 Apache ShardingSphere 。 2、图片文件数据 已经实现隔离,存到COS上的不同桶内。 思路主要是基于业务需求设计数据分片规则,将数据按一定策略(如取模、哈希、范围或时间)分散存储到多个库或表中,同时开发路由逻辑来决定查询或写入操作的目标库表。 特点 水平分表 垂直分表 拆分方式 按行拆(同样结构,不同数据) 按列拆(不同字段) 解决问题 数据量太大 字段太多 / 热点与冷数据分离 表结构 相同 不同 典型场景 用户表、订单表(数据行数多) 用户信息(基本信息 + 扩展信息) 难点 跨表查询、分布式事务 多表 join、一致性维护 ShardingSphere 分库分表 <!-- 分库分表 --> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.2.0</version> </dependency> 水平分表在 ShardingSphere 里的两种实现:静态分表和动态分表 静态分表 静态分表:在设计阶段,分表的数量和规则就是固定的,不会根据业务增长动态调整,比如 picture_0、picture_1。 分片规则通常基于某一字段(如图片 id)通过简单规则(如取模、范围)来决定数据存储在哪个表或库中。 这种方式的优点是简单、好理解;缺点是不利于扩展,随着数据量增长,可能需要手动调整分表数量并迁移数据。 举个例子,图片表按图片 id 对 3 取模拆分: String tableName = "picture_" + (picture_id % 3) // picture_0 ~ picture_2 静态分表的实现很简单,直接在 application.yml 中编写 ShardingSphere 的配置就能完成分库分表,比如: rules: sharding: tables: picture: # 逻辑表名 actualDataNodes: ds0.picture_${0..2} # 3张物理表:picture_0, picture_1, picture_2 tableStrategy: standard: shardingColumn: picture_id # 按 pictureId 分片 shardingAlgorithmName: pictureIdMod shardingAlgorithms: pictureIdMod: type: INLINE #内置实现,直接在配置类中写规则,即下面的algorithm-expression props: algorithm-expression: picture_${pictureId % 3} # 分片表达式 查询逻辑表 picture 时,ShardingSphere 会根据分片规则自动路由到 picture_0 ~ picture_2。 动态分表 动态分表是指:分表的数量和规则不是预先固定的,而是可以在运行时根据业务需求或数据量动态生成。 例如:按月份动态建表 picture_2025_03、picture_2025_04,或在新建旗舰空间时生成 picture_30001。 String tableName = "picture_" + LocalDate.now().format( DateTimeFormatter.ofPattern("yyyy_MM") ); 配置示例: spring: shardingsphere: datasource: names: smile-picture smile-picture: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/smile-picture username: root password: 123456 rules: sharding: tables: picture: #逻辑表名(业务层永远只写 picture) actual-data-nodes: smile-picture.picture # 逻辑表对应的真实节点 table-strategy: standard: sharding-column: space_id #分片列(字段) sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法 sharding-algorithms: picture_sharding_algorithm: type: CLASS_BASED props: strategy: standard algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm props: sql-show: true 自定义分片算法 edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm 全类名。 public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) { Long spaceId = preciseShardingValue.getValue(); String logicTableName = preciseShardingValue.getLogicTableName(); // spaceId 为 null 表示查询所有图片 if (spaceId == null) { return logicTableName; } // 根据 spaceId 动态生成分表名 String realTableName = "picture_" + spaceId; if (availableTargetNames.contains(realTableName)) { return realTableName; } else { return logicTableName; } } @Override public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) { return new ArrayList<>(); } @Override public Properties getProps() { return null; } @Override public void init(Properties properties) } 关键对应关系 1)逻辑表名: 配置:tables.picture 代码:preciseShardingValue.getLogicTableName() 👉 必须一致,否则 SQL 写的 picture 无法触发分片。 2)分片键 配置:sharding-column: space_id 代码:preciseShardingValue.getValue() 👉 对应 SQL 中 WHERE space_id = xxx 的值。 3)分片算法名 sharding-algorithm-name: picture_sharding_algorithm 和下面算法定义对应: sharding-algorithms: picture_sharding_algorithm: # 算法名字 type: CLASS_BASED props: strategy: standard algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm 代码: public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> { ... } picture_sharding_algorithm 这个名字要和上面 sharding-algorithm-name 一致。 algorithmClassName 要填完整的 包路径 + 类名,否则 ShardingSphere 找不到。 分表总体思路: 逻辑表:picture(业务层只感知逻辑表)。 物理表: 公共表:普通 / 高级 / 专业版空间 → picture 分片表:旗舰版空间 → picture_<spaceId>(如 picture_30001) 分片键:space_id。 当 SQL 带 space_id 时: 如果是旗舰空间 → 路由到专属表 picture_<spaceId> 否则回退到公共表 picture 当 SQL 没有 space_id 时: 默认走公共表 picture 执行流程示例 SELECT * FROM picture WHERE space_id = 30001; 执行步骤: SQL 解析 → 逻辑表名 picture,分片键 space_id = 30001 调用分片算法 → 算法返回 picture_30001 物理表名 SQL 改写 → SELECT * FROM picture_30001 WHERE space_id = 30001; SQL 执行 → 发送到数据库执行,返回结果 旗舰用户的查询必须强制带上 space_id 如何动态分表 初始化时:项目启动 → 查询已有空间 → 组装所有表名(picture + 各种 picture_xxx)→ 更新 ShardingSphere 的分片配置。 运行时:如果新建了旗舰空间 → 动态建一张新表(物理表picture_xxx)→ 再刷新 ShardingSphere 的分片配置。 逻辑表 picture ├── 物理表 picture ← 公共图库 / 普通空间数据 ├── 物理表 picture_30001 ← 旗舰空间 30001 ├── 物理表 picture_30002 ← 旗舰空间 30002 ... shardingsphere是如何实现分库分表的 ShardingSphere 本质上是一个数据库中间层,它在 JDBC 层拦截 SQL,先用内置的 SQL 解析器把逻辑表、分片键解析出来,然后根据事先配置好的分片规则和算法决定应该路由到哪些真实库表,再把逻辑 SQL 改写成针对真实表的 SQL 并下发执行,最后对多个分片返回的结果做归并(排序、聚合、分页等),让应用层拿到的结果和单库单表一致。这样业务只需要面向逻辑表写代码,不用关心具体分到哪张表,从而实现了分库分表对应用透明化。 注意:本项目VIP 用户 → 查专属的分表 picture_vipXX;普通用户 → 查公共表 picture。 因此路由逻辑能精确定位到 唯一的一张物理表,所以不会有多分片的结果,也就不需要复杂的归并 空间成员权限控制 空间和用户是多对多的关系,还要同时记录用户在某空间的角色,所以需要新建关联表 空间成员表 字段名 类型 默认值 允许为空 注释 id bigint auto_increment 否 id spaceId bigint — 否 空间 id userId bigint — 否 用户 id spaceRole varchar(128) 'viewer' 是 空间角色:viewer / editor / admin createTime datetime CURRENT_TIMESTAMP 否 创建时间 updateTime datetime CURRENT_TIMESTAMP 否 更新时间 RBAC模型 基于角色的访问控制 一般来说,标准的 RBAC 实现需要 5 张表:用户表、角色表、权限表、用户角色关联表、角色权限关联表,还是有一定开发成本的。由于我们的项目中,团队空间不需要那么多角色,可以简化RBAC 的实现方式,比如将 角色 和 权限 直接定义到配置文件中。 本项目角色: 角色 描述 浏览者 仅可查看空间中的图片内容 编辑者 可查看、上传和编辑图片内容 管理员 拥有管理空间和成员的所有权限 本项目权限: 权限键 功能名称 描述 spaceUser:manage 成员管理 管理空间成员,添加或移除成员 picture:view 查看图片 查看空间中的图片内容 picture:upload 上传图片 上传图片到空间中 picture:edit 修改图片 编辑已上传的图片信息 picture:delete 删除图片 删除空间中的图片 角色权限映射: 角色 对应权限键 可执行功能 浏览者 picture:view 查看图片 编辑者 picture:view, picture:upload, picture:edit, picture:delete 查看图片、上传图片、修改图片、删除图片 管理员 spaceUser:manage, picture:view, picture:upload, picture:edit, picture:delete 成员管理、查看图片、上传图片、修改图片、删除图片 RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限校验呢? 1)最直接的方案是像之前校验私有空间权限一样,封装个团队空间的权限校验方法;或者类似用户权限校验一样,写个注解 + AOP 切面。 2)对于复杂的角色和权限管理,可以选用现成的第三方权限校验框架来实现,编写一套权限校验规则代码后,就能整体管理系统的权限校验逻辑了。( Sa-Token) Sa-Token 快速入门 1)引入: <!-- Sa-Token 权限认证 --> <dependency> <groupId>cn.dev33</groupId> <artifactId>sa-token-spring-boot-starter</artifactId> <version>1.39.0</version> </dependency> 2)让 Sa-Token 整合 Redis,将用户的登录态等内容保存在 Redis 中。 <!-- Sa-Token 整合 Redis (使用 jackson 序列化方式) --> <dependency> <groupId>cn.dev33</groupId> <artifactId>sa-token-redis-jackson</artifactId> <version>1.39.0</version> </dependency> <!-- 提供Redis连接池 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> 3)基本用法 StpUtil 是 Sa-Token 提供的全局静态工具。 用户登录时调用 login 方法,产生一个新的会话: StpUtil.login(10001); 还可以给会话保存一些信息,比如登录用户的信息: StpUtil.getSession().set("user", user) 接下来就可以判断用户是否登录、获取用户信息了,可以通过代码进行判断: // 检验当前会话是否已经登录, 如果未登录,则抛出异常:`NotLoginException` StpUtil.checkLogin(); // 获取用户信息 StpUtil.getSession().get("user"); 也可以参考 官方文档,使用注解进行鉴权: // 登录校验:只有登录之后才能进入该方法 @SaCheckLogin @RequestMapping("info") public String info() { return "查询用户信息"; } passwordEncoder多账号体系 本项目中存在两套权限校验体系。一套是 user 表的,分为普通用户和管理员;另一套是对团队空间的权限进行校 验。 为了更轻松地扩展项目,减少对原有代码的改动,我们原有的 user 表权限校验依然使用自定义注解 + AOP 的方式实 现。而团队空间权限校验,采用 Sa-Token 来管理。 这种同一项目有多账号体系的情况下,不建议使用 Sa-Token 默认的账号体系,而是使用 Sa-Token 提供的多账号认 证特性,可以将多套账号的授权给区分开,让它们互不干扰。 使用 Kit 模式 实现多账号认证 /** * StpLogic 门面类,管理项目中所有的 StpLogic 账号体系 * 添加 @Component 注解的目的是确保静态属性 DEFAULT 和 SPACE 被初始化 */ @Component public class StpKit { public static final String SPACE_TYPE = "space"; /** * 默认原生会话对象,项目中目前没使用到 */ public static final StpLogic DEFAULT = StpUtil.stpLogic; /** * Space 会话对象,管理 Space 表所有账号的登录、权限认证 */ public static final StpLogic SPACE = new StpLogic(SPACE_TYPE); } 修改用户服务的 userLogin 方法,用户登录成功后,保存登录态到 Sa-Token 的空间账号体系中: //记录用户的登录态 request.getSession().setAttribute(USER_LOGIN_STATE, user); //记录用户登录态到 Sa-token,便于空间鉴权时使用,注意保证该用户信息与 SpringSession 中的信息过期时间一致 StpKit.SPACE.login(user.getId()); StpKit.SPACE.getSession().set(USER_LOGIN_STATE, user); return this.getLoginUserVO(user); 之后就可以在代码中使用账号体系 // 检测当前会话是否以 Space 账号登录,并具有 picture:edit 权限 StpKit.SPACE.checkPermission("picture:edit"); // 获取当前 Space 会话的 Session 对象,并进行写值操作 StpKit.SPACE.getSession().set("user", "zy123"); Sa-Token 权限认证 1.核心:实现 StpInterface Sa-Token 需要知道某个用户 ID 拥有哪些角色和权限,这就要在项目中实现 StpInterface: 参考 官方文档,示例权限认证类如下: @Component public class StpInterfaceImpl implements StpInterface { // 根据用户 ID 查询权限列表 @Override public List<String> getPermissionList(Object loginId, String loginType) { // 实际项目里这里需要查数据库或缓存 return List.of("user.add", "user.update", "art.*"); } // 根据用户 ID 查询角色列表 @Override public List<String> getRoleList(Object loginId, String loginType) { return List.of("admin", "super-admin"); } } 项目权限较少时,可以只做角色校验;权限较多时,建议权限校验;二选一,不建议混用。 本项目 基于权限校验。 2.两种使用方式 方式一:注解式 使用 注解合并 简化代码。 @SaCheckPermission("picture.upload") public void uploadPicture() { ... } 调用接口时,Sa-Token 会在进入方法前自动校验权限(调用你实现的 StpInterface),并强制要求用户已登录。 特点: 优点:写法简洁,声明式安全。 缺点:参数必须通过 HttpServletRequest 获取;无法在方法内部灵活决定是否鉴权。 方式二:编程式 在方法内部的任意位置手动调用权限校验: if (!StpUtil.hasPermission("picture.view")) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } 可以先做一些逻辑判断,再决定是否需要权限校验(更灵活)。 适合场景:接口对未登录用户也开放,比如查看公共图片: 用编程式可以先判断是否需要鉴权,比如: 如果资源是公开的 → 不检查权限,直接返回。 如果资源属于某个空间 → 再做 hasPermission 校验。 @GetMapping("/doc/{id}") public BaseResponse<DocumentVO> getDoc(@PathVariable Long id) { // 查询文档 Document doc = docService.getById(id); ThrowUtils.throwIf(doc == null, ErrorCode.NOT_FOUND_ERROR); // 编程式鉴权逻辑 if (doc.isPrivate()) { // 先判断是否已登录 if (!StpUtil.isLogin()) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "请先登录"); } // 再判断是否有查看权限 if (!StpUtil.hasPermission("doc.view")) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "没有查看权限"); } } // 返回数据 return ResultUtils.success(docService.toVO(doc)); } 3. 注解式的登录强制性 注意:只要加了 Sa-Token 的权限/角色注解(例如 @SaCheckPermission),框架就会先检查用户是否已登录。 如果用户未登录,会直接抛异常(比如 NotLoginException),请求不会进入你的方法体。 原因: Sa-Token 的权限注解是在 进入方法前 执行的 AOP 切面逻辑。 在执行权限比对前,它必须知道“当前用户是谁”,所以会强制做登录状态校验。 如果你用的是 @SaSpaceCheckPermission(...),Sa-Token 就会走你 StpInterface#getPermissionList() 的实现,然后去匹配注解里写的权限码。 如果你改成基于角色的鉴权(比如 @SaCheckRole("admin")),那 Sa-Token 就会调用 StpInterface#getRoleList(),再用角色去匹配注解里的值。 注解式鉴权背后流程 拦截请求 → 注解触发 Sa-Token 的 AOP 切面。 获取 Token → 从 Cookie/Header/Param 读取,查 Redis 找到 loginId。 登录校验 → 未登录直接抛异常。 数据加载 → 调用你实现的 getPermissionList() 或 getRoleList()。 匹配比对 → 注解要求的权限/角色 vs 你返回的列表。 放行或拒绝 → 匹配成功执行方法,否则抛鉴权异常。 补充:注解合并 在 Spring 里,我们经常会遇到 注解继承 / 封装 的需求: 复用已有注解的功能,但不想每次都写一堆重复属性。 想要做业务语义化的封装。 这时候就会用到 @AliasFor 来做注解属性的别名映射。 1)定义一个“原始注解” @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface CheckPermission { String value(); // 权限码 String type() default "default"; // 权限类型 } 2)自定义一个“语义化的封装注解” @CheckPermission(type = "space") // 👈 这里已经给 type 赋了固定值 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface SpacePermission { @AliasFor(annotation = CheckPermission.class, attribute = "value") String[] value(); // 只把 value 暴露出来 } 3)使用 public class SpaceController { // 写法简洁 @SpacePermission("space:add") public void addSpace() {} // 实际等价于: // @CheckPermission(value = "space:add", type = "space") } Spring 在解析注解时,会做“注解合并”。 它会发现 @SpacePermission 上有 @CheckPermission,而且 value 用了 @AliasFor。 最终运行时效果就是 @CheckPermission(type="space", value="space:add")。 type="space"是预设好的,用户不能设置。 协同编辑 WebSocket 事件驱动模型的优势 与生产者直接调用消费者不同,事件驱动模型的核心优势在于 解耦 和 异步性: 解耦:生产者与消费者之间不需要直接依赖彼此的实现。生产者只需触发事件并交由事件分发器处理,消费者则根据事件类型执行相应逻辑。 异步性:通过引入事件分发器这一“中介”,系统可以实现异步消息传递,减少阻塞与等待,提高并发处理能力。 高并发与实时性:事件驱动可以在同一时间处理多个并发任务,更高效地响应实时请求。 如何解决协同冲突? 方案一:单用户编辑锁定: 业务上约定 同一时刻仅允许一位用户进入编辑状态。 其他用户在此期间只能实时查看修改效果,不能直接编辑。当该用户退出编辑后,其他用户才可进入编辑状态。 事件触发者(用户 A 的动作) 事件类型(发送消息) 事件消费者(其他用户的处理) 用户 A 建立连接,加入编辑 INFO 显示"用户 A 加入编辑"的通知 用户 A 进入编辑状态 ENTER_EDIT 其他用户界面显示"用户 A 开始编辑图片",锁定编辑状态 用户 A 执行编辑操作 EDIT_ACTION 放大/缩小/左旋/右旋当前图片 用户 A 退出编辑状态 EXIT_EDIT 解锁编辑状态,提示其他用户可以进入编辑状态 用户 A 断开连接,离开编辑 INFO 显示"用户 A 离开编辑"的通知,并释放编辑状态 用户 A 发送了错误的消息 ERROR 显示错误消息的通知 方案二:实时协同编辑(OT 算法) OT(Operational Transformation)是在线协作中常用的一种算法(例如 Google Docs、石墨文档)。 操作 (Operation):用户对协作内容的修改,例如插入字符、删除字符等。 转化 (Transformation):当多个用户同时修改时,OT 会根据上下文调整操作位置或内容,保证不同顺序执行的结果一致。 因果一致性:保证每个用户的操作都基于他们所看到的最新状态。 举一个简单的例子,假设初始内容是 "abc",用户 A 和 B 同时进行编辑: 用户 A 在位置 1 插入 "x" 用户 B 在位置 2 删除 "b" 如果不使用 OT: A 执行后 → "axbc" B 执行后 → "ac"(直接应用会导致 A 的结果被覆盖) 使用 OT: A 执行后 → "axbc" B 的删除操作经过转化 → 删除 "b" 在 "axbc" 中的新位置 最终结果 → "axc",A 和 B 看到的内容保持一致 OT 的关键难点在于设计合适的操作转化规则,以确保在不同编辑顺序下,最终结果仍然一致。本项目采取方案一!!! WebSocket 特性 HTTP WebSocket 通信模式 半双工 (Half-Duplex) 一问一答,同一时刻只能一端发送 全双工 (Full-Duplex) 双向通信,双方可同时发送和接收数据 连接模型 短连接 请求-响应后连接立即关闭,无状态 长连接 握手后建立持久连接,直到关闭,有状态 数据流向 单向 (客户端发起请求) 服务器不能主动推送数据 双向 服务器和客户端均可主动发送消息 协议开销 大 每次通信都携带完整的HTTP头部(Cookie、UA等) 小 初始握手后,数据传输使用轻量级帧,头部仅几字节 适用场景 传统网页加载、API调用、表单提交等请求-响应模式 实时应用:聊天室、在线游戏、实时数据推送、协同编辑 URL协议 http://或 https:// ws://(非加密) 或 wss://(加密,相当于HTTPS) 本质 文档传输协议,为获取超文本和资源设计 通信协议,为低延迟、实时双向通信设计 业务流程图 引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> WebSocket 配置类 @Configuration @EnableWebSocket @RequiredArgsConstructor public class WebSocketConfig implements WebSocketConfigurer { private final PictureEditWebSocketHandler pictureEditWebSocketHandler; private final WsHandshakeInterceptor wsHandshakeInterceptor; @Override public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) { ////当客户端在浏览器中执行new WebSocket("ws://<你的域名或 IP>:<端口>/ws/picture/edit?pictureId=123");就会由 Spring 把这个请求路由到你的 pictureEditWebSocketHandler 实例。 registry.addHandler(pictureEditWebSocketHandler, "/ws/picture/edit") .addInterceptors(wsHandshakeInterceptor) .setAllowedOrigins("*"); } } 任何客户端连接 ws://<host>:<port>/ws/picture/edit 都会交给 pictureEditWebSocketHandler 处理(负责收发消息) 在连接建立前,会先走 WsHandshakeInterceptor 做验证(请求参数是否缺失、用户是否登录、用户是否有编辑权限、图片是否存在、图片所在空间是否存在) 验证通过后,将 当前请求信息 user pictureId 存到 Sesssion中: attributes.put("user", loginUser); 后续取数据: User user = (User) session.getAttributes().get("user"); 协同编辑原理 在协同编辑场景中,我们使用 WebSocket 实现实时通讯。每个图片编辑操作由用户发起,WebSocket 会话(WebSocketSession)则承载每个用户的连接。下面是实现原理: // key: pictureId,value: 这张图下所有活跃的 Session(即各个用户的连接) Map<Long, Set<WebSocketSession>> pictureSessions; WebSocketSession 与用户 当用户 A 在浏览器中打开 pictureId=123 的编辑页面时,会产生一个 WebSocketSession(不同于 HttpSession)。 如果用户 A 在同一浏览器打开了新的标签页,或者在不同的浏览器/设备上再次打开编辑页面,那么每个新的连接都会产生一个 新的 WebSocketSession。 假设系统中有两张图片,pictureId 分别为 123 和 200,当前活跃的 WebSocket 会话(连接)如下: pictureId pictureSessions.get(pictureId) 123 { sessionA, sessionB } (用户 A、B 的连接) 200 { sessionC } (只有用户 C 的连接) 当 某个 WebSocketSession 发消息时,所有与该图片相关的 WebSocketSession(即同一 pictureId 下的所有连接)都会收到这条消息。 策略模式引入 针对不同的消息类型(ENTER_EDIT、EXIT_EDIT、EDIT_ACTION),if-else会导致类越来越臃肿,扩展性差。 优化:采用 策略模式 定义统一接口 PictureEditMessageHandler: public interface PictureEditMessageHandler { String getType(); void handle(PictureEditRequestMessage request, WebSocketSession session, User user, Long pictureId) throws Exception; } 针对不同消息类型定义独立策略: @Component @RequiredArgsConstructor public class EnterEditMessageHandler implements PictureEditMessageHandler { private final PictureEditWebSocketHandler sessionManager; private final UserService userService; private final Map<Long, Long> pictureEditingUsers = new ConcurrentHashMap<>(); @Override public String getType() { return PictureEditMessageTypeEnum.ENTER_EDIT.getValue(); } @Override public void handle(PictureEditRequestMessage request, WebSocketSession session, User user, Long pictureId) throws IOException { if (!pictureEditingUsers.containsKey(pictureId)) { pictureEditingUsers.put(pictureId, user.getId()); PictureEditResponseMessage response = new PictureEditResponseMessage(); response.setType(PictureEditMessageTypeEnum.ENTER_EDIT.getValue()); response.setMessage(String.format("用户 %s 开始编辑图片", user.getUserName())); response.setUser(userService.getUserVO(user)); sessionManager.broadcastToPicture(pictureId, response); } } } 新增消息类型时,只需实现新的 Handler,而不必修改原有代码。 Disruptor 优化 Disruptor原理 在 Spring MVC / WebSocket 场景里,如果接口(或消息处理)内部存在耗时操作,请求线程会被长时间占用,最终可能把 Tomcat 的请求线程/连接池耗尽(默认 200)。 实践中,绝大多数请求是“快请求”(毫秒级),可在请求线程内直接完成;少量“慢请求”(秒级)应当切到异步线程执行,做到快速返回 + 后台处理。 Disruptor 是一套高性能并发框架,核心是无锁(或低锁)的环形队列 RingBuffer,为高吞吐/低延迟场景而生。相较常规队列,Disruptor 通过序号(sequence)、缓存命中和内存屏障等机制,实现了极低延迟与有序消费。 引入 Disruptor 的主要作用: 把耗时的业务处理从 WebSocket / Tomcat 请求线程中解耦出来,交给一个高性能的异步消息通道去处理,从而让前端请求能尽快返回,不会因为几个慢操作就把服务器的请求线程全堵死。 同一条事件流在 RingBuffer 中按序号消费,避免多线程乱序导致的业务问题(比如图片编辑步骤错乱)。 工作流程(直观理解): 1)环形队列初始化:创建固定大小的 RingBuffer(如 8),底层是可复用的事件对象数组,全局使用递增的序号标记事件顺序。 2)生产者写入数据:申请一个可写序号 → 将数据写入事件对象 → 发布(publish)成功后,序号递增。 3)消费者读取数据:按序检查可读序号 → 取出对应事件 → 处理 → 提交后继续下一个序号。 4)环形队列循环使用:写到末尾回到起点(环形),但序号持续递增保证先后顺序。 5)防止数据覆盖:若生产速度追上了消费速度,生产者会等待,确保未处理的数据不会被覆盖(“背压机制(Backpressure)” )。 6)解耦与异步:WebSocket 收到消息后直接投递到 RingBuffer,由 Disruptor 的消费者按序处理,实现快速入队 + 后台串行/并行消费。 WebSocket+Disruptor完整流程 用户 A (前端)通过 WebSocket 发送编辑消息(如旋转图片)。 WebSocket 服务端(Disruptor 生产者 Producer) 接收消息 → 解析成事件对象(如 EditEvent) 从 Disruptor 的 RingBuffer 申请一个可写序号(next())。 将事件数据(用户信息、操作类型等)写入该槽位。 调用 publish() 发布事件,标记为“已可消费”。 Disruptor 消费者 收到已发布的事件(按序号顺序消费); 调用对应的业务逻辑(如图片旋转、滤镜、保存等); 处理完成后触发后续逻辑(如广播消息)。 后端广播:向所有正在编辑该图片的 WebSocket 会话广播消息。 { "type": "EDIT_ACTION", "message": "用户 A 执行了编辑操作: rotate", "user": { "userName": "A" }, "editAction": "rotate" } 前端接收并更新 UI:所有用户(如用户 B)接收到编辑操作的通知,并在界面上实时更新编辑状态。 多实例扩展说明 原则:同一张图片(同一个 pictureId)的所有 WebSocket 连接,必须落在同一后端实例,这样才能: 保证消息顺序一致; 保证广播能触达该图下所有用户; 避免跨实例状态不同步。 不能出现:同一个 pictureId 分别有一部分连接在实例 A、另一部分在实例 B。否则你本地内存里的 pictureSessions Map 就会被割裂,广播、顺序都乱掉。 Disruptor 仅作为 单机内事件队列(即 WebSocket 服务端实例内部的低延迟队列)。它解决的是本机的高性能并发调度问题,不会帮你做跨实例同步。因此,只要保证同一个 pictureId 的连接都路由到同一实例,Disruptor 就能无缝工作,不管集群里有多少实例。 缓存技术 图片列表多级缓存 多级缓存是指结合本地缓存和分布式缓存的优点,在同一业务场景下构建两级缓存系统,这样可以兼顾本地缓存的高性能、以及分布式缓存的数据一致性和可靠性。 缓存Key拼接思路 目前,对图片列表的查询进行了缓存处理,包括公共图库(public)以及私有和团队空间。缓存的 key 由 空间 ID(spaceId)+ 当前页码(current)+ 每页显示数量(size)+ 标签(tags) + 类别(category)+ 搜索框(searchText) 组成。具体缓存Key生成方式如下: // 2) 统一 namespace(便于按空间批量清理) String namespace = (spaceId == null) ? "public" : String.valueOf(spaceId); // 3) 参与哈希的查询参数(稳定顺序 + 规范化) List<String> sortedTags; List<String> tags = queryRequest.getTags(); if (tags == null || tags.isEmpty()) { // 后面不需要往里加元素时用它最省心 sortedTags = Collections.emptyList(); } else { // 拷贝一份,避免改动原始参数 sortedTags = new ArrayList<>(tags); Collections.sort(sortedTags); // 自然顺序排序 } Map<String, Object> params = new LinkedHashMap<>(); params.put("category", Optional.ofNullable(queryRequest.getCategory()).orElse("")); params.put("tags", sortedTags); params.put("searchText", Optional.ofNullable(queryRequest.getSearchText()).orElse("")); params.put("current", current); params.put("size", size); // 4) 稳定序列化 + MD5 String queryJson = JSONUtil.toJsonStr(params); String hash = DigestUtil.md5Hex(queryJson); // 5) 统一 Key:版本 + 空间 + 哈希 String cacheKey = "smilepicture:listPictureVOByPage:v1:" + namespace + ":" + hash; 查缓存整体思路 整体采用 本地缓存(Caffeine) + 分布式缓存(Redis) + 分布式锁 的两级缓存机制,主要流程: 本地缓存(一级缓存)优先(Caffeine) 本地查cacheKey,命中直接返回,最快速,减少 Redis 压力。 Redis 二级缓存 本地未命中时查 Redis,如果命中则回写本地缓存。 分布式互斥锁防击穿 Boolean ok = stringRedisTemplate .opsForValue() .setIfAbsent(lockKey, token, Duration.ofMillis(expireMs)); 如果 Redis 也未命中,则尝试获取 lock:{cacheKey} 的分布式锁(非cacheKey) token:采用UUID生成的唯一标识,确保锁的持有者身份 双重检查:拿到锁后再次查 Redis,防止并发期间已有线程写入。 如果依旧未命中,则回源数据库: 非空数据:正常写入缓存,TTL = redisExpireSeconds。 空数据:写入短期缓存(TTL = 60 秒),防止缓存穿透。 用 Lua 脚本安全释放锁,保证只释放自己的锁。 未拿到锁的线程自旋等待 没拿到锁的线程不会立刻查 DB,而是自旋等待: 每隔 WAIT_INTERVAL_MS=80ms 查询一次 Redis; 最多自旋 WAIT_TIMES=8 次(约 640ms); 如果在等待中 Redis 有数据,则直接返回; 如果等完还没有,就兜底去 DB,但不写缓存(由持锁线程负责)。 防缓存击穿:分布式锁 + 双重检查 + 自旋等待。 防缓存穿透:空值缓存(写入 60 秒的空 JSON 或空集合)。 两级缓存:Caffeine + Redis,提升查询性能。 安全解锁:Lua 脚本校验 token,确保不会误删他人锁。 防缓存雪崩:随机过期时间, int expire = 300 + RandomUtil.*randomInt*(0, 300); 。这样可以确保缓存的失效时间不会同时过期,提升缓存的稳定性。 为什么双重检查? 线程 A 慢查询,锁过期 T0:线程 A 先到,发现缓存没有 → 拿到锁(锁 5s)。 T1:A 去查数据库(假设这一步耗时 6s,很慢)。 T2 (5s 到达):A 还在查 DB,但锁自动过期了(Redis 释放锁)。 T3:线程 B 进来,发现 Redis 里还是没数据 → 成功拿到锁。 T4:线程 A 查完 DB,写入 Redis,但还没来得及释放锁。 T5:线程 B 开始执行 → 如果没有双重检查,它会再查一次 DB。 👉 结果:重复 DB 查询,击穿防护失败一半。 👉 有了双重检查:线程 B 在拿到锁后会再看一眼 Redis,发现 A 已经写好了数据,就不会再查 DB。 缓存删除逻辑 目前,缓存的删除是基于 spaceId 来进行的。逻辑上,当某个空间中的图片发生变化时,需要使该空间下的分页缓存全部失效。 原有删除流程 1.根据空间 ID 拼出 Redis Key 前缀。 2.使用 Redis SCAN 命令批量扫描所有符合前缀的 Key。 3.收集结果后,一次性 DEL 删除,减少网络往返。 4.同步清除本地 Caffeine 缓存中的对应 Key。 现有方案(基于 版本号 + TTL) Key 命名规则 smilepicture:listPictureVOByPage:{namespace}:v{version}:{queryHash} namespace:公开图库用 "public",其它情况用 spaceId。 version:该空间的缓存版本号,存储在 Redis 计数器里。 queryHash:由查询参数(category、tags、searchText、分页参数等)序列化 + MD5 得到,保证不同条件下 key 唯一。 删除流程(O(1) 失效) 1.当空间下的图片发生变化时,不再扫描/删除所有 key。 2.直接对该 namespace 的版本号执行一次 INCR: INCR smilepicture:version:{namespace} 3.新请求自动写入/读取新版本的 Key;旧版本 Key 不再命中。 4.旧缓存依赖 TTL 自动过期清理,无需人工干预。 5.本地缓存 Caffeine 在 bump 版本时同时清理属于该 namespace 的 key。 还可以继续优化 现在的问题就是当某个空间中的图片发生变化时,需要使该空间下的分页缓存全部失效,效率太低。 分层缓存(List Cache + Detail Cache)模式 1)列表缓存(轻量级) Key: gallery:list:{namespace}:v{version}:{queryHash} Value: [101, 102, 103, ...] (只存 ID,顺序信息) 2)详情缓存(精细化) Key: gallery:detail:{id} Value: PictureVO(id、标题、缩略图、时间戳等) 查询流程 用户请求「某空间下第 1 页图片」 先查 列表缓存,得到 ID 数组 [101, 102, 103]。 遍历 ID 数组,批量 MGET 详情缓存: gallery:detail:101 ✅ 命中 gallery:detail:102 ✅ 命中 gallery:detail:103 ❌ 缺失 对于 ❌ 缺失的 ID(比如 103): 回源 DB 查询该图片详情 写入 gallery:detail:103(带 TTL) 拼装成完整的返回结果。 热点Key问题 热点 Key(Hot Key),就是在 Redis 里某个 key 被高并发、大流量频繁访问,导致 单点压力集中,可能出现: Redis 某个节点 CPU 飙升 key 过期瞬间导致 缓存击穿 热点数据频繁刷新,DB 被拖垮 热点检测 在 Redis 前做一层统计,发现哪些 key QPS 异常高。 常见手段: 接入中间件(比如阿里云 Redis、Codis 自带热点监控) 在业务层收集访问日志,做 TopN 统计 1)应用层埋点统计 所有缓存读写操作都会经过一个统一的“入口”,在这个入口里,每次访问某个 key 时,做一次计数。 // 计数器 private final ConcurrentHashMap<String, LongAdder> hotKeyCounter = new ConcurrentHashMap<>(); // 每次访问时调用 public void recordAccess(String key) { hotKeyCounter.computeIfAbsent(key, k -> new LongAdder()).increment(); } // 定期获取 TopN 热点 Key public List<String> getHotKeys(int topN) { return hotKeyCounter.entrySet().stream() .sorted((a, b) -> Long.compare(b.getValue().sum(), a.getValue().sum())) .limit(topN) .map(Map.Entry::getKey) .toList(); } 每隔一段时间(比如 1 分钟)遍历计数器getHotKeys,输出访问量 TopN 的 key。 如果要做 滑动窗口统计,思路是把时间切分成多个小片段(比如每秒一个桶,用数组/环形队列存储),每次请求把计数写到当前时间片。然后定期滚动,把过期的片段丢掉,统计时只合并最近 N 秒的计数。这样就能动态反映出「最近一段时间」的热点 key。用的数据结构一般是 环形数组 + ConcurrentHashMap(每个时间片一个 map),实现简单、并发安全。 解决热点 Key 的常见方法 1)本地缓存 + Redis 二级缓存 2)把一个热点 key 拆成多个副本:原 key hotKey → hotKey:1, hotKey:2, …, hotKey:N 请求时按随机/哈希路由到某个副本。减少单个 key 的压力,让请求分散到多个 key 上。 3)缓存预热 + 永不过期(逻辑过期)对确定的热点 key,在系统启动或活动前 提前写入缓存。缓存里存一个“过期时间字段”,请求先返回旧值,再异步更新。避免热点 key 同时过期,打爆 DB。 缓存值里带一个字段:expireTime。 请求进来时,如果发现 expireTime < now,说明缓存过期: 先返回旧值 给用户(保证不中断服务)。 同时异步启动一个线程,去 DB 拉最新数据,刷新缓存里的值和新的 expireTime。 4)设置随机过期时间(避免雪崩) 5)热点请求打散,只允许一个线程回源,其他线程自旋等待,避免缓存失效时同时回源。
项目
zy123
1年前
0
60
0
2025-03-22
同步本地Markdown至Typecho站点
同步本地Markdown至Typecho站点 本项目基于https://github.com/Sundae97/typecho-markdown-file-publisher 实现效果: 将markdown发布到typecho 发布前将markdown中的公式块和代码块进行格式化,确保能适配md解析器。 发布前将markdown的图片资源上传到自己搭建的图床Easyimage中(自行替换成阿里云OSS等), 并替换markdown中的图片链接。 将md所在的文件夹名称作为post的category(mysql发布可以插入category, xmlrpc接口暂时不支持category操作)。 以title和category作为文章的唯一标识,如果数据库中已有该数据,将会更新现有文章,否则新增文章。 环境:Typecho1.2.1 php8.1.0 项目目录 typecho_markdown_upload/main.py是上传md文件到站点的核心脚本 transfer_md/transfer.py是对md文件进行预处理的脚本。 核心思路 一、预先准备 图床服务器 本人自己在服务器上搭建了私人图床——easyimage,该服务能够实现图片上传并返回公网 URL,这对于在博客中正常显示 Markdown 文件中的图片至关重要。 当然,也可以选择使用公共图床服务,如阿里云 OSS,但这里不做详细介绍。 需手动修改transfer_md/upload_img.py,配置url、token等信息。 参考博客:【好玩儿的Docker项目】10分钟搭建一个简单图床——Easyimage-我不是咕咕鸽 github地址:icret/EasyImages2.0: 简单图床 - 一款功能强大无数据库的图床 2.0版 picgo安装: 使用 Typora + PicGo + Easyimage 组合,可以实现将本地图片直接粘贴到 Markdown 文件中,并自动上传至图床。 下载地址:Releases · Molunerfinn/PicGo 操作步骤如下: 打开 PicGo,点击右下角的小窗口。 进入插件设置,搜索并安装 web-uploader 1.1.1 插件(注意:旧版本可能无法搜索到,建议直接安装最新版本)。 配置插件:在设置中填写 API 地址,该地址可在 Easyimage 的“设置-API设置”中获取。 配置完成后,即可实现图片自动上传,提升 Markdown 编辑体验。 Typora 设置 为了确保在博客中图片能正常显示,编辑 Markdown 文档时必须将图片上传至图床,而不是保存在本地。请按以下步骤进行配置: 在 Typora 中,打开 文件 → 偏好设置 → 图像 选项。 在 “插入图片时” 选项中,选择 上传图片。 在 “上传服务设定” 中选择 PicGo,并指定 PicGo 的安装路径。 文件结构统一: md_files ├── category1 │ ├── file1.md │ └── file2.md ├── category2 │ ├── file3.md │ └── file4.md └── output ├── assets_type ├── pics └── updated_files 注意:category对应上传到typecho中的文章所属的分类。 如果你现有的图片分散在系统中,可以使用 transfer_md/transfer.py 脚本来统一处理。该脚本需要传入三个参数: input_path: 指定包含 Markdown 文件的根目录(例如上例中的 md_files)。 output_path: 输出文件夹(例如上例中的 output)。 type_value: 1:扫描 input_path 下所有 Markdown 文件,将其中引用的本地图片复制到 output_path 中,同时更新 Markdown 文件中的图片 URL 为 output_path 内的路径; 2:为每个 Markdown 文件建立单独的文件夹(以文件名命名),图片存放在文件夹下的 assets 子目录中,整体存入assets_type文件夹中,; 3:扫描 Markdown 文件中的本地图片,将其上传到图床(获取公网 URL),并将 Markdown 文件中对应的图片 URL 替换为公网地址。 4:预处理Markdown 文件,将公式块和代码块格式化,以便于Markdown解析器解析(本地typora编辑器对于md格式比较宽容,但博客中使用的md解析器插件不一定能正确渲染!) 二、使用Git进行版本控制 假设你在服务器上已经搭建了 Gitea (Github、Gitee都行)并创建了一个名为 md_files 的仓库,那么你可以在 md_files 文件夹下通过 Git Bash 执行以下步骤将本地文件提交到远程仓库: 初始化本地仓库: git init 添加远程仓库: 将远程仓库地址添加为 origin(请将 http://xxx 替换为你的实际仓库地址): git remote add origin http://xxx 添加文件并提交: 注意,写一个.gitignore文件将output排除版本控制 git add . git commit -m "Initial commit" 推送到远程仓库: git push -u origin master 后续更新(可写个.bat批量执行): git add . git commit -m "更新了xxx内容" git push 三、在服务器上部署该脚本 1. 确保脚本能够连接到 Typecho 使用的数据库 本博客使用 docker-compose 部署 Typecho(参考:【好玩儿的Docker项目】10分钟搭建一个Typecho博客|太破口!念念不忘,必有回响!-我不是咕咕鸽)。为了让脚本能访问 Typecho 的数据库,我将 Python 应用pyapp也通过 docker-compose 部署,这样所有服务均在同一网络中,互相之间可以直接通信。 参考docker-compose.yml如下: services: nginx: image: nginx ports: - "4000:80" # 左边可以改成任意没使用的端口 restart: always environment: - TZ=Asia/Shanghai volumes: - ./typecho:/var/www/html - ./nginx:/etc/nginx/conf.d - ./logs:/var/log/nginx depends_on: - php networks: - web php: build: php restart: always expose: - "9000" # 不暴露公网,故没有写9000:9000 volumes: - ./typecho:/var/www/html environment: - TZ=Asia/Shanghai depends_on: - mysql networks: - web pyapp: build: ./markdown_operation # Dockerfile所在的目录 restart: "no" volumes: - /home/zy123/md_files:/markdown_operation/md_files networks: - web env_file: - .env depends_on: - mysql mysql: image: mysql:5.7 restart: always environment: - TZ=Asia/Shanghai expose: - "3306" # 不暴露公网,故没有写3306:3306 volumes: - ./mysql/data:/var/lib/mysql - ./mysql/logs:/var/log/mysql - ./mysql/conf:/etc/mysql/conf.d env_file: - mysql.env networks: - web networks: web: 注意:如果你不是用docker部署的typecho,只要保证脚本能连上typecho所使用的数据库并操纵里面的表就行! 2. 将 md_files 挂载到容器中,保持最新内容同步 这样有几个优势: 不需要每次构建镜像或进入容器手动拉取; 本地更新 md_files 后,容器内自动同步,无需额外操作; 保持了宿主机上的 Git 版本控制和容器内的数据一致性。 3.仅针对 pyapp 服务进行重构和启动,不影响其他服务的运行: pyapp是本Python应用在容器内的名称。 1.构建镜像: docker-compose build pyapp 2.启动容器并进入 Bash: docker-compose run --rm -it pyapp /bin/bash 3.在容器内运行脚本: python typecho_markdown_upload/main.py 2、3两步可合并为: docker-compose run --rm pyapp python typecho_markdown_upload/main.py 此时可以打开博客验证一下是否成功发布文章了! 如果失败,可以验证mysql数据库: 1️⃣ 进入 MySQL 容器: docker-compose exec mysql mysql -uroot -p # 输入你的 root 密码 2️⃣ 切换到 Typecho 数据库并列出表: USE typecho; SHOW TABLES; 3️⃣ 查看 typecho_contents 表结构(文章表): DESCRIBE typecho_contents; mysql> DESCRIBE typecho_contents; +--------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+------------------+------+-----+---------+----------------+ | cid | int(10) unsigned | NO | PRI | NULL | auto_increment | | title | varchar(150) | YES | | NULL | | | slug | varchar(150) | YES | UNI | NULL | | | created | int(10) unsigned | YES | MUL | 0 | | | modified | int(10) unsigned | YES | | 0 | | | text | longtext | YES | | NULL | | | order | int(10) unsigned | YES | | 0 | | | authorId | int(10) unsigned | YES | | 0 | | | template | varchar(32) | YES | | NULL | | | type | varchar(16) | YES | | post | | | status | varchar(16) | YES | | publish | | | password | varchar(32) | YES | | NULL | | | commentsNum | int(10) unsigned | YES | | 0 | | | allowComment | char(1) | YES | | 0 | | | allowPing | char(1) | YES | | 0 | | | allowFeed | char(1) | YES | | 0 | | | parent | int(10) unsigned | YES | | 0 | | | views | int(11) | YES | | 0 | | | agree | int(11) | YES | | 0 | | +--------------+------------------+------+-----+---------+----------------+ 4️⃣ 查询当前文章数量(确认执行前后有无变化): SELECT COUNT(*) AS cnt FROM typecho_contents; 自动化 1.windows下写脚本自动/手动提交每日更新 2.在 Linux 服务器上配置一个定时任务,定时执行 git pull 命令和启动脚本更新博客的命令。 创建脚本/home/zy123/typecho/deploy.sh #!/bin/bash cd /home/zy123/md_files || exit git pull cd /home/zy123/typecho || exit docker compose run --rm pyapp python typecho_markdown_upload/main.py 赋予可执行权限chmod +x /home/zy123/deploy.sh 编辑 Crontab 安排任务(每天0点10分执行) 打开 crontab 编辑器:$crontab -e$ 10 0 * * * /home/zy123/typecho/deploy.sh >> /home/zy123/typecho/deploy.log 2>&1 3.注意md_files文件夹所属者和deploy.sh的所属者需要保持一致。否则会报: fatal: detected dubious ownership in repository at '/home/zy123/md_files' To add an exception for this directory, call: git config --global --add safe.directory /home/zy123/md_files TODO typecho_contents表中的slug字段代表链接中的日志缩略名,如wordpress风格 /archives/{slug}.html,目前是默认int自增,有需要的话可以在插入文章时手动设置该字段。
项目
zy123
1年前
0
146
0
1
2
下一页