产品官网:智标领航 - 招投标AI解决方案
产品后台:xxx
项目地址:xxx
git clone地址:xxx
选择develop分支,develop-xx 后面的xx越近越新。
正式环境:xxx
测试环境:xxx
大解析:指从招标文件解析入口进去,upload.py
小解析:从投标文件生成入口进去,little_zbparse 和get_deviation,两个接口后端一起调
项目启动与维护:
.env存放一些密钥(大模型、textin等),它是gitignore忽略了,因此在服务器上git pull项目的时候,这个文件不会更新(因为密钥比较重要),需要手动维护服务器相应位置的.env。
如何更新服务器上的版本:
步骤
- 进入项目文件夹

**注意:**需要确认.env是否存在在服务器,默认是隐藏的 输入cat .env 如果不存在,在项目文件夹下sudo vim .env
将密钥粘贴进去!!!
-
git pull
-
sudo docker-compose up --build -d 更新并重启
或者 sudo docker-compose build 先构建镜像
sudo docker-compose up -d 等空间时再重启
- sudo docker-compose logs flask_app --since 1h 查看最近1h的日志(如果重启后报错也能查看,推荐重启后都运行一下这个)
requirements.txt一般无需变动,除非代码中使用了新的库,也要手动在该文件中添加包名及对应的版本
docker基础知识
docker-compose:
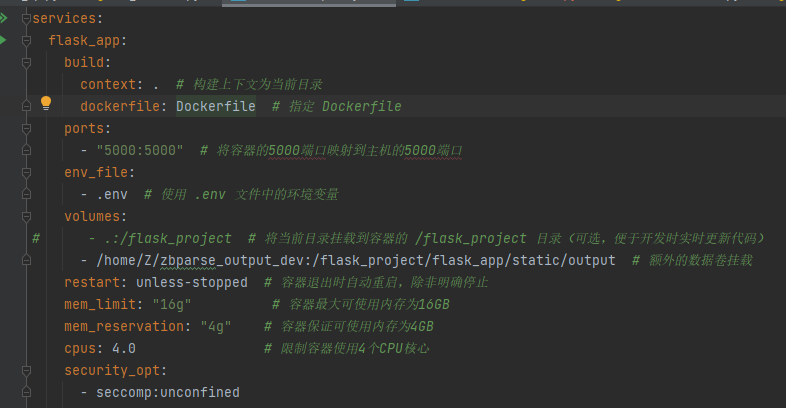
本项目为单服务项目,只有flask_app(服务名)
build context(context: .):
这是在构建镜像时提供给 Docker 的文件集,指明哪些文件可以被 Dockerfile 中的 COPY 或 ADD 指令使用。它是构建过程中的“资源包”。
对于多服务,build下就要针对不同的服务,指定所需的“资源包”和对应的Dockerfile
dockerfile:
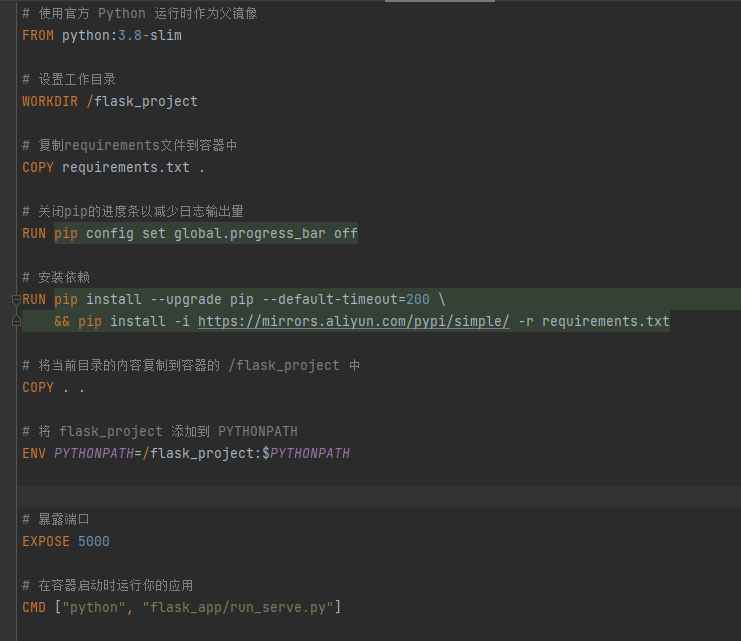
COPY . .(在 Dockerfile 中):
这条指令会将构建上下文中的所有内容复制到镜像中的当前工作目录(这里是 /flask_project)。
docker exec -it zbparse-flask_app-1 sh
这个命令会直接进入到flask_project目录内部ls之后可以看到:
Dockerfile README.md docker-compose.yml flask_app md_files requirements.txt
如果这个基础上再cd /会切换到这个容器的根目录,可以看到flask_project文件夹以及其他基础系统环境。如:
bin boot dev etc flask_project home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
数据卷挂载:
volumes: -/home/Z/zbparse_output_dev:/flask_project/flask_app/static/output # 额外的数据卷挂载
本地路径:容器内路径 都从根目录找起。
完整的容器名
<项目名>-<服务名>-<序号>
项目名:默认是当前目录的名称(这里是 zbparse),或者你在启动 Docker Compose 时通过 -p 参数指定的项目名称。
服务名:在 docker-compose.yml 文件中定义的服务名称(这里是 flask_app)。
序号:如果同一个服务启动了多个容器,会有数字序号来区分(这里是 1)。
docker-compose exec flask_app sh
docker exec -it zbparse-flask_app-1 sh
这两个是等价的,因为docker-compose 会自动找到对应的完整容器名并执行命令。
删除所有悬空镜像(无容器引用的 <none> 镜像)
docker image prune
如何本地启动本项目:
Pycharm启动
- requirements.txt里的环境要配好 conda create -n zbparse python=3.8 conda activate zbparse pip install -r requirements.txt
- .env环境配好 (一般不需要在电脑环境变量中额外配置了,但是要在Pycharm中安装插件,使得项目在启动时能将env中的环境变量自动配置到系统环境变量中!!!)
- 点击下拉框,Edit configurations

设置run_serve.py为启动脚本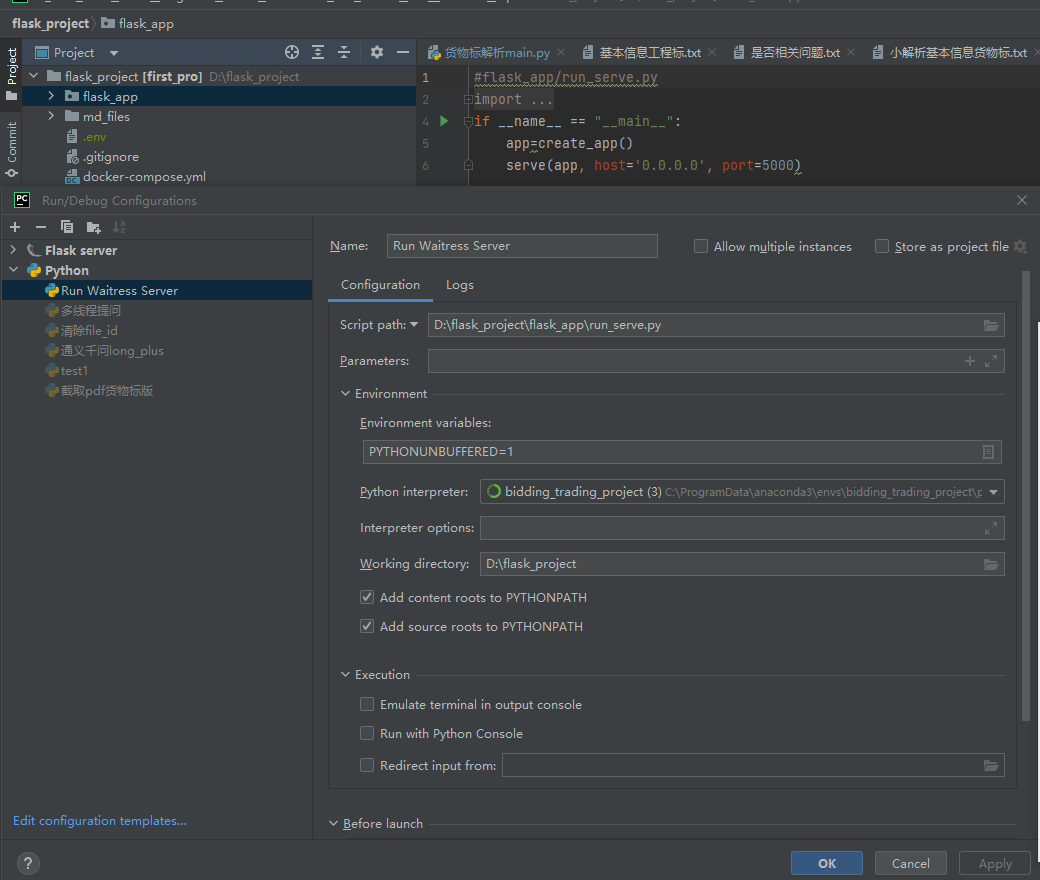 注意这里的working directory要设置到最外层文件夹,而不是flask_app!!!
注意这里的working directory要设置到最外层文件夹,而不是flask_app!!!
命令行启动
1.编写ps1脚本
# 切换到指定目录
cd D:\PycharmProjects\zbparse
# 激活 Conda 环境
conda activate zbparse
# 检查是否存在 .env 文件
if (Test-Path .env) {
# 读取 .env 文件并设置环境变量
Get-Content .env | ForEach-Object {
if ($_ -match '^\s*([^=]+)=(.*)') {
$name = $matches[1].Trim()
$value = $matches[2].Trim()
[System.Environment]::SetEnvironmentVariable($name, $value)
}
}
} else {
Write-Host ".env not find"
}
# 设置 PYTHONPATH 环境变量
$env:PYTHONPATH = "D:\flask_project"
# 运行 Python 脚本
python flask_app\run_serve.py
$env:PYTHONPATH = "D:\flask_project",告诉 Python 去 D:\flask_project 查找模块,这样就能让 Python 找到你的 flask_app 包。
2.确保conda已添加到系统环境变量
-
打开 Anaconda Prompt,然后输入
where conda来查看 conda 的路径。 -
打开系统环境变量Path,添加一条:C:\ProgramData\anaconda3\condabin 或者 CMD 中 set PATH=%PATH%;新添加的路径 -
重启终端可以刷新环境变量
3.如果你尚未在 PowerShell 中初始化 conda,可以在 Anaconda Prompt 中运行:
conda init powershell
4.进入到存放run.ps1文件的目录,在搜索栏中输入powershell
5.默认情况下,PowerShell 可能会阻止运行脚本。你可以调整执行策略:
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
6.运行脚本
.\run.ps1
注意!!!
Windows 控制台存在QuickEdit 模式,在 QuickEdit 模式下,当你在终端窗口中点击(尤其是拖动或选中内容)时,控制台会进入文本选择状态,从而暂停正在运行的程序!!
禁用 QuickEdit 模式
- 在 PowerShell 窗口标题栏上点击右键,选择“属性”。
- 在“选项”选项卡中,取消勾选“快速编辑模式”。
- 点击“确定”,重启 PowerShell 窗口后再试。
模拟用户请求
postman打post请求测试:
body:
{
"file_url":"xxxx",
"zb_type":2
} file_url如何获取:OSS管理控制台
bid-assistance/test 里面找个文件的url,推荐'094定稿-湖北工业大学xxx' 注意这里的url地址有时效性,要经常重新获取新的url
清理服务器上的文件夹
1.编写shell文件,sudo vim clean_dir.sh
清理/home/Z/zbparse_output_dev下的output1这些二级目录下的c8d2140d-9e9a-4a49-9a30-b53ba565db56这种uuid的三级目录(只保留最近7天)。
#!/bin/bash
# 需要清理的 output 目录路径
ROOT_DIR="/home/Z/zbparse_output_dev"
# 检查目标目录是否存在
if [ ! -d "$ROOT_DIR" ]; then
echo "目录 $ROOT_DIR 不存在!"
exit 1
fi
echo "开始清理 $ROOT_DIR 下超过 7 天的目录..."
echo "以下目录将被删除:"
# -mindepth 2 表示从第二层目录开始查找,防止删除 output 下的直接子目录(如 output1、output2)
# -depth 采用深度优先遍历,确保先处理子目录再处理父目录
find "$ROOT_DIR" -mindepth 2 -depth -type d -mtime +7 -print -exec rm -rf {} \;
echo "清理完成。"
2.添加权限。
sudo chmod +x ./clean_dir.sh
3.执行
sudo ./clean_dir.sh
以 root 用户的身份编辑 crontab 文件,从而设置或修改系统定时任务(cron jobs)。每天零点10分清理
sudo crontab -e
在里面添加:
10 0 * * * /home/Z/clean_dir.sh
目前测试服务器和正式服务器都写上了!无需变动
内存泄漏问题
问题定位
查看容器运行时占用的文件FD套接字FD等(排查内存泄漏,长期运行这三个值不会很大)
[Z@iZbp13rxxvm0y7yz7l02hbZ zbparse]$ docker exec -it zbparse-flask_app-1 sh
ls -l /proc/1/fd | awk '
BEGIN {
file=0; socket=0; pipe=0; other=0
}
{
if(/socket:/) socket++
else if(/pipe:/) pipe++
else if(/\/|tmp/) file++ # 识别文件路径特征
else other++
}
END {
print "文件FD:", file
print "套接字FD:", socket
print "管道FD:", pipe
print "其他FD:", other
}'
可以发现文件FD很大,基本上发送一个请求文件FD就加一,且不会衰减:
经排查,@validate_and_setup_logger注解会为每次请求都创建一个logger,需要在@app.teardown_request中获取与本次请求有关的logger并释放。
def create_logger(app, subfolder):
"""
创建一个唯一的 logger 和对应的输出文件夹。
参数:
subfolder (str): 子文件夹名称,如 'output1', 'output2', 'output3'
"""
unique_id = str(uuid.uuid4())
g.unique_id = unique_id
output_folder = os.path.join("flask_app", "static", "output", subfolder, unique_id)
os.makedirs(output_folder, exist_ok=True)
log_filename = "log.txt"
log_path = os.path.join(output_folder, log_filename)
logger = logging.getLogger(unique_id)
if not logger.handlers:
file_handler = logging.FileHandler(log_path)
file_formatter = CSTFormatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(file_formatter)
logger.addHandler(file_handler)
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(logging.Formatter('%(message)s'))
logger.addHandler(stream_handler)
logger.setLevel(logging.INFO)
logger.propagate = False
g.logger = logger
g.output_folder = output_folder #输出文件夹路径
handler:每当 logger 生成一条日志信息时,这条信息会被传递给所有关联的 handler,由 handler 决定如何输出这条日志。例如,FileHandler 会把日志写入文件,而 StreamHandler 会将日志输出到控制台。
logger.setLevel(logging.INFO) :它设置了 logger 的日志级别阈值。Logger 只会处理大于或等于 INFO 级别的日志消息(例如 INFO、WARNING、ERROR、CRITICAL),而 DEBUG 级别的消息会被忽略。
解决这个文件句柄问题后内存泄漏仍未解决,考虑分模块排查。
本项目结构大致是**1.**预处理(文件读取切分) **2.**并发调用5个函数分别调用大模型获取结果。
因此排查思路:
先将预处理模块单独拎出来作为接口,上传文件测试。
文件一般几MB,首先会读到内存,再处理,必然会占用很多内存,且它是调用每个接口都会经历的环节(little_zbparse/upload等)
内存泄漏排查工具
pip install memory_profiler
from memory_profiler import memory_usage
import time
@profile
def my_function():
a = [i for i in range(100000)]
time.sleep(1) # 模拟耗时操作
b = {i: i*i for i in range(100000)}
time.sleep(1)
return a, b
# 监控函数“运行前”和“运行后”的内存快照
mem_before = memory_usage()[0]
result=my_function()
mem_after = memory_usage()[0]
print(f"Memory before: {mem_before} MiB, Memory after: {mem_after} MiB")
@profile注解加在函数上,可以逐行分析内存增减情况。
memory_usage()[0] 可以获取当前程序所占内存的快照
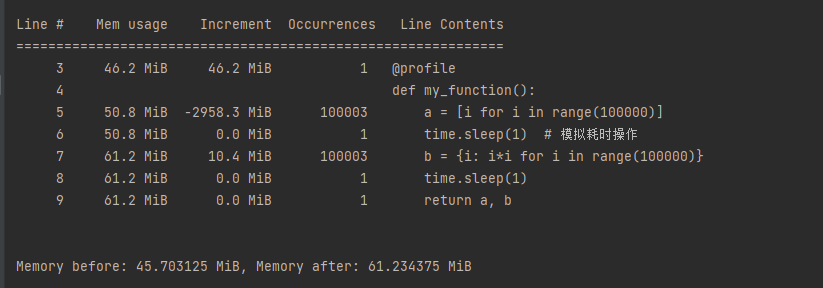
产生的数据都存到result变量-》内存中,这是正常的,因此my_function没有内存泄漏问题。 但是
@profile
def extract_text_by_page(file_path):
result = ""
with open(file_path, 'rb') as file:
reader =PdfReader(file)
num_pages = len(reader.pages)
# print(f"Total pages: {num_pages}")
for page_num in range(num_pages):
page = reader.pages[page_num]
text = page.extract_text()
return ""

可以发现尽管我返回"",内存仍然没有释放!因为就是读取pdf这块发生了内存泄漏!
tracemalloc
def extract_text_by_page(file_path):
result = ""
with open(file_path, 'rb') as file:
reader =PdfReader(file)
num_pages = len(reader.pages)
# print(f"Total pages: {num_pages}")
for page_num in range(num_pages):
page = reader.pages[page_num]
text = page.extract_text()
return result
# 开始跟踪内存分配
tracemalloc.start()
# 捕捉函数调用前的内存快照
snapshot_before = tracemalloc.take_snapshot()
# 调用函数
file_path=r'C:\Users\Administrator\Desktop\fsdownload\00550cfc-fd33-469e-8272-9215291b175c\ztbfile.pdf'
result = extract_text_by_page(file_path)
# 捕捉函数调用后的内存快照
snapshot_after = tracemalloc.take_snapshot()
# 比较两个快照,获取内存分配差异信息
stats = snapshot_after.compare_to(snapshot_before, 'lineno')
print("[ Top 10 内存变化 ]")
for stat in stats[:10]:
print(stat)
# 停止内存分配跟踪
tracemalloc.stop()

tracemalloc能更深入的分析,不仅是自己写的代码,调用的库函数产生的内存也能分析出来。在这个例子中就是PyPDF2中的各个函数占用了大部分内存。
综上,定位到问题,就是读取PDF,使用PyPDF2库的地方
如何解决:
- 首先尝试用with open打开文件,代替直接使用
reader =PdfReader(file_path)
能够确保文件正常关闭。但是没有效果。
-
考虑为每次请求开子进程处理,有效隔离内存泄漏导致的资源占用,这样子进程运行结束后会释放资源。
-
但是解析流程是流式/分段返回的,因此还需处理:
_child_target 是一个“桥梁”:
- 它在子进程内调用
goods_bid_main(...)(你的生成器) 并把每一次yield得到的数据放进队列。 - 结束时放一个
None表示没有更多数据。
run_in_subprocess 是主进程使用的接口,开启子进程:
- 它启动子进程并实时
get()队列数据,然后yield给外界调用者。 - 当队列里读到
None,说明子进程运行完毕,就break循环并p.join()。
main_func是真正执行的函数!!!
def _child_target(main_func, queue, output_folder, file_path, file_type, unique_id):
"""
子进程中调用 `main_func`(它是一个生成器函数),
将其 yield 出的数据逐条放进队列,最后放一个 None 表示结束。
"""
try:
for data in main_func(output_folder, file_path, file_type, unique_id):
queue.put(data)
except Exception as e:
# 如果要把异常也传给父进程,以便父进程可感知
queue.put(json.dumps({'error': str(e)}, ensure_ascii=False))
finally:
queue.put(None)
def run_in_subprocess(main_func, output_folder, file_path, file_type, unique_id):
"""
启动子进程调用 `main_func(...)`,并在父进程流式获取其输出(通过 Queue)。
子进程结束时,操作系统回收其内存;父进程则保持实时输出。
"""
queue = multiprocessing.Queue()
p = multiprocessing.Process(
target=_child_target,
args=(main_func, queue, output_folder, file_path, file_type, unique_id)
)
p.start()
while True:
item = queue.get() # 阻塞等待子进程产出的数据
if item is None:
break
yield item
p.join()
如果开子线程,线程共享同一进程的内存空间,所以如果发生内存泄漏,泄漏的内存会累积在整个进程中,影响所有线程。
开子进程的缺点:多进程通常消耗的系统资源(如内存、启动开销)比多线程要大,因为每个进程都需要独立的资源和上下文切换开销。
进程池
在判断上传的文件是否为招标文件时,需要快速准确地响应。因此既保证内存不泄漏,又保证速度的方案就是在项目启动时创建进程池。(因为创建进程需要耗时2到3秒!)
如果是Waitress服务器启动,这里的进程池是全局共享的;但如果Gunicorn启动,每个请求分配一个worker进程,进程池是在worker里面共享的!!!
#创建app,启动时
def create_app():
# 创建全局日志记录器
app = Flask(__name__)
app.process_pool = Pool(processes=10, maxtasksperchild=3)
app.global_logger = create_logger_main('model_log') # 全局日志记录器
#调用时
pool = current_app.process_pool # 使用全局的进程池
def judge_zbfile_exec_sub(file_path):
result = pool.apply(
judge_zbfile_exec, # 你的实际执行函数
args=(file_path,)
)
return result
但是存在一个问题:第一次发送请求执行时间较慢!
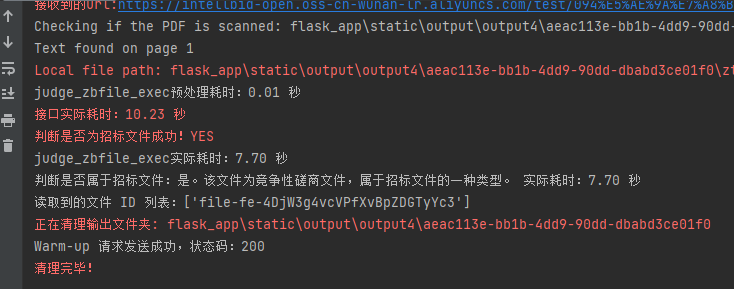
可以发现实际执行只需7.7s,但是接口实际耗时10.23秒,主要是因懒加载或按需初始化:有些模块或资源在子进程启动时并不会马上加载,而是在子进程首次真正执行任务时才进行初始化。
解决思路:提前热身(warm up)进程池
在应用启动后、还没正式接受请求之前,可以提交一个简单的“空任务”或非常小的任务给进程池,让子进程先完成相关的初始化。这种“预热”方式能在正式请求到来之前就完成大部分初始化,减少首次请求的延迟。
还可以快速验证服务是否正常启动
def warmup_request():
# 等待服务器完全启动,例如等待 1-2 秒
time.sleep(5)
try:
url = "http://127.0.0.1:5000/judge_zbfile"
#url必须为永久地址,完成热启动,创建进程池
payload = {"file_url": "xxx"} # 根据实际情况设置 file_url
headers = {"Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print(f"Warm-up 请求发送成功,状态码:{response.status_code}")
except Exception as e:
print(f"Warm-up 请求出错:{e}")
threading.Thread(target=warmup_request, daemon=True).start()
flask_app结构介绍
项目中做限制的地方
账号、服务器分流
服务器分流:目前linux服务器和windows服务器主要是硬件上的分流(文件切分需要消耗CPU资源),大模型基底还是调用阿里,共用的tpm qpm。
账号分流:qianwen_plus下的
api_keys = cycle([
os.getenv("DASHSCOPE_API_KEY"),
# os.getenv("DASHSCOPE_API_KEY_BACKUP1"),
# os.getenv("DASHSCOPE_API_KEY_BACKUP2")
])
api_keys_lock = threading.Lock()
def get_next_api_key():
with api_keys_lock:
return next(api_keys)
api_key = get_next_api_key()
只需轮流使用不同的api_key即可。目前没有启用。
大模型的限制
general/llm下的doubao.py 和通义千问long_plus.py 目前是linux和windows各部署一套,因此项目中的qps是对半的,即calls=?
- 这是qianwen-long的限制(针对阿里qpm为1200,每秒就是20,又linux和windows服务器对半,就是10;TPM无上限)
@sleep_and_retry
@limits(calls=10, period=1) # 每秒最多调用10次
def rate_limiter():
pass # 这个函数本身不执行任何操作,只用于限流
-
这是qianwen-plus的限制(针对tpm为1000万,每个请求2万tokens,那么linux和windows总的qps为8时,8x60x2=960<1000。单个为4) 经过2.11号测试,calls=4时最高TPM为800,因此把目前稳定版把calls设为5
2.12,用turbo作为超限后的承载,目前把calls设为7
@sleep_and_retry
@limits(calls=7, period=1) # 每秒最多调用7次
def qianwen_plus(user_query, need_extra=False):
logger = logging.getLogger('model_log') # 通过日志名字获取记录器
- qianwen_turbo的限制(TPM为500万,由于它是plus后的手段,稳妥一点,qps设为6,两个服务器分流即calls=3)
@sleep_and_retry
@limits(calls=3, period=1) # 500万tpm,每秒最多调用6次,两个服务器分流就是3次 (plus超限后的保底手段,稳妥一点)
重点!!后续阿里扩容之后成倍修改这块calls=?
如果不用linux和windows负载均衡,这里的calls也要乘2!!
接口的限制
- start_up.py的def create_app()函数,限制了对每个接口同时100次请求。这里事实上不再限制了(因为100已经足够大了),默认限制做到大模型限制这块。
app.connection_limiters['upload'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['get_deviation'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['default'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['judge_zbfile'] = ConnectionLimiter(max_connections=100)
-
ConnectionLimiter.py以及每个接口上的装饰器,如
@require_connection_limit(timeout=1800) def zbparse():这里限制了每个接口内部执行的时间,暂时设置到了30分钟!(不包括排队时间)超时就是解析失败
后端的限制:
目前后端发起招标请求,如果发送超过100(max_connections=100)个请求,我这边会排队后面的请求,这时后端的计时器会将这些请求也视作正在解析中,事实上它们还在排队等待中,这样会导致在极端情况下,新进的解析文件速度大于解析的速度,排队越来越长,后面的文件会因为等待时间过长而直接失败,而不是'解析失败'。
general
是公共函数存放的文件夹,llm下是各类大模型,读取文件下是docx pdf文件的读取以及文档清理clean_pdf,去页眉页脚页码
general下的llm下的清除file_id.py 需要每周运行至少一次,防止file_id数量超出(我这边对每次请求结束都有file_id记录并清理,向应该还没加)
llm下的model_continue_query是'模型继续回答'脚本,应对超长文本模型一次无法输出完的情况,继续提问,拼接成完整的内容。
general下的file2markdown是textin 文件--》markdown
general下的format_change是pdf-》docx 或doc/docx->pdf
general下的merge_pdfs.py是拼接文件的:1.拼接招标公告+投标人须知 2.拼接评标细则章节+资格审查章节
general中比较重要的!!!
后处理:
general下的post_processing,解析后的后处理部分,包括extract_info、 资格审查、技术偏离 商务偏离 所需提交的证明材料,都在这块生成。
post_processing中的inner_post_processing专门提取extracted_info
post_processing中的process_functions_in_parallel提取
资格审查、技术偏离、 商务偏离、 所需提交的证明材料
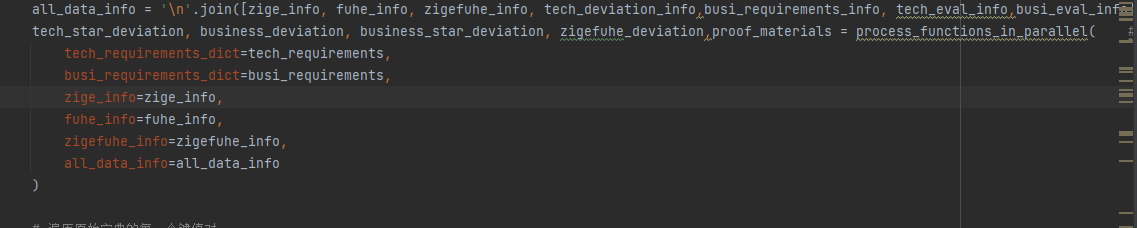
大解析upload用了post_processing完整版,
little_zbparse.py、小解析main.py用了inner_post_processing
get_deviation.py、偏离表数据解析main.py用了process_functions_in_parallel
截取pdf:
截取pdf_main.py是顶级函数,
二级是截取pdf货物标版.py和截取pdf工程标版.py (非general下)
三级是截取pdf通用函数.py
如何判断截取位置是否正确?根据output文件夹中的切分情况(打开各个文件查看是否切分准确,目前的逻辑主要是按大章切分,即'招标公告'章节)
如果切分不准确,如何定位正则表达式?
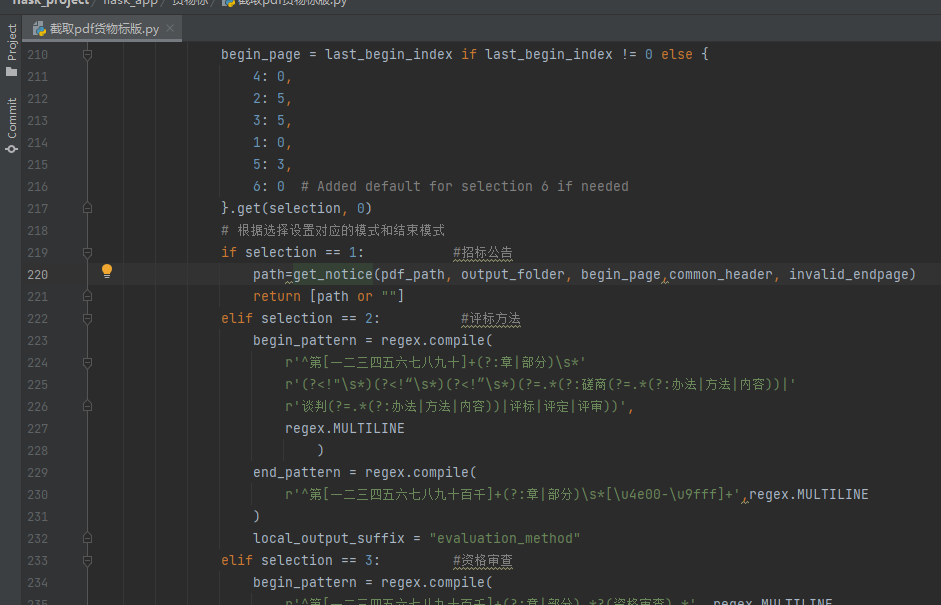
首先判断当前是工程标解析还是货物标解析,即zb_type=1还是2
如果是2,那么是货物标解析,那么就是截取pdf_main.py调用截取pdf货物标版.py,如下图,selection=1代表截取'招标公告',那么如果招标公告没有切准,就在这块修改。这里可以发现get_notice是通用函数,即截取pdf通用函数.py中的get_notice函数,那么继续往内部跳转。
若开头没截准,就改begin_pattern,末尾没截准,就改end_pattern
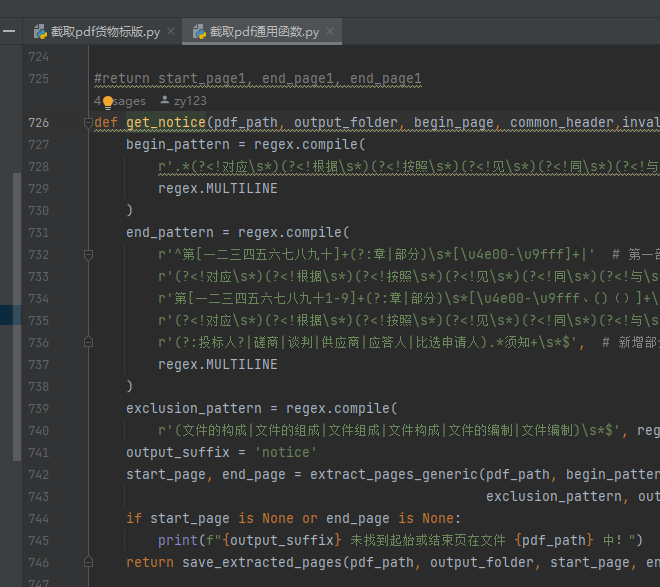
另外:在截取pdf货物标版.py中,还有extract_pages_twice函数,即第一次没有切分到之后,会运行该函数,这边又有一套begin_pattern和end_pattern,即二次提取
如何测试?
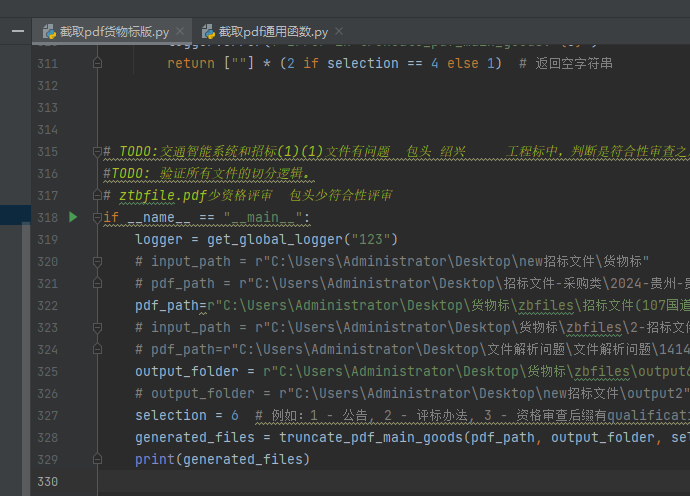
输入pdf_path,和你要切分的序号,selection=1代表切公告,依次类推,可以看切出来的效果如何。
无效标和废标公共代码
获取无效标与废标项的主要执行代码。对docx文件进行预处理=》正则=》temp.txt=》大模型筛选 如果提的不全,可能是正则没涵盖到位,也可能是大模型提示词漏选了。
这里:如果段落中既被正则匹配,又被follow_up_keywords中的任意一个匹配,那么不会添加到temp中(即不会被大模型筛选),它会直接添加到最后的返回中!
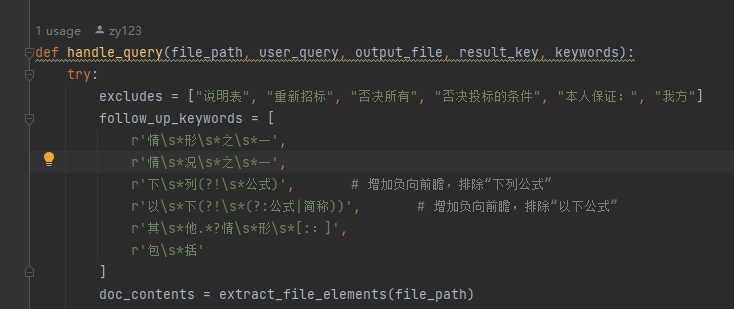
投标人须知正文条款提取成json文件
将截取到的ztbfile_tobidders_notice_part2.pdf ,即须知正文,转为clause1.json 文件,便于后续提取开评定标流程、投标文件要求、重新招标、不再招标和终止招标
这块的主要逻辑就是匹配形如'一、总则'这样的大章节
然后匹配形如'1.1' '1.1.1'这样的序号,由于是按行读取pdf,一个序号后面的内容可能有好几行,因此遇到下一个序号(如'2.1')开头,之前的内容都视为上一个序号的。
old_version
都是废弃文件代码,未在正式、测试环境中使用的,不用管
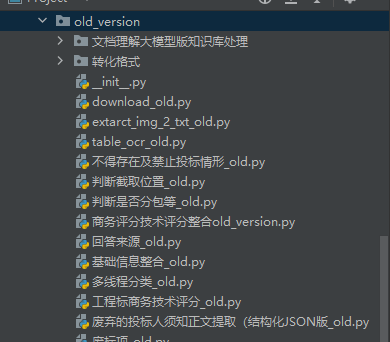
routes
是接口以及主要实现部分,一一对应
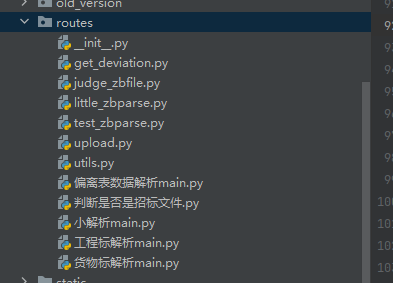
get_deviation对应偏离表数据解析main,获得偏离表数据
judge_zbfile对应判断是否是招标文件
little_zbparse对应小解析main,负责解析extract_info
test_zbparse是测试接口,无对应
upload对应工程标解析和货物标解析,即大解析
混淆澄清:小解析可以指代一个过程,即从'投标文件生成'这个入口进去的解析,后端会同时调用little_zbparse和get_deviation。这个过程称为'小解析'。
但是little_zbparse也叫小解析,命名如此因为最初只需返回这些数据(extract_info),后续才陆续返回商务、技术偏离...
utils是接口这块的公共功能函数。其中validate_and_setup_logger函数对不同的接口请求对应到不同的output文件夹,如upload->output1。后续增加接口也可直接在这里写映射关系。
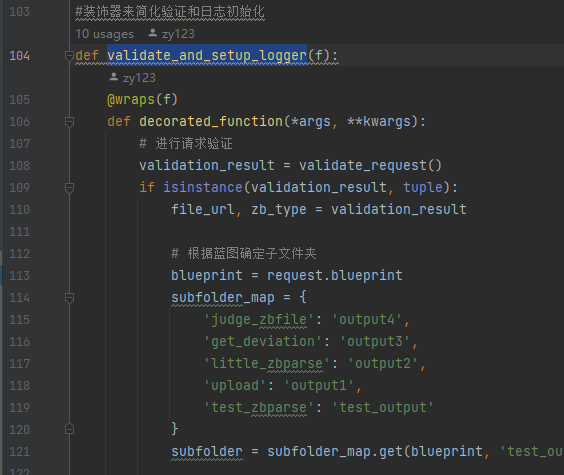
重点关注大解析:upload.py和货物标解析main.py
static
存放解析的输出和提示词
其中output用gitignore了,git push不会推送这块内容。
各个文件夹(output1 output2..)对应不同的接口请求
test_case&testdir
test_case是测试用例,是对一些函数的测试。好久没更新了
testdir是平时写代码的测试的地方
它们都不影响正式和测试环境的解析
工程标&货物标
是两个解析流程中不一样的地方(一样的都写在general中了)
主要是货物标额外解析了采购要求(提取采购需求main+技术参数要求提取+商务服务其他要求提取)
最后:
ConnectionLimiter.py定义了接口超时时间->超时后断开与后端的连接
logger_setup.py 为每个请求创建单独的log,每个log对应一个log.txt
start_up.py是启动脚本,run_serve也是启动脚本,是对start_up.py的简单封装,目前dockerfile定义的直接使用run_serve启动
持续关注
yield sse_format(tech_deviation_response)
yield sse_format(tech_deviation_star_response)
yield sse_format(zigefuhe_deviation_response)
yield sse_format(shangwu_deviation_response)
yield sse_format(shangwu_star_deviation_response)
yield sse_format(proof_materials_response)
- 工程标解析目前仍没有解析采购要求这一块,因此后处理返回的只有'资格审查'和''证明材料"和"extracted_info",没有''商务偏离''及'商务带星偏离',也没有'技术偏离'和'技术带星偏离',而货物标解析是完全版。
其中''证明材料"和"extracted_info"是直接返给后端保存的
- 大解析中返回了技术评分,后端接收后不仅显示给前端,还会返给向,用于生成技术偏离表
- 小解析时,get_deviation.py其实也可以返回技术评分,但是没有返回,因为没人和我对接,暂时注释了。
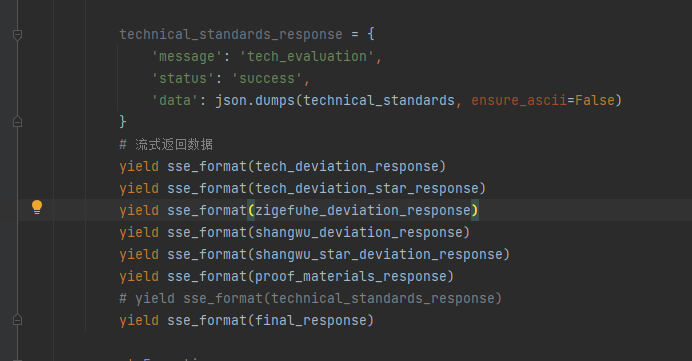
4.商务评议和技术评议偏离表,即评分细则的偏离表,暂时没做,但是商务评分、技术评分无论大解析还是小解析都解析了,稍微对该数据处理一下返回给后端就行。
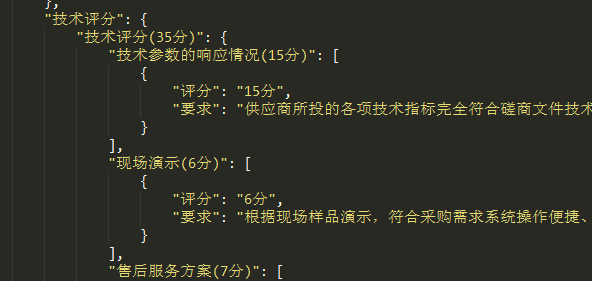
这个是解析得来的结果,适合给前端展示,但是要生成商务技术评议偏离表的话,需要再调一次大模型,对该数据进行重新归纳,以字符串列表为佳。再传给后端。(未做)
如何定位问题
- 查看static下的output文件夹 (upload大解析对应output1)
- docker-compose文件中规定了数据卷挂载的路径:- /home/Z/zbparse_output_dev:/flask_project/flask_app/static/output 也就是说static/output映射到了服务器的Z/zbparse_output_dev文件夹
- 根据时间查找哪个子文件夹(uuid作为子文件名)
- 查看是否有final_result.json文件,如果有,说明解析流程正常结束了,问题可能出在后端(a.后端接口请求超限30分钟 b.后处理存在解析数据的时候出错)
也可能出现在自身解析,可以查看子文件内的log.txt,查看日志。
- 若解析正常(有final_result)但解析不准,可以根据以下定位:
a.查看子文件夹下的文件切分是否准确,例如:如果评标办法不准确,那么查看ztbfile_evaluation_methon,是否正确切到了评分细则。如果切到了,那就改general/商务技术评分提取里的提示词;否则修改截取pdf那块关于'评标办法'的正则表达式。
b.总之是先看切的准不准,再看提示词能否优化,都要定位到对应的代码中!
学习总结
Flask + Waitress :
Flask 和 Waitress 是两个不同层级的工具,在 Python Web 开发中扮演互补角色。它们的协作关系可以概括为:Flask 负责构建 Web 应用逻辑,而 Waitress 作为生产级服务器承载 Flask 应用。
# Flask 开发服务器(仅用于开发)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
# 使用 Waitress 启动(生产环境)
from waitress import serve
serve(app, host='0.0.0.0', port=8080)
Waitress 的工作方式
-
作为 WSGI 服务器:Waitress 作为一个 WSGI 服务器,负责监听指定端口上的网络请求,并将请求传递给 WSGI 应用(如 Flask 应用)。
-
多线程处理:默认情况下,waitress 在单个进程内启用线程池。当请求到达时,waitress 会从线程池中分配一个线程来处理这个请求。由于 GIL 限制,同一时间只有一个线程在执行 Python 代码(只能使用一个核心,CPU利用率只能到100%)。
Flask 与 waitress 的协同工作
- WSGI 接口:Flask 应用实现了 WSGI 接口。waitress 接收到请求后,会调用 Flask 应用对应的视图函数来处理请求,生成响应。
- 请求处理流程
- 请求进入 waitress
- waitress 分配一个线程并调用 Flask 应用
- Flask 根据路由匹配并执行对应的处理函数
- 处理函数返回响应,waitress 将响应发送给客户端
Waitress 的典型使用场景
- 跨平台部署:尤其适合 Windows 环境(Gunicorn 等服务器不支持)。
- 简单配置:无需复杂设置即可获得比开发服务器(Flask自带)更强的性能。
- 中小型应用:对并发要求不极高的场景,Waitress 的轻量级特性优势明显。
Waitress的不足与处理
由于 waitress 是在单进程下工作,所有线程共享进程内存,如果业务逻辑简单且无复杂资源共享问题,这种方式是足够的。
引入子进程:如果需要每个请求实现内存隔离或者绕过 GIL 来利用多核 CPU,有时会在 Flask 视图函数内部启动子进程来处理实际任务。
直接采用多进程部署方案:使用 Gunicorn 的多 worker 模式
Gunicorn
Gunicorn 的工作方式
- 预启动 Worker 进程。Gunicorn 启动时,会按照配置数量(例如 4 个 worker)创建多个 worker 进程。这些 worker 进程会一直运行,并监听同一个端口上的请求。不会针对每个请求单独创建新进程。
- 共享 socket:所有 worker 进程共享同一个监听 socket,当有请求到来时,操作系统会将请求分发给某个空闲的 worker。
推荐worker 数量 = (2 * CPU 核心数) + 1
如何启动:
要使用异步 worker,你需要:
pip install gevent
启动 Gunicorn 时指定 worker 类型和数量,例如:
gunicorn -k gevent -w 4 --max-requests 100 flask_app.start_up:create_app --bind 0.0.0.0:5000
使用 -k gevent(或者 -k eventlet)就可以使用异步 worker,单个 worker 能够处理多个 I/O 密集型请求。
使用--max-requests 100 。每个 worker 在处理完 100 个请求后会自动重启,从而释放可能累积的内存。
本项目的执行流程:
- 调用CPU进行PDF文件的读取与切分,CPU密集型,耗时半分钟
- 针对切分之后的不同部分,分别调用大模型,得到回答,IO密集型,耗时2分钟。
解决方案:
1.使用flask+waitress,waitress会为每个用户请求开新的线程处理,然后我的代码逻辑会在这个线程内开子进程来执行具体的代码,以绕过GIL限制,且正确释放内存资源。
**后续可以开一个共享的进程池代替为每个请求开子进程。以避免高并发下竞争多核导致的频繁CPU切换问题。
2.使用Gunicorn的异步worker,gunicorn为固定创建worker(进程),处理用户请求,一个异步 worker 可以同时处理多个用户请求,因为当一个请求在等待外部响应(例如调用大模型接口)时,worker 可以切换去处理其他请求。
全局解释器锁(GIL):
Python(特别是 CPython 实现)中有一个叫做全局解释器锁(Global Interpreter Lock,简称 GIL)的机制,这个锁确保在任何时刻只有一个线程在执行 Python 字节码。
这意味着,即使你启动了多个线程,它们在执行 Python 代码时实际上是串行执行的,而不是并行利用多核 CPU。
在 Java 中,多线程通常能充分利用多核,因为 Java 的线程是真正的系统级线程,不存在类似 CPython 中的 GIL 限制。
影响:
- CPU密集型任务:由于 GIL 的存在,在 CPU 密集型任务中,多线程往往不能提高性能,因为同时只有一个线程在执行 Python 代码。
- I/O密集型任务:如果任务主要等待 I/O(例如网络、磁盘读写),线程在等待时会释放 GIL,此时多线程可以提高程序的响应性和吞吐量。
NumPy能够在一定程度上绕过 Python 的 GIL 限制。许多 NumPy 的数值计算操作(如矩阵乘法、向量化运算等)是由高度优化的 C 或 Fortran 库(如 BLAS、LAPACK)实现的。这些库通常在执行计算密集型任务时会释放 GIL。C 扩展模块的方式将 C 代码嵌入到 Python 中,从而利用底层 C 库的高性能优势
进程与线程
1、进程是操作系统分配任务的基本单位,进程是python中正在运行的程序;当我们打开了1个浏览器时就是开始了一个浏览器进程; 线程是进程中执行任务的基本单元(执行指令集),一个进程中至少有一个线程、当只有一个线程时,称为主线程 2、线程的创建和销毁耗费资源少,进程的创建和销毁耗费资源多;线程很容易创建,进程不容易创建 3、线程的切换速度快,进程慢 4、一个进程中有多个线程时:线程之间可以进行通信;一个进程中有多个子进程时,进程与进程之间不可以相互通信,如果需要通信时,就必须通过一个中间代理实现,Queue、Pipe。 5、多进程可以利用多核cpu,多线程不可以利用多核cpu 6、一个新的线程很容易被创建,一个新的进程创建需要对父进程进行一次克隆 7、多进程的主要目的是充分使用CPU的多核机制,多线程的主要目的是充分利用某一个单核 ———————————————
每个进程有自己的独立 GIL
多线程适用于 I/O 密集型任务
多进程适用于CPU密集型任务
因此,多进程用于充分利用多核,进程内开多线程以充分利用单核。
进程池
multiprocessing.Pool库:,通过 maxtasksperchild 指定每个子进程在退出前最多执行的任务数,这有助于防止某些任务中可能存在的内存泄漏问题
pool =Pool(processes=10, maxtasksperchild=3)
concurrent.futures.ProcessPoolExecutor更高级、更统一,没有类似 maxtasksperchild 的参数,意味着进程在整个执行期内会一直存活,适合任务本身比较稳定的场景。
pool =ProcessPoolExecutor(max_workers=10)
最好创建的进程数等同于CPU核心数,如果大于,且每个进程都是CPU密集型(高负债一直用到CPU),那么进程之间会竞争CPU,导致上下文切换增加,反而会降低性质。
设置的工作进程数接近 CPU 核心数,以便每个进程能独占一个核运行。
进程、线程间通信
线程间通信:
- 线程之间可以直接共享全局变量、对象或数据结构,不需要额外的序列化过程,但这也带来了同步的复杂性(如竞态条件)。
import threading
num=0
def work():
global num
for i in range(1000000):
num+=1
print('work',num)
def work1():
global num
for i in range(1000000):
num+=1
print('work1',num)
if __name__ == '__main__':
t1=threading.Thread(target=work)
t2=threading.Thread(target=work1)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程执行结果',num)
运行结果:
work 1551626
work1 1615783
主线程执行结果 1615783
这些数值都小于预期的 2000000,因为:
即使存在 GIL,num += 1 这样的操作实际上并不是原子的。GIL 确保同一时刻只有一个线程执行 Python 字节码,但在执行 num += 1 时,实际上会发生下面几步操作:
- 从内存中读取
num的当前值 - 对读取到的值进行加 1 操作
- 将新的值写回到内存
由多个字节码组成!!!
因此会导致:
线程 A 读取到 num 的值
切换到线程 B,线程 B 也读取同样的 num 值并进行加 1,然后写回
当线程 A 恢复时,它依然基于之前读取的旧值进行加 1,最后写回,从而覆盖了线程 B 的更新
解决:
from threading import Lock
import threading
num=0
def work():
global num
for i in range(1000000):
with lock:
num+=1
print('work',num)
def work1():
global num
for i in range(1000000):
with lock:
num+=1
print('work1',num)
if __name__ == '__main__':
lock=Lock()
t1=threading.Thread(target=work)
t2=threading.Thread(target=work1)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程执行结果',num)
进程间通信(IPC):
- 进程之间默认不共享内存,因此如果需要传递数据,就必须使用专门的通信机制。
- 在 Python 中,可以使用
multiprocessing.Queue、multiprocessing.Pipe、共享内存(如multiprocessing.Value和multiprocessing.Array)等方式实现进程间通信。
from multiprocessing import Process, Queue
def worker(process_id, q):
# 每个进程将数据放入队列
q.put(f"data_from_process_{process_id}")
print(f"Process {process_id} finished.")
if __name__ == '__main__':
q = Queue()
processes = []
for i in range(5):
p = Process(target=worker, args=(i, q))
processes.append(p)
p.start()
for p in processes:
p.join()
# 从队列中收集数据
results = []
while not q.empty():
results.append(q.get())
print("Collected data:", results)
-
当你在主进程中创建了一个
Queue对象,然后将它作为参数传递给子进程时,子进程会获得一个能够与主进程通信的“句柄”。 -
子进程中的
q.put(...)操作会将数据通过这个管道传送到主进程,而主进程可以通过q.get()来获取这些数据。 -
这种机制虽然看起来像是“共享”,但实际上是通过 IPC(进程间通信)实现的,而不是直接共享内存中的变量。
项目贡献
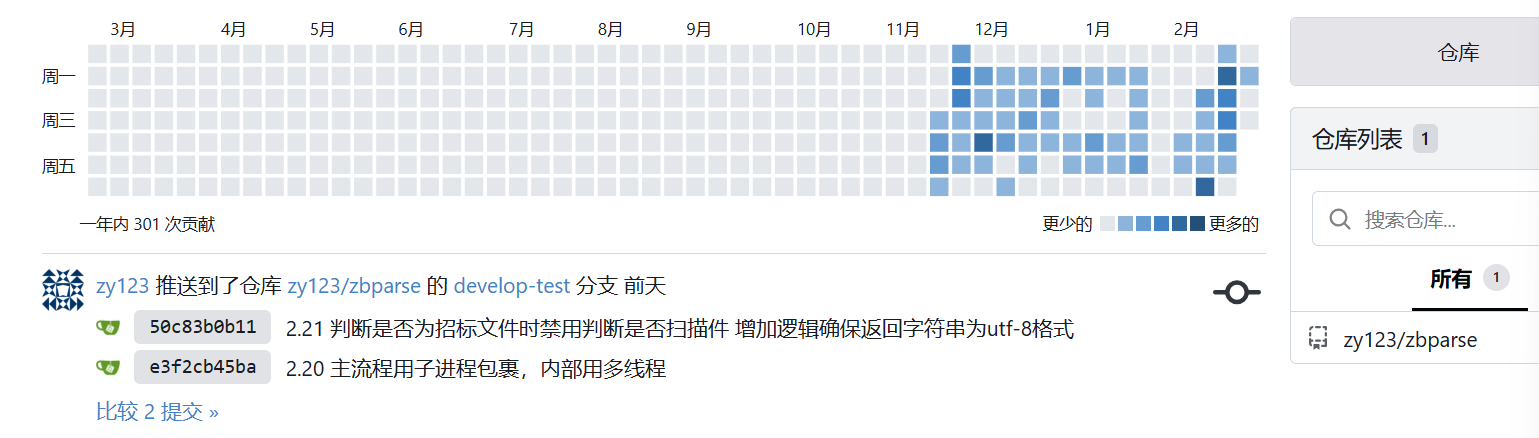
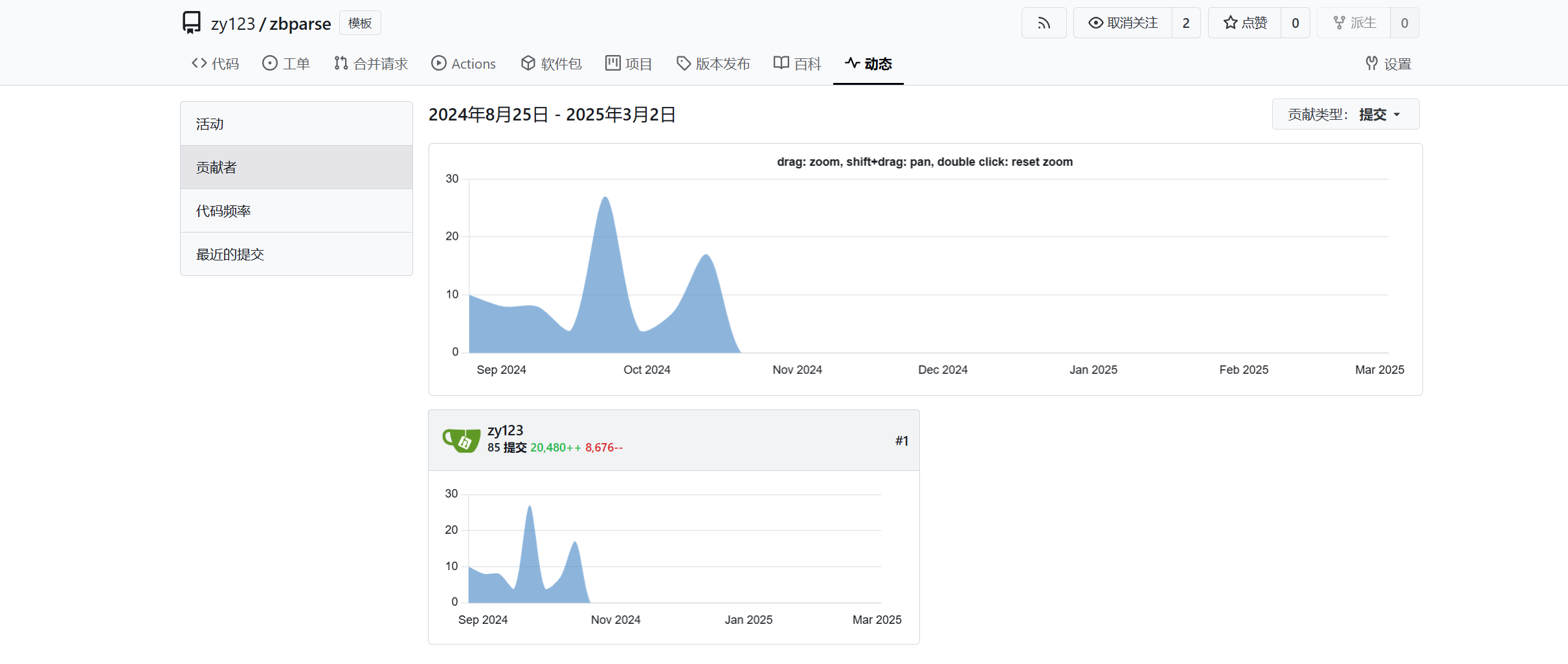
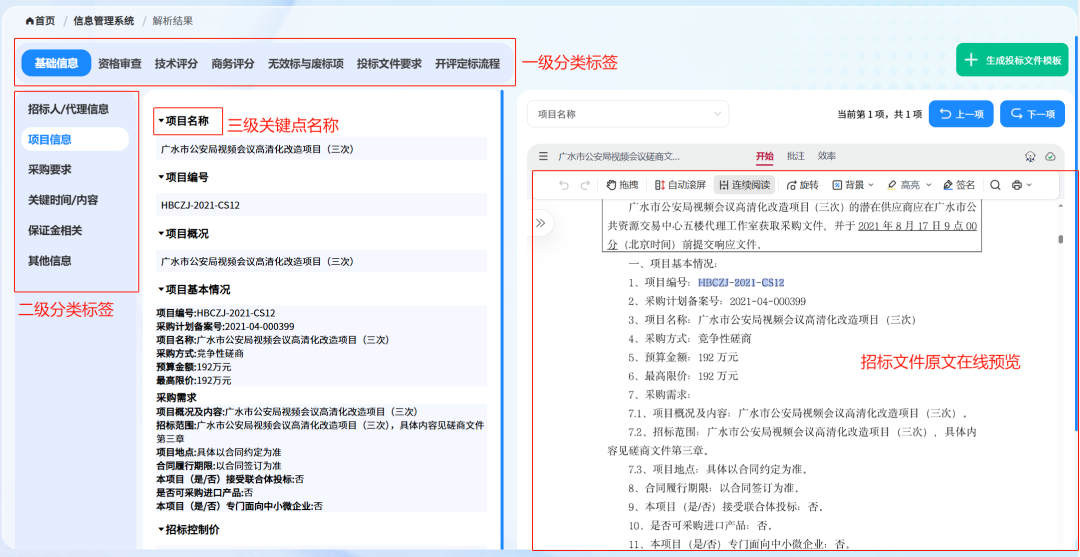
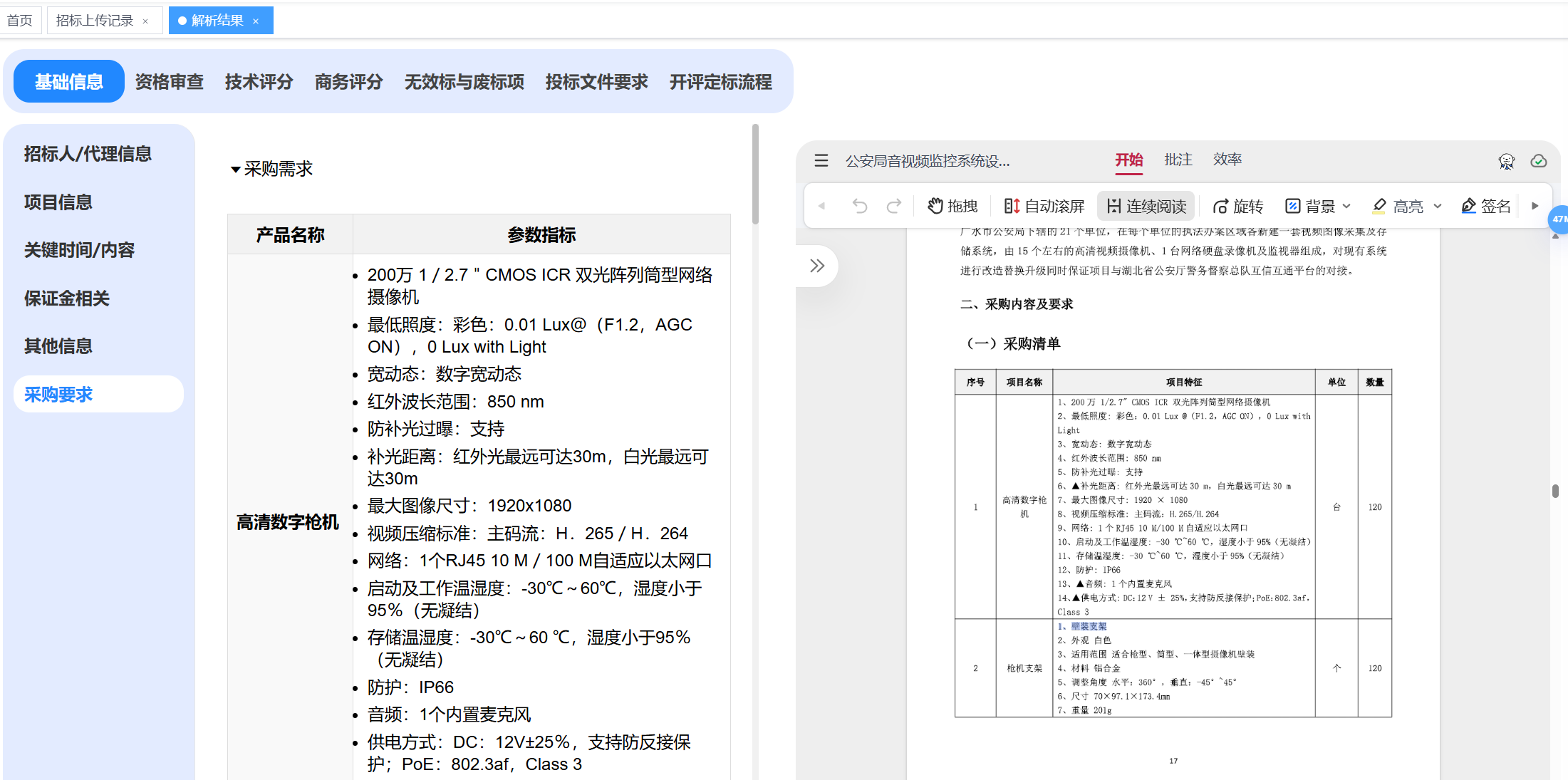
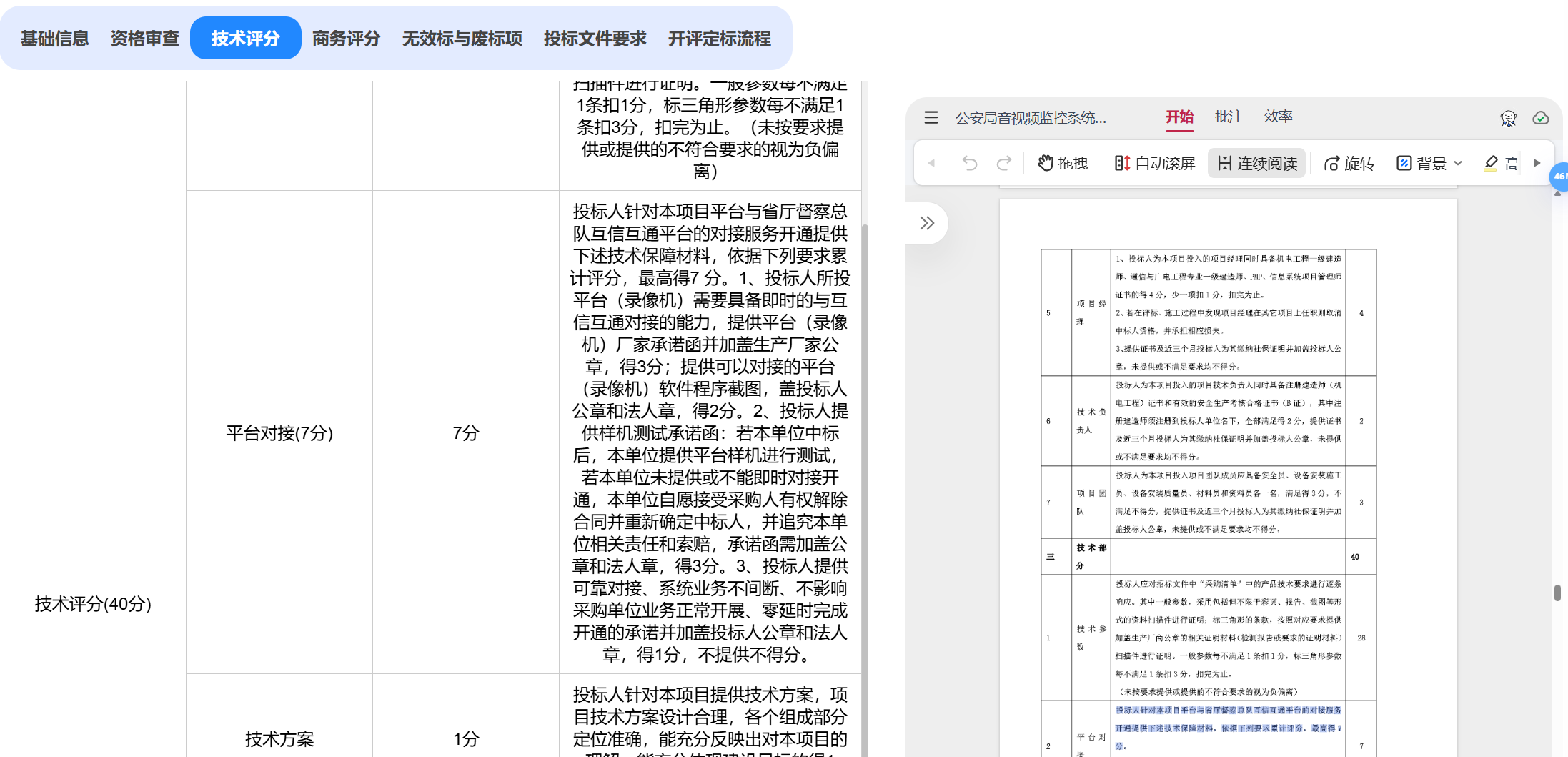
效果图